Deep learning played an important role in the past years for the improvement of visual recognition of individual instances e.g detecting objects and pose estimation. However, recognizing individual objects is just a first step for machines to comprehend the visual world. To understand what is happening in images, it is also necessary to identify relationships between individual instances.
From a practical perspective, photos containing people contribute a considerable portion of daily uploads to the internet and social networking sites, and thus human-centric understanding has significant demand in practice. The fine granularity of human actions and their interactions with a wide array of object types presents a new challenge compared to recognition of entry-level object categories.
The idea is to present a human-centric model for recognizing human-object interaction. The central observation is a person’s appearance, which reveals their action and poses, is highly informative for inferring where the target object of the interaction may be located. The search space for the target object can thus be narrowed by conditioning on this estimation. Although there are often many objects detected the inferred target location can help the model to pick the correct object associated with a specific action quickly.
The Faster R-CNN framework is used to model the human-centric recognition branch. Specifically, on a region of interest (RoI) associated with a person, this branch performs action classification and density estimation for the action’s target object location. The density estimator predicts a 4-d Gaussian distribution, for each action type, that models the likely relative position of the target object to the person. The prediction is based purely on the human appearance. This human-centric recognition branch, along with a standard object detection branch and a simple pairwise interaction branch form a multitask learning system that can be jointly optimized.
Model Architecture
The model is consists of:
- an object detection branch;
- a human-centric branch;
- an optional interaction branch.
The person features and their layers are shared between the human-centric and interaction branches (blue boxes).
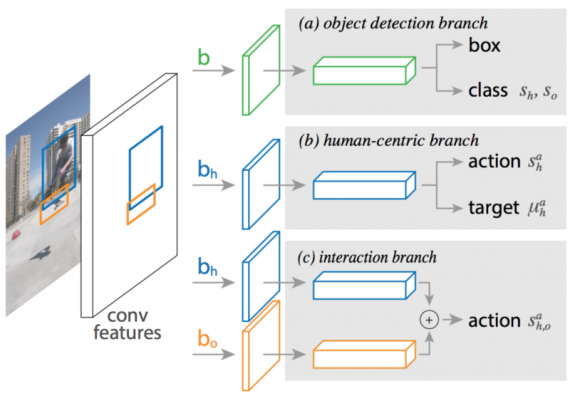
The goal is to detect and recognize triplets of the form (human, verb, object). The solution to this problem is extending the Fast R-CNN with an additional human-centric branch that classifies actions and estimates a probability density over the target object location for each activity. The human-centric branch reuses features extracted by Fast R-CNN for object detection, so its marginal computation is lightweight. Specifically, given a set of candidate boxes, Fast R-CNN outputs a set of object boxes and a class label for each box. The model is extended by assigning a triplet score S to pairs of candidate human/object boxes b(h), b(o) and an action a. The triplet score is decomposed into four terms.
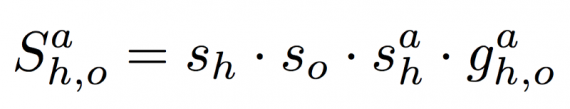
While the model has multiple components, the basic idea is straightforward. s(h) and s(o) are the class scores from Fast R-CNN of b(h) and b(o) containing a human and object.
Object Detection
The object detection branch of the network, shown in Figure 1, is identical to that of Faster R-CNN.
Action Classification
The first role of the human-centric branch is to assign an action classification score s(a, h) to each human box b(h) and action a. The training objective is to minimize the binary cross entropy losses between the ground-truth action labels and the scores s(a, h) predicted by the model.
Target Localization
The second role of the human-centric branch is to predict the target object location based on a person’s appearance (again represented as features pooled from b(h)). This approach predicts a density over possible locations, and use this output together with the location of actual detected objects to precisely localize the target. To model the density over the target object’s location as a Gaussian function whose mean is predicted based on the human appearance and action being performed. Formally, the human-centric branch predicts µ(a,h), the target object’s 4-d mean location given the human box b(h) and action a. The target localization showed as:
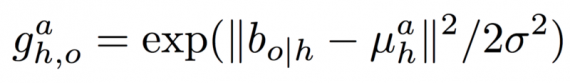
g can be used to test the compatibility of an object box b(o) and the predicted target location µ(a,h).
Interaction Recognition
The human-centric model scores actions based on the human appearance. While effective, this does not take into account the appearance of the target object. To improve the discriminative power of the model, and to demonstrate the flexibility of framework s(a, h) is replaced with an interaction branch that scores an action based on the appearance of both the human and target object.

The model is first to train COCO set (excluding the V-COCO val images). This model, which is in essence Faster R-CNN, has 33.8 object detection AP on the COCO val set. InteractNet, has an AP(role) of 40.0 evaluated on all action classes on the V-COCO test set and also on HICO-DET dataset. This is an absolute gain of 8.2 points over the strong baseline’s 31.8, which is a relative improvement of 26%. The result is shown in the below table.

Result

The research addresses the problem of human object detection task. The proposed approach correctly detected triplets of one person taking multiple actions on multiple objects. Moreover, InteractNet can detect multiple interaction instances in an image. Below figures show two test images with all detected triplets shown.