It is a common and good practice among DJs to create and divide playlists by mood (aggressive, soulful, melancholy) and energy (slow, medium, fast) rather than by music genre. In this way, the DJ is making a trade-off between the smooth, clean transition between tracks and his/her performance in terms of creating a natural mix of tracks that expresses a specific style and brings its own energy. Good DJs are able to provide a seamless and perceptually smooth transition between two tracks, thus making a mix of different tracks sound like a single flowing one.
Maybe one of the most difficult tasks that DJs face is smooth transitioning between songs from a different genre. As I mentioned before, this is necessary in order to create a playlist that will express a certain mood or emotion rather than just creating a list of same-genre songs carrying no energy altogether.
Recent work in machine learning (or more specifically deep learning), has given some answers and has provided useful methods for solving the problem of smooth transitioning between tracks of a different genre. In fact, Tijn Borghuis et al., propose a generative method that generates drum patterns which can be used to seamlessly transition different-genre tracks in the electronic dance music domain.
How it Works
The method is based on deep learning, utilizing Variational Autoencoders (VAEs) and interpolation in the latent space. The music data representation, the architecture, as well as the interpolation and the whole method, are explained below.
The authors created a dataset of drum patterns of three popular electronic music genres: Electro, Techno and Intelligent Dance Music (IDM) ending up with 1–1.5 hours of music for each of the three genres to be used for their method. The dataset, in the end, consisted of 1782 drum patterns. Each pattern is represented as a two-dimensional array whose y-axis represents the 6 drum instruments and the x-axis represents the time. Each pattern is given as a 6 x 64 array since all the generated patterns have a length of 64.

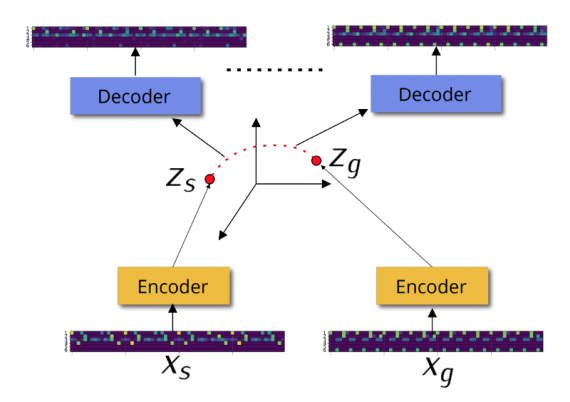
The proposed method is taking two music patterns (each one represented as a 6×64 array), it encodes them using an encoder from a learned VAE model, then it interpolates between the latent representations of the two patterns and then decodes both patterns to give smooth transition patterns as output.
The idea behind the proposed method is that interpolation in latent space will provide far better results than interpolation in the pattern (feature) space. But, one might ask what is the reasoning behind this statement. Is it always true? It turns out, it actually is and the answer lies in the theory of deep learning. Interpolating in the latent space works better because of the non-linear mappings from the input to the latent space and from the latent space to the output. In the context of this work, generating a weighted average of two patterns would give the well-known crossfading (gradually lowering the volume of one track while increasing the volume of the other track). It is basically, interpolating in the representation space that is just a linear combination.
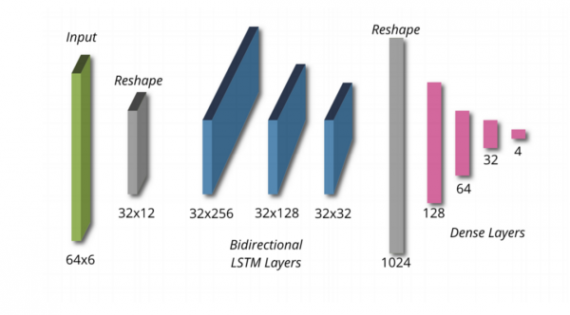
The encoder of the Variational Autoencoder described in the paper has three main parts: the input, the recurrent layers which are bi-directional LSTM layers including tanh nonlinearities and fully-connected layers which map the input into a latent representation — a vector of size 4. The decoder, on the other hand, consists only of dense (fully-connected) upsampling layers outputting a reconstruction of the same shape (6×64). The fully-connected layers in the decoder are followed by a ReLU non-linear activation.
This kind of architecture proved to work well enough in the task of generating new music patterns used for transitioning between tracks or for autonomous drumming.
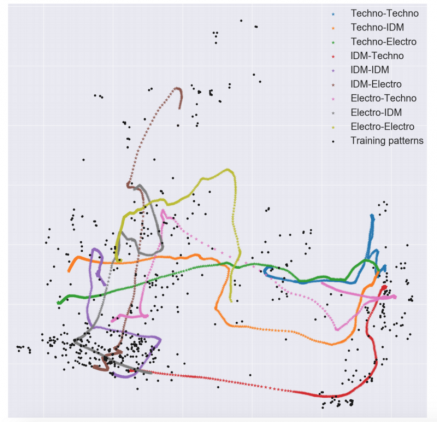
An interesting experiment was done by the authors trying to understand the originality of the generated patterns. They did Principal Component Analysis (PCA) on all of the training patterns plus the generated patterns through interpolation.
They visualize the patterns (both the training and the generated ones) in the space of the first two principal components (which usually preserve a large amount of the variance).
The conclusion is that the interpolation trajectories (the coloured lines in the plot) tend to follow the distribution of the training patterns while including new data points. These data points are the generated patterns that are actually genuinely new and original.
What About The Music?
Well, the authors show that deep learning and especially generative models have enormous potential in the field of music production. From the conducted experiments, they show that their method, as well as deep learning in general, can be efficiently employed in the process of producing music patterns. Moreover, it can support the creation of music flow by generating patterns for transitioning between songs, even from a different genre. They proved that the newly generated patterns are musically appealing and original. Taking into account the speed at which AI is developed and advancing we can conclude that it is just a matter of time when AI will be capable of producing pleasing music even without any human intervention.







