Human eyes are better than any known camera, so far. When we look at scenes where there’s a huge gap between the bright and dark tones (for example sunrise and sunset), we can see details everywhere. However, cameras struggle in these situations and what we get as a result is an image with the shadows crunched down to black or highlights blown out to white. Many similar problems have arisen in the past, and many approaches and techniques have been proposed to correct (adjust) an image to obtain a visually pleasing one.

Researchers from the University of Hong Kong and the Dalian University of Technology have proposed a new method for transforming an image to a visually pleasing one using deep neural networks.
The proposed technique allows to correct an image with under/over exposure and introduce many details. It works by taking a standard LDR image (LDR Image is an image in the low dynamic range), and it produces an enhanced image, again in the LDR domain but visually enriched with the recovered details. The deep neural network can bring back the details since they exist in HDR domain (high dynamic range) but they have diminished in the LDR domain, and this is actually where the magic comes from.
How Does It Work?
The new method is called Deep Reciprocating HDR Transformation, and as the name suggests it works by applying a reciprocal transformation utilizing two deep neural networks. In fact, the idea is simple: taking an LDR image, we reconstruct the details in the HDR domain and map the image back to the LDR domain (enriched with details). Although it sounds super simple, there are a few tricks that have to be performed to make all this work, and I explain them below.
In order to make the aforementioned reciprocal transformation, two convolutional neural networks (CNN) are used. The first one called HDR estimation network takes the input image, encodes it into a latent representation (of lower dimension, of course) and then decodes this representation to reconstruct an HDR image. The second one, called LDR correction network, is doing the reciprocal transformation: it takes the estimated HDR (from the first network) and outputs the corrected LDR image. Both of the networks are simple auto-encoders encoding the data into a latent representation of size 512.
The two networks are trained jointly and have the same architecture. However, as I mentioned before, there are some tricks and the optimization and the cost function are explicitly defined to address the problem at hand.

