Generative Models are drawing a lot of attention within the Machine Learning research community. This kind of models has practical applications in different domains. Two of the most commonly used and efficient approaches recently are Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN).

While vanilla autoencoders can learn to generate compact representations and reconstruct their inputs well, they are pretty limited when it comes to practical applications. The fundamental problem of the standard autoencoders is that the latent space (in which they encode the input data distribution) may not be continuous therefore may not allow smooth interpolation. A different type of autoencoders called Variational Autoencoders (VAEs) can solve this problem, and their latent spaces are, by design, continuous, allowing easy random sampling and interpolation. This allowed VAEs to become very popular and used for many different tasks, especially in Computer Vision.
However, controlling and understanding deep neural networks, especially deep autoencoders is a difficult task and being able to control what the networks are learning is of crucial importance.
Previous works
The problem of feature disentanglement has been explored in the literature, for image and video processing and text analysis. Disentangling factors of variation are necessary for the goal of controlling and understanding deep networks and many attempts have been made to solve this problem.
Past work has explored the separation of the latent image representations into dimensions that account for different factors of variation. For example identity, illumination and spatial support, then low-dimensional transformations, such as rotations, translation, or scaling or more descriptive levels of variation such as age, gender, wearing glasses.
State-of-the-art idea
Recently, Zhixin Shu et al. introduced Deforming Autoencoders or shortly DAEs – a generative model for images that disentangles shape from the appearance in an unsupervised manner. In their paper, researchers propose a way to disentangle shape and appearance by assuming that object instances are obtained by deforming a prototypical object or ‘template’. This means that the object’s variability can be separated into variations associated with spatial transformations linked to the object’s shape, and variations that are associated with appearance. As simple as the idea sounds, this kind of disentanglement using deep autoencoders and unsupervised learning proved to be quite powerful.
Method
The proposed method can disentangle shape and appearance as factors of variation in a learned lower-dimensional latent space. The technique employs a deep learning architecture comprising of an encoder network that encodes the input image into two latent vectors (one for each shape and appearance) and two decoder networks taking the latent vectors as input and outputting generated texture and deformation, respectively.
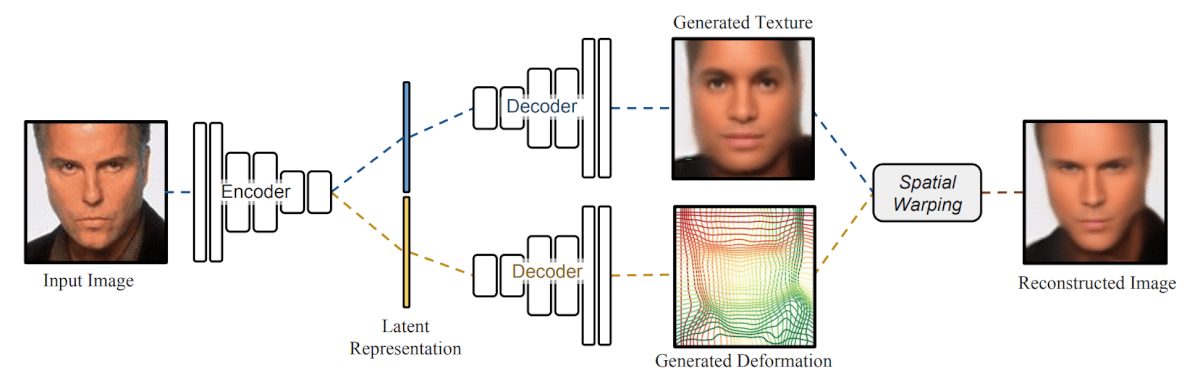
