
The performance of the most facial analysis techniques relies on the resolution of the corresponding image. Face alignment or face identification is not going to work correctly when the resolution of a face is adversely low.
What’s Face Super-Resolution?
Face super-resolution (FSR) or face hallucination, provides a viable way to recover a high-resolution (HR) face image from its low-resolution (LR) counterpart. This research area has attracted increasing interest in the recent years, and the most advanced deep learning methods achieve state-of-the-art performance in face super-resolution.
However, even these methods often produce the results with the distorted face structure and only partially recovered facial details. Deep learning based FSR methods fail to super-resolve LR faces under large pose variations.
How can we solve this problem?
- Augmenting training data with large pose variations still leads to suboptimal results where facial details are missing or distorted.
- Directly detecting facial components or landmarks in LR faces is also suboptimal and may lead to ghosting artifacts in the final result.
But what about a method that super-resolves LR faces images while collaboratively predicting face structure? Can we use heatmaps to represent the probability of the appearance of each facial component?
We are going to discover this very soon, but let’s first check the previous approaches to the problem of face super-resolution.
Related Work
Face hallucination methods can be roughly grouped into three categories:
- ‘Global model’ based approaches aim at super-resolving an LR input image by learning a holistic appearance mapping such as PCA. For instance, Wang and Tang reconstruct an HR output from the PCA coefficients of the LR input; Liu et al. develop a Markov random field (MRF) to reduce ghosting artifacts caused by the misalignments in LR images; Kolouri and Rohde employ optimal transport techniques to morph an HR output by interpolating exemplary HR faces.
- Part based methods are proposed to super-resolve individual facial regions separately. For instance, Tappen and Liu super-resolve HR facial components by warping the reference HR images; Yang et al. localize facial components in the LR images by a facial landmark detector and then reconstruct missing high-frequency details from similar HR reference components.
- Deep learning techniques can be very different: Xu et al. employ the framework of generative adversarial networks to recover blurry LR face images; Zhu et al. present a cascade bi-network, dubbed CBN, to localize LR facial components first and then upsample the facial components.
State-of-the-art-idea
Xin Yu and his colleagues propose a multi-task deep neural network that not only super-resolves LR images but also estimates the spatial positions of their facial components. Their convolutional neural network (CNN) has two branches: one for super-resolving face images and the other – for predicting salient regions of a face coined facial component heatmaps.
The whole process looks like this:
- Super-resolving features of input LR images.
- Employing a spatial transformer network to align the feature maps.
- Estimating the heatmaps of facial components with the upsampled feature maps.
- Concatenating estimated heatmaps of facial components with the upsampled feature maps.
This method can super-resolve tiny unaligned face images (16 x 16 pixels) with the upscaling factor of 8x while preserving face structure.

Now let’s learn the details of the proposed method.
Model overview
The network has the following structure:
- A multi-task upsampling network (MTUN):
- an upsampling branch (composed of a convolutional autoencoder, deconvolutional layers, and a spatial transformer network);
- a facial component heatmap estimation branch (HEB).
- Discriminative network, which is constructed by convolutional layers and fully connected layers.
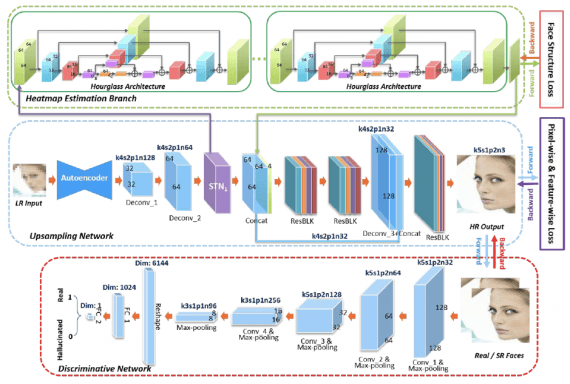
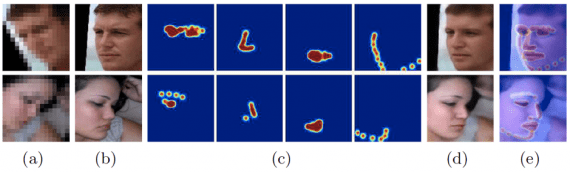
Facial Component Heatmap Estimation. Even the state-of-the-art facial landmark detectors cannot accurately localize facial landmarks in very low-resolution images. So, the researchers propose to predict facial component heatmaps from super-resolved feature maps.
2D photos may exhibit a wide range of poses. Thus, to reduce the number of training images required for learning HEB, they suggest employing a spatial transformer network (STN) to align the upsampled features before estimating heatmaps.
In total, four heatmaps are estimated to represent four components of a face: eyes, nose, mouth, and chain (see the image below).
Loss Function. The results of using different combinations of losses are provided below:

On the above image:
- unaligned LR image,
- original HR image,
- pixel-wise loss only,
- pixel-wise and feature-wise losses combined,
- pixel-wise, feature-wise, and discriminative losses,
- pixel-wise and face structure losses,
- pixel-wise, feature-wise, and face structure losses,
- pixel-wise, feature-wise, discriminative, and face structure losses.
In training their multi-task upsampling network, the researchers have selected to use the last option (h).
Qualitative and Quantitative Comparisons
See the qualitative comparison of the suggested approach with the state-of-the-art methods:

As you can see, most of the existing methods fail to generate realistic face details, while the suggested approach outputs realistic and detailed images, which are very close to the original HR image.
Quantitative comparison with the state-of-the-art methods leads us to the same conclusions. All methods were evaluated on the entire test dataset by the average PSNR and the structural similarity (SSIM) scores.

The results in the table show that the approach presented here outperforms the second best with a large margin of 1.75 dB in PSNR. This confirms that estimating heatmaps helps in localizing facial components and aligning LR faces more accurately.
Bottom Line
Let’s summarize the contributions of this work:
- It presents a novel multi-task upsampling network that can super-resolve very small LR face images (16 x 16 pixels) by an upscaling factor of 8x.
- The method not only exploits image intensity similarity but also estimates the face structure with the help of facial component heatmaps.
- The estimated facial component heatmaps provide not only spatial information of facial components but also their visibility information.
- Thanks to the aligning of feature maps before heatmap estimation, the number of images required for training the model is largely reduced.
The method is good at super-resolving very low-resolution faces in different poses and generates realistic and detailed images free from distortions and artifacts.









