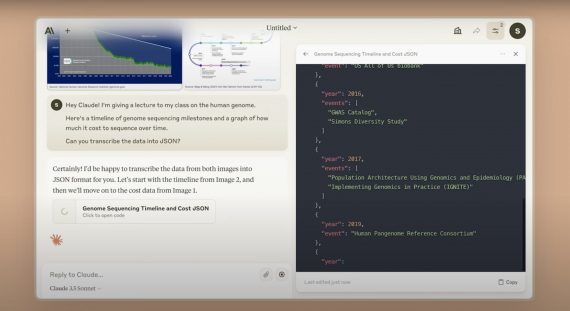
ReLoRA — метод обучения больших языковых моделей-трансформеров с использованием матриц низкого ранга, который увеличивает производительность обучения. Эффективность метода возрастает с увеличением масштабов моделей. На модели с 1,3 миллиардами параметров использование памяти уменьшилось на 30%, а производительности обучения увеличилось на 52% по сравнению с обучением с полным рангом. Код доступен в открытом доступе на Github.
Подробнее о методе
Основная идея, лежащая в основе ReLoRA, заключается в разложении обновлений весов во время обучения на матрицы низкого ранга путем добавления новых обучаемых параметров к исходным весам модели. ReLoRA превзошла базовые методы обучения с низким рангом, такие как LoRA, на всех размерах моделей.
ReLoRA использует несколько дополнительных техник во время обучения, чтобы увеличить эффективный ранг обновлений модели:
Перезапуски обучения: После обучения матриц низкого ранга в течение нескольких шагов, ReLoRA объединяет низкоранговые факторы обратно с исходными весами модели. Это позволяет последующим низкоранговым факторам захватывать различные компоненты обновления весов.
Сбросы оптимизатора: При повторном запуске обучения ReLoRA сбрасывает часть состояний оптимизатора Adam. Это предотвращает смещение новых низкоранговых факторов в сторону предыдущего пространства решений.
Ступенчатое нарастание скорости обучения: При каждом перезапуске скорость обучения сбрасывается до нуля и плавно нарастает. Это стабилизирует процесс интеграции новых низкоранговых факторов в модель. Ключевая идея заключается в том, что каждый этап обучения низкого ранга будет ограничен низкомерным подпространством. Путем проведения нескольких перезапусков общее обновление модели на протяжении нескольких циклов может иметь более высокий ранг, чем любое отдельное обновление.
Это позволяет ReLoRA выполнять обновления высокого ранга, одновременно обучая лишь небольшое количество параметров.
Результаты ReLoRA
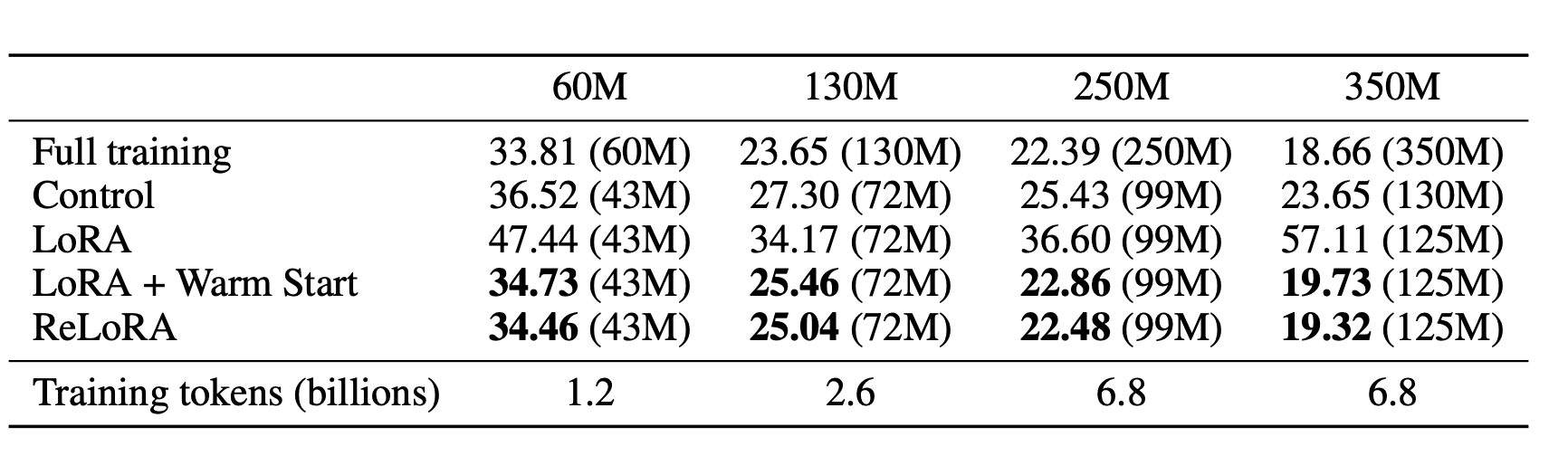
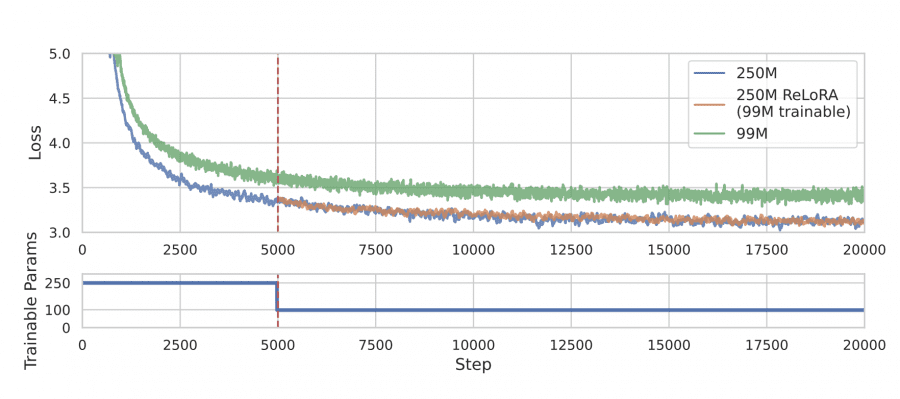
