Suppose you have a 10-minutes-video but are interested only in a small portion of it. You are thinking about creating a 5-second GIF out of this video, but video-editing can be quite a cumbersome task. Would it be possible to automatically create such GIF for you? Would the algorithm be able to detect the moments you want to highlight? Well, in this article we are going to talk about a new approach to this task. It takes into account a history of GIFs previously created by you and suggests an option, which is pretty much likely to highlight the moments you are interested in.
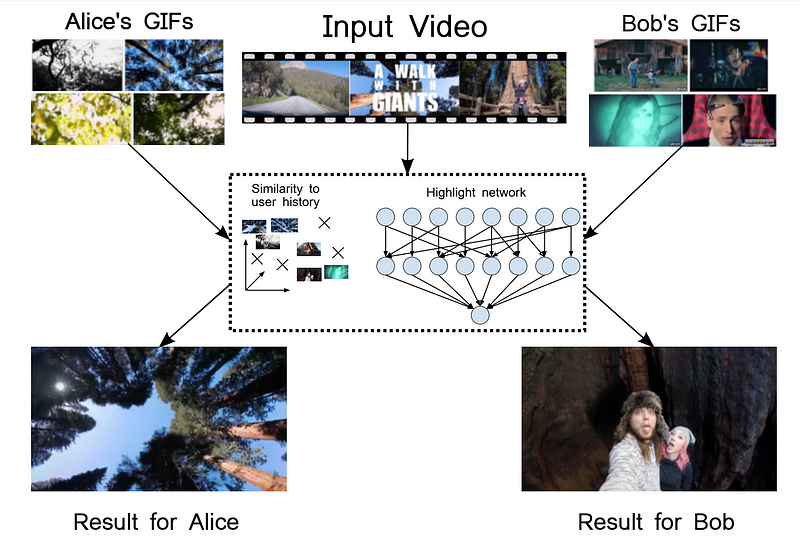
Figure 1. Taking into account users previously selected highlights when creating GIFs
Typically, highlight detection models are trained to identify cues that make visual content appealing or interesting to most of the people. However, the “interestingness” of a video segment or image is in fact subjective. As a result, such highlight models often provide results that are of limited relevance for the individual user. Another approach suggests training one model per user, but this turns out to be inefficient and, in addition, requires large amounts of personal information, which is typically not available. So…
What is suggested?
Ana Garcia del Molino and Michael Gygli, while working at gifs.com, suggested a new global ranking model, which can condition on a particular user’s interests. Rather than training one model per user, their model is personalized via its inputs, which allows it to effectively adapt its predictions, given only a few user-specific examples. It is built on the success of deep ranking models for highlight detection but makes the crucial enhancement of making highlight detection personalized.
If put in simple terms, the researchers suggest using information on the GIFs that a user previously created as this represents his or her interests and thus, provides a strong indication for personalization. Knowing, that a specific user is interested in basketball, for example, is not sufficient. One user may edit basketball videos to extract the slams, another one may just be interested in the team’s mascot jumping. A third one may prefer to see the kiss cam segments of the game.

Figure 2. Some examples of user histories from the paper
To obtain data about the GIFs previously created by different users, the researchers have turned to gifs.com and its user base and collected a novel and large-scale dataset of users and the GIFs they created. Moreover, they made this dataset publicly available from here. It consists of 13,822 users with 222,015 annotations on 119,938 videos.
Model Architecture
The model that is suggested predicts the score of a segment based on both the segment itself and the user’s previously selected highlights. The method uses a ranking approach, where a model is trained to score positive video segments higher than negative segments from the same video. In contrast to previous works, however, the predictions are not based on the segment solely, but also take a user’s previously chosen highlights, their history, into account.
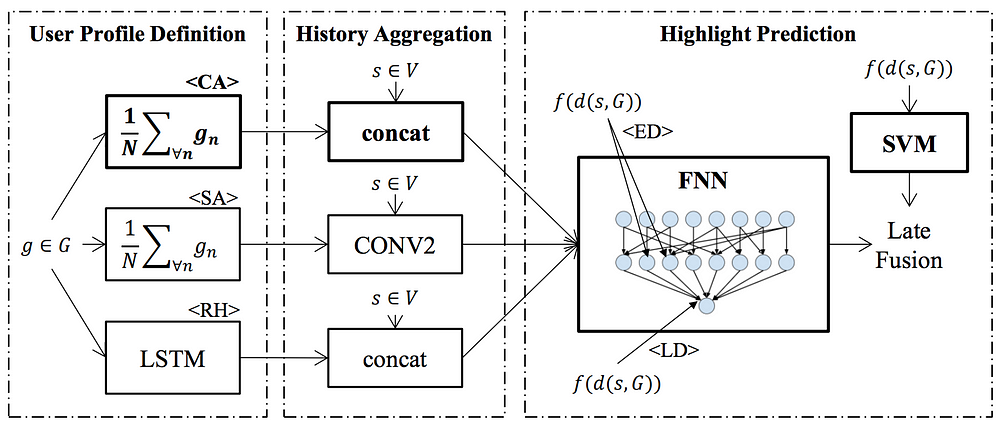
Figure 3. Model architecture. Proposed model (in bold) and alternative ways to encode the history and fuse predictions
In fact, the researchers propose two models, which are combined with late fusion. One takes the segment representation and aggregated history as input (PHD-CA), while the second directly uses the distances between the segments and the history (SVM-D). For the model with the aggregated history, they suggest using a feed-forward neural network (FNN). It is the quite small neural network with 2 hidden layers with 512 and 64 neurons. Within the distance-based model, they have created a feature vector that contains the cosine distances to the number of most similar history elements. Then the two models are combined with late fusion. As the models differ in the range of their predictions and their performance, a weight was applied to ensemble the models.