Independent decoder networks learn the appearance and deformation functions. The generated spatial deformation is used to warp the texture to the observed image coordinates. In this way, the Deforming Autoencoder can reconstruct the input image and at the same time disentangle the shape and appearance as different features. The whole architecture is trained in an unsupervised manner using only simple image reconstruction loss.
In addition to Deforming Autoencoders (DAEs), the researchers propose Class-aware Deforming Autoencoders, which learn to reconstruct an image while at the same time disentangle the shape and appearance factors of variation conditioned by the class. To make this possible, they introduce a classifier network that takes a latent vector (third latent vector used to encode the class, besides the latent vectors for shape and appearance). This kind of architecture allows learning a mixture model conditioned on the class of the input image (rather than a joint multi-modal distribution).
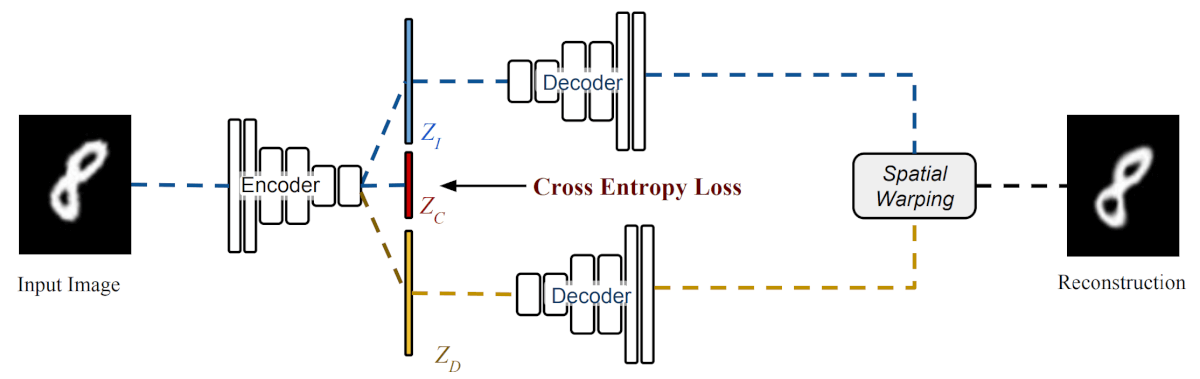
They show that introducing class-aware learning drastically improves the performance and stability of the training. Intuitively, this can be explained as the network learning to separate the spatial deformation that is different among different classes.
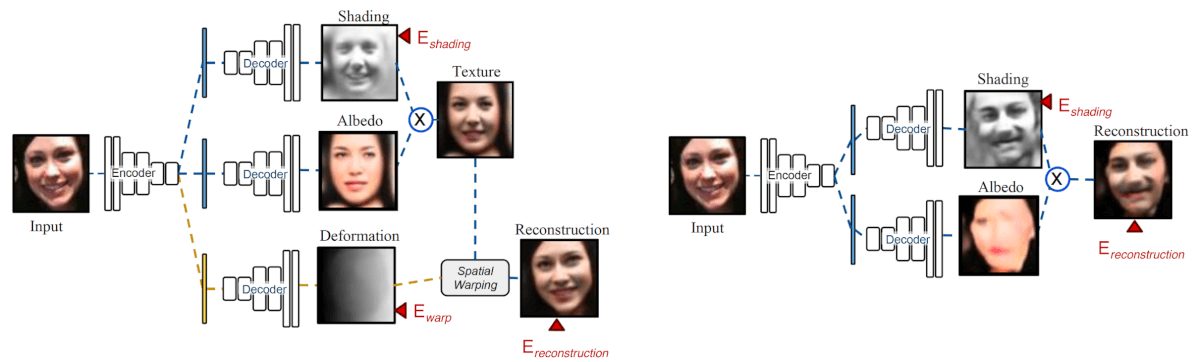
Also, the researchers propose a Deforming Autoencoder to learn to disentangle albedo and shading (a widespread problem in computer vision) from facial images. They call this architecture Intrinsic Deforming Autoencoder, and it is shown in the picture below.
Results
It is shown that this method can successfully disentangle shape and appearance while learning to reconstruct an input image in an unsupervised manner. They show that class-aware Deforming Autoencoders provide better results in both reconstruction and appearance learning.

Besides the qualitative evaluation, the proposed Deforming Autoencoder architecture is evaluated quantitatively concerning landmark localization accuracy. The method was evaluated on
- unsupervised image alignment/appearance inference;
- learning semantically meaningful manifolds for shape and appearance;
- unsupervised intrinsic decomposition
- unsupervised landmark detection.



Watch the video:
Comparison with other state-of-the-art
The proposed method was evaluated on the MAFL test – mean error on unsupervised landmark detection. It outperforms the self-supervised approach proposed by Thewlis et al.

Conclusion

As I mentioned previously, being able to disentangle factors of variation can be of crucial importance for many tasks. Disentanglement allows complete control and understanding of deep neural network models, and it may be a key to solving problems. This approach introduced Deforming Autoencoders as a specific architecture able to disentangle particular factors of variation (in this case shape and appearance). The results show that this method can successfully disentangle the factors of variability by employing an autoencoder architecture.