The HDR Estimation Network
The first network is trained to predict the HDR data. It has been trained using ELU activations, batch normalisation and the loss function is the simple mean squared error. And here comes the first trick: the MSE loss function is defined using the difference between the output and the ground truth modified with the constants used to convert HDR data to LDR.
The LDR Correction Network
The second network is taking the output of the first network and giving the corrected LDR image. The second trick comes in this part: the output of the first network (the HDR estimation) is modified before feeding it into the second network. In fact, the output of the first network is still in LDR domain (this comes from the first trick). So, this output is converted to HDR domain via gamma correction and then a logarithmic operation is applied.
The two auto-encoder networks share the same architecture and employ skip connections. Here is the complete architecture of the network.
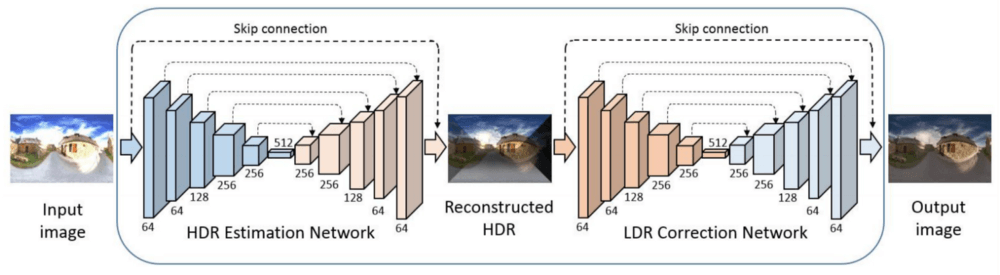
Each network is composed of five convolutional and five deconvolutional layers:
Conv1 Layer: 9 x 9 kernel size, 64 feature maps
Conv2 Layer: 5 x 5 kernel size, 64 feature maps
Conv3 Layer: 3 x 3 kernel size, 128 feature maps
Conv4 Layer: 3 x 3 kernel size, 256 feature maps
Conv5 Layer: 3 x 3 kernel size, 256 feature maps
Latent representation: 1 x 512
Deconv1 Layer: 3 x 3 kernel size, 256 feature maps
Deconv2 Layer: 3 x 3 kernel size, 256 feature maps
Deconv3 Layer: 3 x 3 kernel size, 128 feature maps
Deconv4 Layer: 5 x 5 kernel size, 64 feature maps
Deconv5 Layer: 9 x 9 kernel size, 64 feature maps
The training was done using ADAM optimizer algorithm, with the initial learning rate of 1e-2.
Datasets
Two datasets are used for training and testing the method: city scene panorama dataset and Sun360 outdoor panorama dataset. Moreover, the authors mention that they used Photoshop to generate ground truth LDR images with human supervision for the intermediate task. The size of the training set used to train both networks is around 40 000 image triplets (original LDR image, ground-truth HDR and ground- truth LDR image).
Evaluation
As the authors state, the proposed method performs favourably against state-of-the-art methods. The evaluation was done by comparing the method to 5 state-of-the-art methods: Cape, WVM, SMF, L0S, and DJF.
The evaluation is not pretty straightforward since the goal of the creation of visually pleasing images, which is both difficult to quantify and also subjective. However, the authors use a range of different evaluation metrics. They used HDR-VDP-2 parameter for evaluating the first network as it reflects the human perception and for assessing the whole method and comparing with existing methods a few different metrics have been used like: PSNR, SSIM, FSIM.
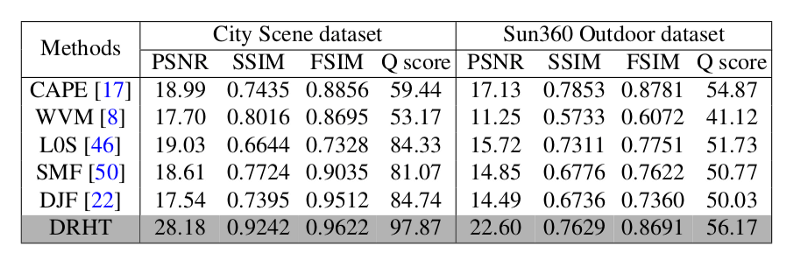
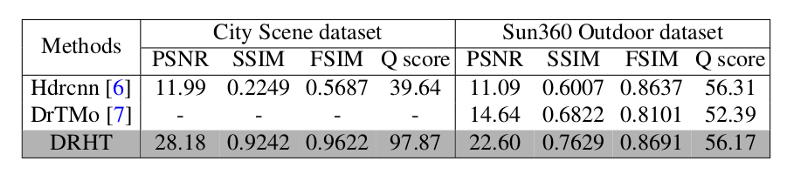
Visual evaluation is also provided where the significant results of the proposed method can be seen next to the results from other existing methods.

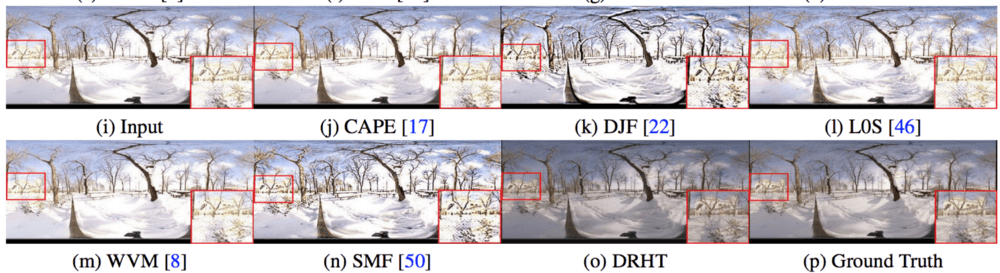
In conclusion, the proposed method shows that buried details in the under/over exposed images can be recovered and deep learning proved successful in another critical and non-trivial task.
Dan Mitriev