
GigaGAN – an open source model with 1 billion parameters, can generate 512×512 pixel images in just 0.13 seconds, significantly faster than diffuse and autoregressive models. Additionally, researchers have developed a fast upsampler, capable of creating 4K images from low-resolution text-to-image model outputs. GigaGAN also achieves a lower FID metric (the lower, the better) compared to Stable Diffusion v1.5 and DALL·E 2 models.
The success of diffuse models has led to a rapid shift in the preferred architecture for generative image models. While GANs with techniques like StyleGAN were the standard choice before, the emergence of DALL·E 2 suddenly made autoregressive and diffuse models the new norm. This swift transition raises a fundamental question: can GANs be scaled to train on large datasets like LAION?
Researchers from Carnegie Mellon Institute and Adobe Research found that simple scaling of StyleGAN architecture quickly leads to instability. They designed GigaGAN, a new GAN architecture, demonstrating that GANs can be a viable option for the task of generating images from text.
Three key advantages of GigaGAN:
- It is orders of magnitude faster than diffuse models, requiring only 0.13 seconds to synthesize a 512-pixel image.
- The model quickly generates Hi-Res images, such as 16-megapixel images in just 3.66 seconds.
- Finally, GigaGAN supports latent space manipulation techniques like latent interpolation, style mixing, and vector operations.
Architecture of GigaGAN
Generator
The GigaGAN generator consists of a text encoding network, a style map network, a multi-scale synthesis network, an attention mechanism, and adaptive convolution kernel selection:
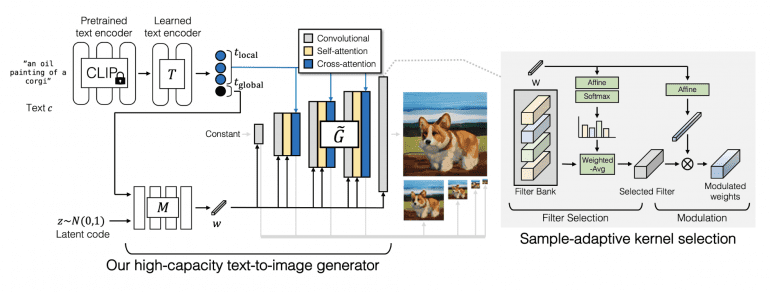
In the text encoding network, they first extract text embeddings using the pretrained CLIP model and trained attention layers T. Then, the embedding is passed into the style map network M to create a style vector w, similar to the StyleGAN model. The synthesis network then uses the code as modulation and text embeddings as attention to create a pyramid of images. Adaptive kernel selection allows for the adaptation of convolution kernel selection based on the input text description.
Discriminator
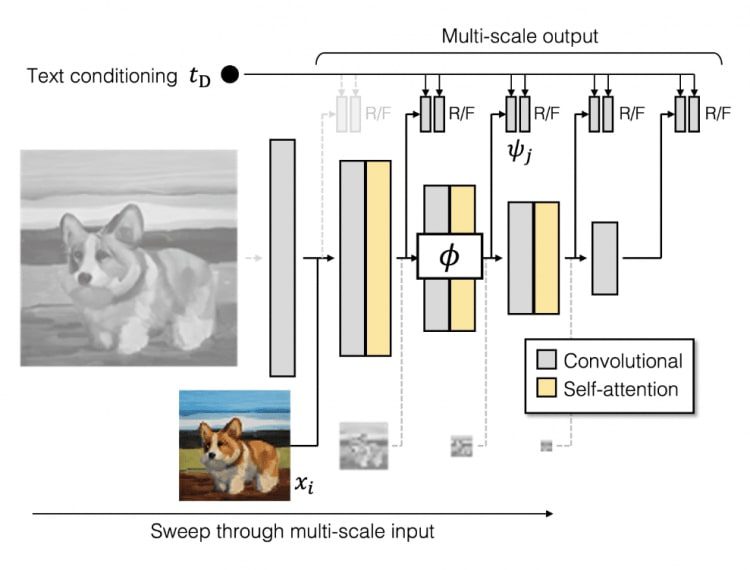
The GigaGAN discriminator, like the generator, consists of two networks for processing images and text descriptions. The text description branch processes text similarly to the generator. The image processing network receives an image pyramid and makes independent predictions for each image scale. Furthermore, predictions are made at all subsequent downsampled layers. Additional loss functions are used to ensure efficient convergence.
GigaGAN Results
Comparing with recent text-to-image models, GigaGAN achieves a lower FID score than DALL·E 2, Stable Diffusion, and Parti-750M, while significantly outperforming competing methods in terms of speed.
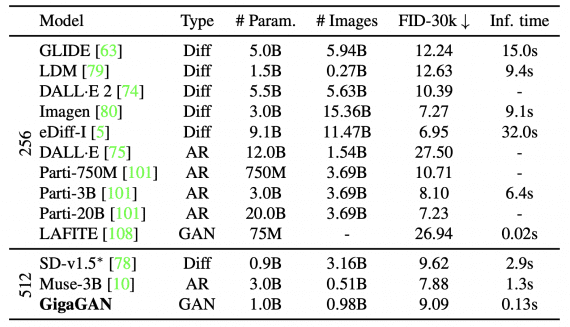
Notably, GigaGAN and SD-v1.5 require 4,783 and 6,250 GPU-days of A100 training, while Imagen and Parti require approximately 4,755 and 320 days of TPUv4 processor work.










GigaGAN is closed source, no one has officially published the code of the original model. There is only a replication, and it is not finished yet and it is not… Read more »