
Single-view image-based 3D modeling is a topic of particular interest the last few years. That’s likely due to the tremendous success of deep convolutional neural networks (CNN) on image-based learning tasks. However, most of the deep models provide the only volumetric representation of 3D shapes as output. As a result, important information about shape topology or part structure is lost.

Figure 1. Results of 3D share structure recovery from a single image. Top-8 images, returned by Google, when searching for “chair”, “table” and “airplane” were used to test the new approach. Failure cases are marked with red
The alternative could be to recover 3D shape structure, which encompasses part composition and part relations. This task is quite challenging: inferring a part segmentation for a 3D shape is not an easy task by itself, but even if a segmentation is given, it is still challenging to reason about part relations such as connection, symmetry, parallelism, and others.
In fact, we can talk about several particular challenges here:
- Part decomposition and relations are not as explicit in 2D images, as, for example, shape geometry. It should be also noted that compared to pixel-to-voxel mapping, recovering part structure from pixels would be a highly ill-posed task.
- Many 3D CAD models of human-made objects contain diverse substructures, and recovery of those complicated 3D structures is far more challenging than shape synthesis modulated by a shape classification.
- Objects from real images usually have different textures, lighting conditions, and backgrounds.
What’s Suggested
Chengjie Niu, Jun Li, and Kai Xu suggest learning a deep neural network that directly recovers 3D shape structure of an object from a single RGB image. To accomplish this task, they propose to learn and integrate two networks:
- Structure masking network, which highlights multi-scale object structures in an input 2D image. It is designed as a multi-scale convolutional neural network (CNN) augmented with jump connections. Its task retains shape details while screening out the structure-irrelevant information such as background and textures.
- Structure recovery network, which recursively recovers a hierarchy of object parts abstracted by cuboids. This network takes as input the features extracted in the structure masking network, adds the CNN features of the original 2D image, and then feeds all these features into a recursive neural network (RvNN) for 3D structure decoding. The output is a tree organization of 3D cuboids with plausible spatial configuration and reasonable mutual relations.
The two networks are trained jointly. The training data includes image-mask and cuboid-structure pairs that can be generated by rendering 3D CAD models and extracting the box structure based on the given parts of the shape.
Network Architecture
An overview of the suggested network architecture is depicted in the image below. As you can see from the resultant cuboid structure of the chair, symmetries between chair legs (highlighted by red arrows) were successfully recovered by this network.
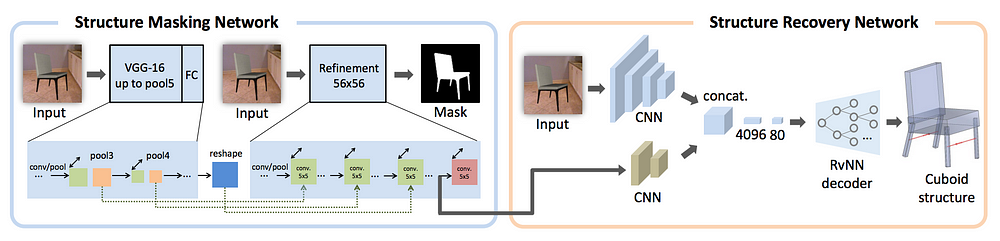
Figure 2. Network architecture
Let’s check more closely the details of the suggested solution.
The structure masking network is a two-scale CNN trained to produce a contour mask for the object of interest. The authors decided to include this network as the first step since previous studies of the subject revealed that object contours provide strong cues for understanding shape structures in 2D images. However, instead of utilizing the extracted contour mask, they suggest taking the feature map of the last layer of the structure masking network and feeding it into the structure recovery network.
Next, the structure recovery network combines features from two convolutional channels. One channel takes as input the last feature map before the mask prediction layer from the structure masking network. Another channel is the CNN feature of the original image extracted by a VGG-16. Since it is hard for the masking network to produce perfect mask prediction, the CNN feature of the original image provides complementary information by retaining more object information.
So, the recursive neural network (RNN) starts from a root feature code and recursively decodes it into a hierarchy of features until reaching the leaf nodes, which can be further decoded into a vector of box parameters. The suggested solution uses three types of nodes in its hierarchy, including leaf node, adjacency node, and symmetry node, as well as the corresponding decoders such as box decoder, adjacency decoder, and symmetry decoder. Illustration of the decoder network at a given node is provided below.