Авторы оценили эффективность ReLoRA, предварительно обучив языковые модели трансформеров с до 350 миллионами параметров на датасете C4. Результаты показали, что ReLoRA достигла сравнимой перплексии с обычным полноранговым обучением трансформеров, и её эффективность улучшается с увеличением размера модели. Например, для модели с 350 миллионами параметров ReLoRA уменьшила количество обучаемых параметров на более чем 70%, сохраняя при этом конкурентоспособную перплексию: 22,48 против 20,40 соответсвенно.
Эффективность метода существенно возрастает с увеличением размера модели. На модели с 350 миллионами параметров ReLoRA требовала всего 99 миллионов обучаемых параметров, что уменьшило количество обучаемых параметров на 70%.
Анализ сингулярных значений обновлений весов показал, что ReLoRA качественно лучше аппроксимирует обновления с более высоким рангом при обучении с полным рангом, чем стандартные методы обучения с низким рангом, такие как LoRA. Это указывает на то, что ReLoRA способна выполнять обновления модели высокого ранга с помощью обучения с низким рангом.
Разрыв в производительности между ReLoRA и обучением с полным рангом уменьшился с увеличением размеров моделей. Например, на модели с 60 миллионами параметров разрыв составлял более 5 пунктов перплексии, в то время как на модели с 350 миллионами параметров он уменьшился до менее чем 2 пунктов перплексии.
Улучшения использования памяти и вычислительной эффективности существенно возрасли при оценке на модели с 1,3 миллиарда параметров. Оценки показали уменьшение использования памяти на 30% и повышение производительности обучения на 52% по сравнению с обучением с полным рангом.
Заключение
ReLoRA демонстрирует потенциал техник обучения низкого ранга для предварительного обучения больших языковых моделей. По мере приближения размеров моделей к триллиону параметров такие методы, как ReLoRA, способные уменьшить вычислительные затраты, станут важны для доступности к обучению нейронных сетей. Повышающаяся эффективность ReLoRA с увеличением масштаба делает её многообещающим подходом на будущее.