ClawGUI: первый открытый фреймворк полного цикла для GUI-агентов от обучения до реального устройства
15 апреля 2026

ClawGUI: первый открытый фреймворк полного цикла для GUI-агентов от обучения до реального устройства
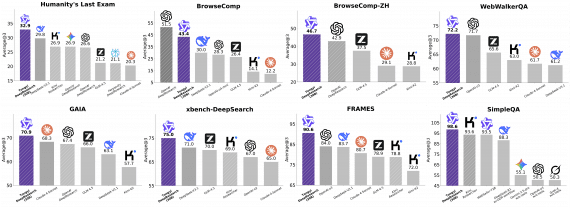
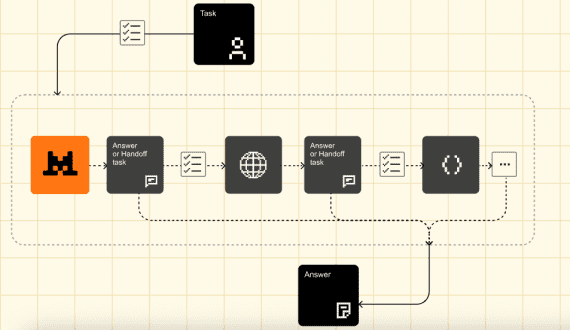
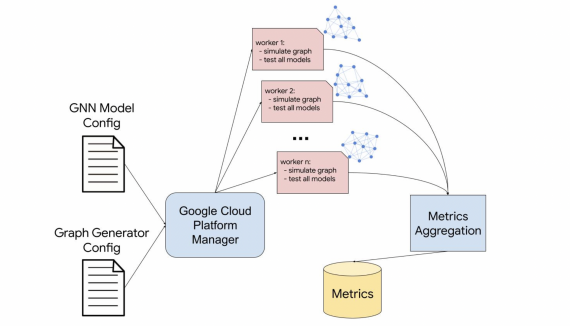
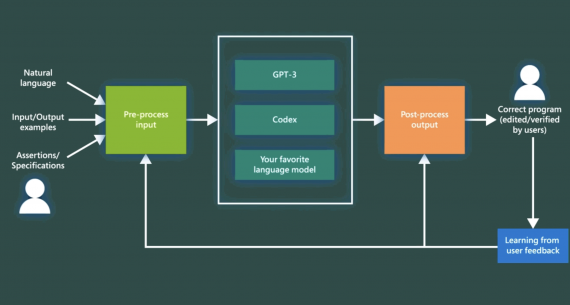
Исследователи из Чжэцзянского университета опубликовали ClawGUI — полностью открытый фреймворк для разработки GUI-агентов, которые управляют приложениями через визуальный интерфейс, как это делает человек: касаниями, свайпами и вводом текста. На практике…