
Due to the particle-scattered light, images taken in a foggy weather are likely to include shifted colors, attenuated saturation and decreased contrast. Such factors have a significant adverse effect on the performance of many high-level computer vision tasks such as object recognition and classification, aerial photography, autonomous driving, remote sensing and others.
However, single image haze removal is a very challenging task since a single hazy image lacks a lot of information, including scene structure and clean scene, whereas one is needed to infer the other. To compensate for this deficiency, existing solutions rely mainly on handcrafted priors: local depth is often assumed as well as one or more color priors. This approach generally works well, but it can easily become unworkable with images that violate its assumptions by including, for example, bright surface or colored haze. In such cases, the restored image tends to be over-saturated and has incorrect tone.

Figure 1. Mount Baker in different weather: clean image and two different illumination colors
The problem is, in fact, unsolvable based on the insufficient low-level information alone. However, it can be noticed that humans can easily tell the naturalness of color — whether the tree is too green, or the sky is too blue. People get such understanding because of the semantic prior that they as humans have knowledge about.
The semantic approach towards image “dehazing”
Researchers from Australian National University, namely Ziang Cheng, Shaodi You, Viorela Ila, and Hongdong Li, suggest using the similar approach and incorporating semantic features into the haze removal model.
In fact, they propose a fully end-to-end convolutional neural network (CNN) that learns the correlation between semantics and objects’ natural color from training samples and infer the clean scene and illumination color based on learned semantic features. So, if the color of the particular object is known with high confidence (e.g., the sky is blue, plants are green), the semantics learned from training examples, provide very good informative cues on the object’s true color.
Moreover, the clean scene and ambient illumination can be inferred with high confidence. Then, if other objects from the image have colors that cannot be predicted with high confidence based on the semantic features (e.g., cars, buildings can be of different colors), the true color can be anticipated with, for example, low-level priors and ambient illumination as estimated from other strongly confident objects. The illustration of the suggested approach is provided in the figure below.
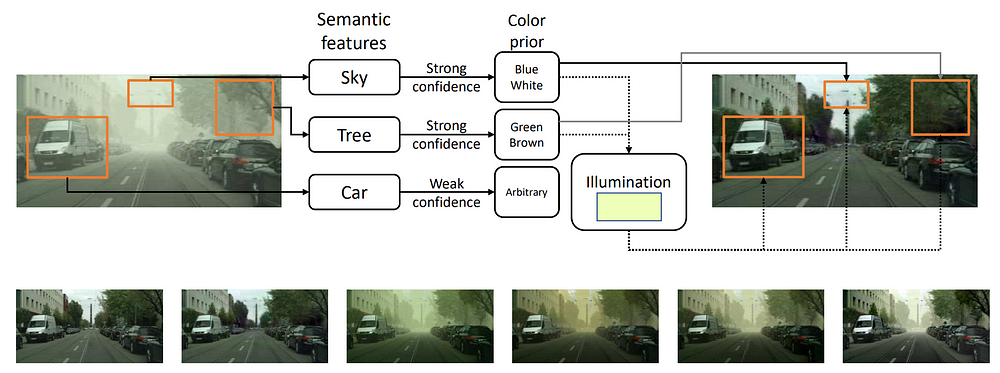
Figure 2. Semantic solution towards “dehazing”
Network architecture
As it was noticed that objects’ true color and ambient illumination are mutually dependent when given the hazy image as input, the researchers designed a network to incorporate them both and allow one to refine the other. This approach allows information learned from objects of strongly confident semantic priors (high confidence about the true color as learned from semantic priors) to propagate to other parts of the image and benefit the true color prediction for objects with weak semantic priors (low confidence about the true color as learned from semantic priors). An overview of the suggested model is depicted in the image below.
The model takes hazy images as input and produces a clean image as output. It consists of three modules:
- semantic module for extraction of the higher-level semantic features;
- global estimation module for predicting global features;
- color module for producing a clean image.
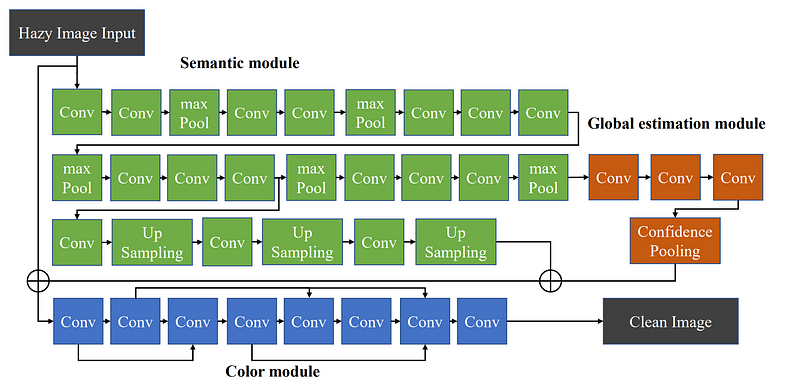
Figure 3. The pipeline of the proposed model
Semantic module. For extracting semantic features, a well-known image classification network VGG16 was chosen for its good performance and simplicity in design. The model has been extensively trained for object recognition task over 1,000 semantic categories. Next, considering that for the current image dehazing model, only semantics-related features are needed and not the exact labeling, the final dense and softmax layer of the VGG model was removed, and the output of its intermediate convolutional layers was used for semantic feature extraction.
Global estimation module. Next, the researchers use the semantic module for estimating a set of 32 global features. The aim here is to ensure that all valuable information from the global features, like ambient illumination or semantic context, inferred from scene semantics, will be used by the model. Then, the researchers adopt the confidence-weighted pooling technique. It enables the model to extract global features depending on the confidence level of semantic priors on local regions. As already discussed above, some object classes (e.g., sky, trees) are associated with higher confidence about their true color. So, the global pooling allows local features from these strongly confident semantic priors to be aggregated and broadcasted to other parts of an image.
Color module. This module exploits the architecture of AOD-Net but takes as input not only hazy images but also semantic and global features, extracted from previous modules. The final output of this convolutional neural network is an RGB image of predicted clean scene.

