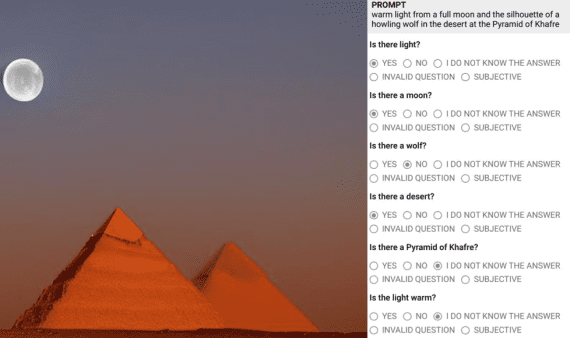
The Power of Predictive Weather Data in Modern Business
25 July 2024

The Power of Predictive Weather Data in Modern Business
Predictive weather data is a crucial asset derived from extensive datasets collected from meteorological observations, satellite imagery, radar systems, and weather stations globally. This article delves into how predictive weather…