Graphical information requires a lot of storage resources, and the main task is to learn how to compress images without losing quality.
Computer Vision Laboratory Solution
A group of researchers from the Swiss Computer Vision laboratory offered a way to process images and video, allowing to significantly reduce the amount of memory required for storing graphical information. They reported that this approach is intended for images with a small bit rate (the number of bits for storing one pixel of the image) and can save up to 67% of memory compared to the BPG method.

Developers decided not to store the entire image, but only the most significant parts of it. The rest will be reconstructed when data is extracted.
For example, if we are watching a video with a walking person, we primarily focus on that person. The background does not really matter if there is nothing extraordinary.
Generation of insignificant areas cannot occur from scratch. To do this, a map of semantic marks is created from the original image. It notes that in one part of the image, for example, green foliage is located, in other part — asphalt, etc.
A solution became possible due to the use of deep neural networks (DNNs) as image compression systems. We are faced with them searching for information and translating the text using Google and Yandex.
GANs Modes of Operation
Generative adversarial networks (GANs) developed in the Computer Vision laboratory can work in two modes:
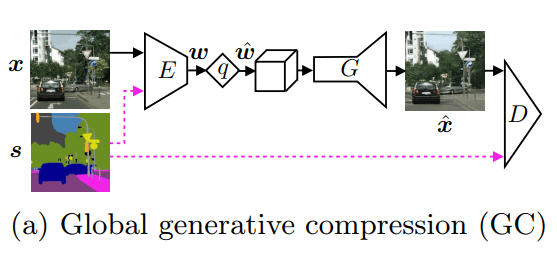
a) global generative compression (GC);
b) selective generative compression (SC).
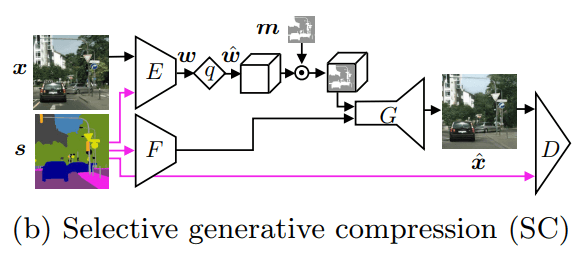
In the scheme, the original image is designated as x, and the map of semantic marks is s. In the GC mode, the semantic map can be used optionally. In the SC mode, its application is compulsory.
Other marks on the diagram:
- E — image encoder;
- w — image code;
- w(^) — the code after the quantization procedure (the second level of discretization of information);
- G — the generator of the compressed image;
- x(^) — compressed image.
An F device is added to the SC circuit, which extracts data from the semantic map and indicates their place to the generator.
The system allows efficient processing and indexing of any compressed images.
Neural Networks
Serious errors in the compressed image occur at bitrates below 0.1 bit per pixel (bpp). When bpp aspires to zero, it is impossible to preserve the full content of the image.
Therefore, it is important to go beyond the standard peak-to-noise ratio (PSNR). Adversarial losses function is considered a promising tool. It is used to capture global semantic information and local texture. They allow you to obtain high-resolution images from a semantic tag map.
Two types of neural networks are used to work with this technology: autoencoders and recursive neural networks. They convert the incoming image into a bitstream, which is compressed by mathematical coding or the Huffman method. The image quality remains the same.
Generative adversarial networks (GANs) have become a popular tool for neural networks training. They allow you to create more stable and clear images in comparison with previous technologies.