Figure 4. Visual comparison with the state-of-the-art methods over
a dataset with color scale haze
Evaluating the model quantitatively and qualitatively
The performance of the semantic approach towards single image “dehazing” was quantitively evaluated and compared with the other state-of-the-art methods on synthetic hazy images. For that purpose, three indicators were used:
- mean squared error (MSE);
- peak signal to noise ratio (PSNR);
- structural similarity metrics (SSIM).
Tables below provide results of this comparison based on two different datasets: with color scale haze and with greyscale haze.

Table 1. Comparison of semantic approach (denoted as Ours) with the CNN models (listed on the left) and handcrafted priors methods (listed on the right) based on a dataset with color scale haze.

Table 2. Comparison of semantic approach (denoted as Ours) with the CNN models (listed on the left) and handcrafted priors methods (listed on the right) based on a dataset with greyscale haze.
As you can see, the semantic approach to image “dehazing” produces significantly better results than other existing methods. Moreover, the method is shown to be robust against the estimation ambiguity introduced by different illumination settings. This is confirmed by its great performance on a dataset with a color scale haze (Table 1). Hence, the results of this quantitative evaluation support the notion that the semantic prior is a powerful tool for image “dehazing.”

Figure 5. Visual comparison with the state-of-the-art methods on real-world hazy images of urban scenes
The results of the proposed model were also compared qualitatively to other existing state-of-the-art methods for image “dehazing”. The comparison was carried out over a collection of synthetic and real-world hazy images. However, it worth to note, that given the semantic-aware nature of the suggested model, the real-world scenes for comparison were selected to contain semantic classes similar to the training examples — indoor scenes and outdoor road scenes.

Figure 6. Visual comparison with the state-of-the-art methods on real-world hazy images of urban scenes
Figures 4–6 demonstrate the capabilities of the suggested semantic approach towards the single image “dehazing”. The model can recover the scenes under the very strong haze of different colors, restores brightness and color balance, suggests plausible colors to objects indistinguishable to human eyes. For example, in Figure 4, the sky suffers from the severe color shift, but the model is still able to recover it naturally, and significantly outperforms other state-of-the-art methods. This gap in performance is due to the fact that the model under the semantic approach gets additional information about what is being imaged and uses this information to produce a high-quality result.
Let’s sum up
The proposed semantic approach towards single image haze removal is the first one that exploits high-level features for learning semantic priors, which provide informative cues for estimating underlying clean scene. The model proved to be robust against such extreme settings as heavy haze, bright surfaces, severe color shifting, saturated atmospheric light, and others. It obtains state-of-the-art results on the datasets with synthetic haze as well as on real-world hazy scenes of the semantic class similar to the one that the model was trained on — street scenes.
And here comes the main limitation of the proposed approach. It doesn’t generalize well to natural outdoor scenes until the model is trained on the corresponding images. However, the relevant datasets are missing, and hence, there is a deficit for the semantics of general real-world objects as well as their corresponding real colors. Still, the authors promise to improve their model by training it with a broader range of images.