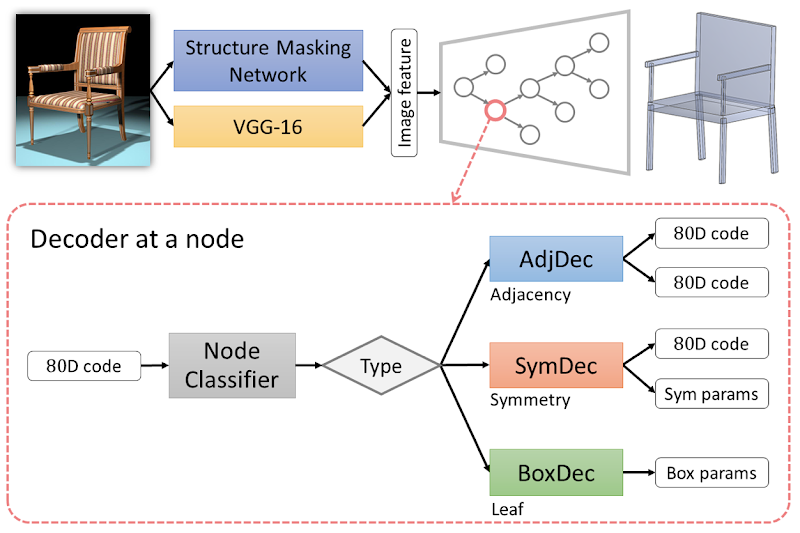
Figure 3. Decoder network
Thus, during the decoding, two types of part relations are recovered as the class of internal nodes: adjacency and symmetry. In order to determine correctly type of the node and use the corresponding decoder, a separate node classifier is trained jointly with the three decoders. It is learned based on the training task of structure recovery, where the ground-truth box structure is known for a given training pair of image and shape structure.
The dataset for training the model included 800 3D shapes from three categories in ShapeNet: chairs (500), tables (200), airplanes (100). For each 3D shape, researchers created 36 rendered views around the shape for every 30° rotation with 3 elevations. Together with another 24 randomly generated views, there we 60 rendered RGB images in total for each shape. The 3D shapes were then complemented with randomly selected backgrounds from NYU v2 dataset.
Results and Application
Some results of recovering 3D shape structure from a single RGB image using the suggested approach can be observed in Figure 1, where top 8 images, returned by Google for the search of “chair”, “table” and “airplane”, were selected, and then for each image a 3D cuboid structure was recovered. From the results, it can be observed that the approach described here is able to recover 3D shape structures from real images in a detailed and accurate way. Moreover, it allows recovering the connection and symmetry relations of the shape parts from single view inputs.
The authors of this approach suggest two settings, where their method of recovering 3D shape structure can be used:
- structure-aware image editing;
- structure-assisted 3D volume refinement.
The results of applying their method to these problems are demonstrated in the image below.

Figure 4. Top row: The inferred 3D shape structure can be used to complete and refine the volumetric shape. Bottom row: The structure is used to assist structure-aware image editing.
Bottom Line
The suggested approach to recovering 3D shape structure from a single RGB image has several important strengths:
- connection and symmetry relations are recovered quite accurately;
- the overall result is sufficiently detailed;
- the method can be useful for structure-aware image editing and structure-assisted 3D volume refinement.
However, the method fails to recover structures for object categories unseen from the training set. Moreover, it currently recovers 3D cuboids only but not the underlying part geometry, and so the roundtable appears like a square table in a recovered 3D shape structure.
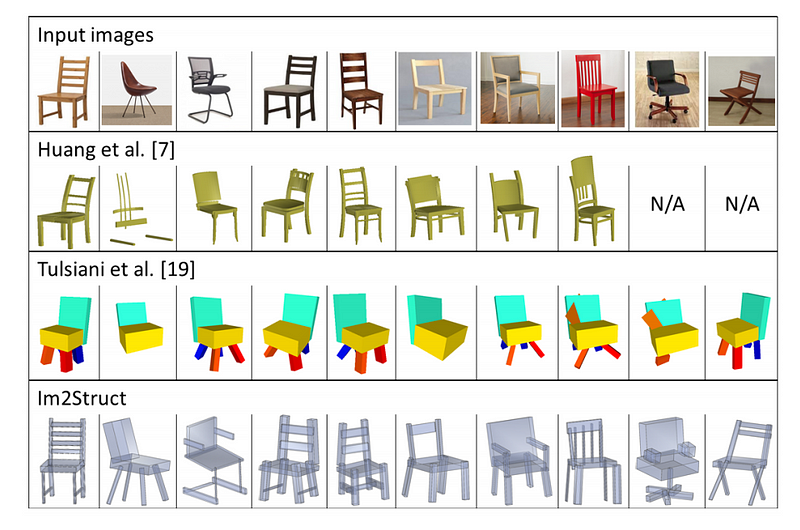
Figure 5: Comparing single-view, part-based 3D shape reconstruction between our Im2Struct and two alternatives
To sum up, by combining 2 neural networks (structure masking network and structure recovery network) the researchers managed to recover faithful and detailed 3D shape structure of an object from a single 2D image, reflecting part connectivity and symmetries — something that has never been done before.
The main job was done by the second network (namely, reflecting part connectivity and symmetries) while combining it with the structure masking network allowed for more accurate results in general. From this point of view, we may say that structure recovery network, and, in particular, structure decoding part of this network is a key component of this research.