Performance of the proposed model in comparison to other methods
The performance of the suggested model was compared against several strong baselines:
- Video2GIF. This approach is the state-of-the-art for automatic highlight detection for GIF creation. The comparison was carried out for both originally pre-trained model and a model with slight variations trained on the gifs.com dataset, which is referred to as Video2GIF (ours).
- Highlight SVM. This model is a ranking SVM trained to correctly rank positive and negative segments, but only using the segment’s descriptor and ignoring the user history.
- Maximal similarity. This baseline scores segments according to their maximum similarity with the elements in the user history. Cosine similarity was used as a similarity measure.
- Video-MMR. Within this model, the segments that are most similar are scored highly. Specifically, the mean cosine similarity to the history elements is used as an estimate of the relevance of a segment.
- Residual Model. Here the researchers decided to adopt an idea from another study, where a generic regression model was used together with a user-specific model that personalizes predictions by fitting the residual error of the generic model. So, in order to adapt this idea to the ranking setting, they proposed training a user-specific ranking SVM that gets the generic predictions from Video2GIF (ours) as an input, in addition to the segment representation.
- Ranking SVM on the distances (SVM-D). This one corresponds to the second part of the proposed model (distance-based model).
The following metrics were used for quantitative comparison: mAP — mean average precision; nMSD — normalized Meaningful Summary Duration and Recall@5 — the ratio of frames from the user-generated GIFs (the ground truth) that are included in the 5 highest ranked GIFs.
Here are the results:
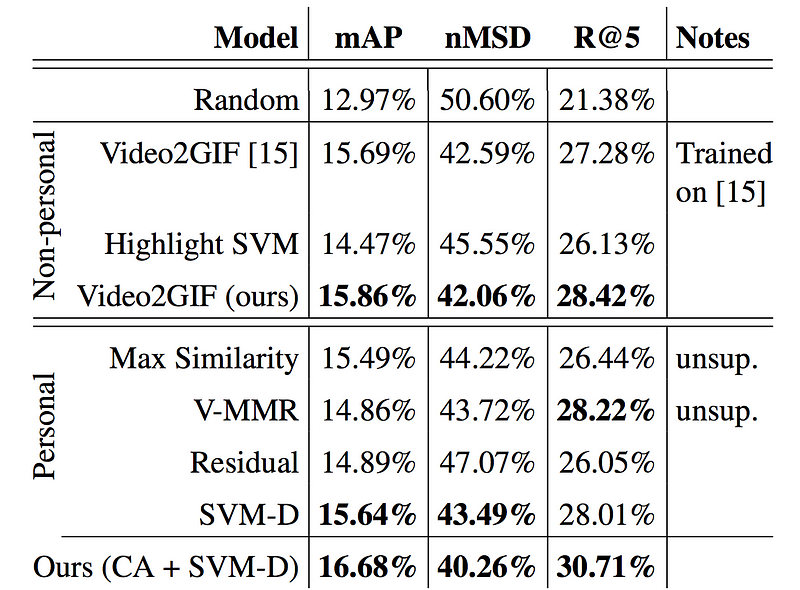
Table 1. Comparison of the suggested approach (denoted as Ours) to the state-of-the-art alternatives for videos segmented into 5-second long shots. For mAP and R@5, the higher the score, the better the method. For MSD, the smaller is better. Best result per category in bold.
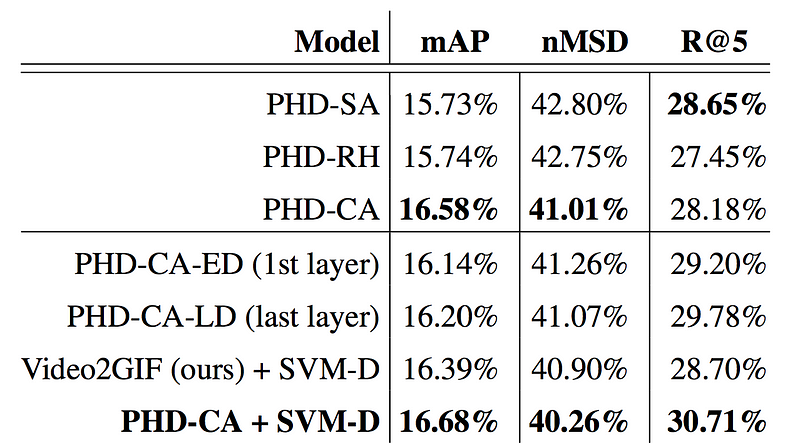
Table 2. Comparison of different ways to represent and aggregate the history, as well as ways to use the distances to the history to improve the prediction.
As you can see, the proposed method outperforms all baselines by a significant margin. Adding information about the user history to the highlight detection model (Ours (CA + SVM-D)) leads to a relative improvement over generic highlight detection (Video2GIF (ours)) of 5.2% (+0.8%) in mAP, 4.3% (-1.8%) in mMSD and 8% (+2.3%) in Recall@5.

Figure 4. Qualitative comparison to the state-of-the-art method (Video2GIF). Correct results have green borders. © provides a failure case when the user’s history is misleading the model
Let’s sum up
A novel model for personalized highlight detection was introduced. The distinctive feature of this model is that its predictions are conditioned on a specific user by providing his previously chosen highlight segments as inputs to the model. The experiments demonstrated that the users often have high consistency in the content they select, which allows the proposed model to outperform other state-of-the-art methods. In particular, the suggested approach outperforms generic highlight detection by 8% in Recall@5. This is a considerable improvement in this challenging high-level task.
Finally, a new large-scale dataset with personalized highlight information was introduced, which can be of particular use for further studies in this area.