Claude Sonnet 5: сильный агентный апгрейд, но не очевидная замена Opus
1 июля 2026

Claude Sonnet 5: сильный агентный апгрейд, но не очевидная замена Opus
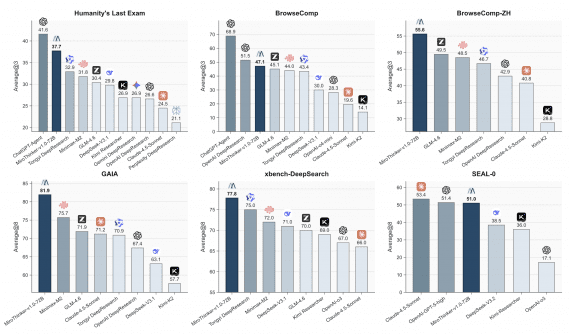
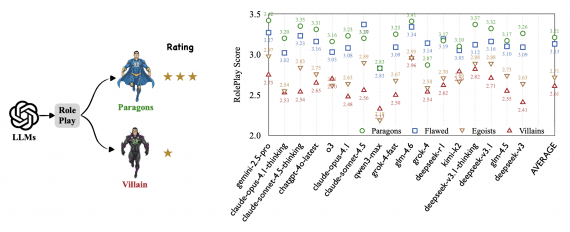
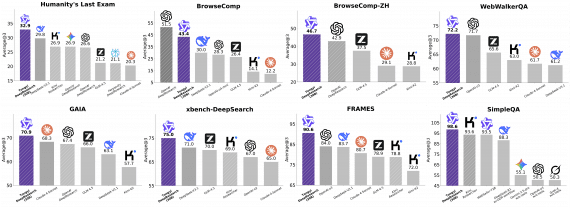
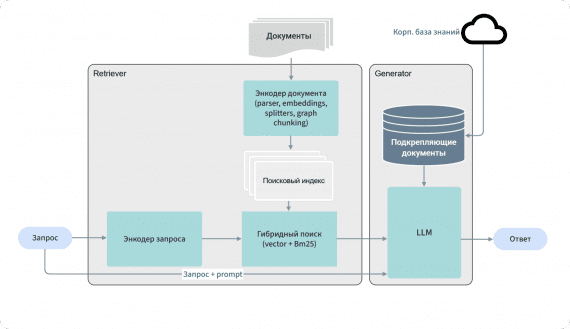
Anthropic представила Claude Sonnet 5 — новую модель из линейки Claude, доступную в том числе пользователям бесплатного тарифа. Она ориентирована на агентные задачи, программирование, работу с инструментами и корпоративную автоматизацию.…