Digital media needs realistic 3D avatars with faces. The recent surge in augmented and virtual reality platforms has created an even stronger demand for high-quality content, and rendering realistic faces plays a crucial role in achieving engaging face-to-face communication between digital avatars in simulated environments.
So, what could be a perfect algorithm? The person takes mobile “selfie” image, uploads the picture and gets an avatar in the simulated environment with accurately modeled facial shape and reflectance. In practice, however, significant compromises are made to balance the amount of input data to be captured, the amount of computation required, and the quality of the final output.
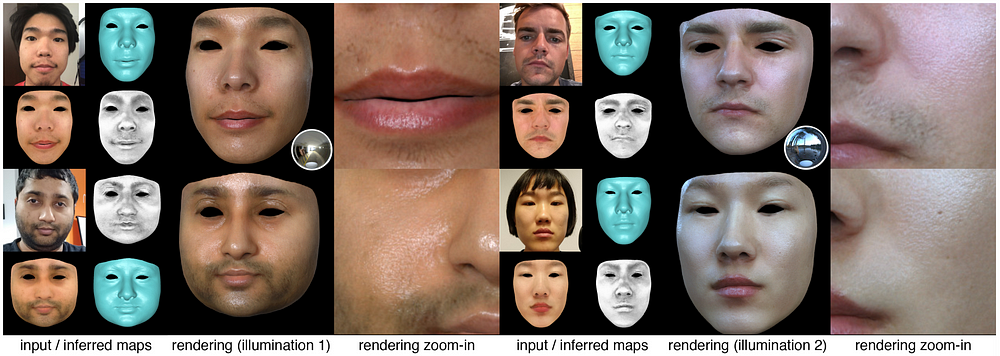
Figure 1. Inferring high-fidelity facial reflectance and geometry maps from a single image
Despite the high complexity of the task, group of researchers from USC Institute for Creative Technologies claims that their model allows to efficiently create accurate, high-fidelity 3D avatars from a single input image, captured in an unconstrained environment. Furthermore, the avatars will be close in quality to those created by professional capture systems but will require minimal computation and no special expertise on the part of the photographer.
So, let’s discover their approach to creating high-fidelity avatars from a single image without extensive computations or manual efforts.
Overview of the Suggested Approach
First of all, the model is trained with high-resolution facial scans obtained using a state-of-the-art multi-view photometric facial scanning system. This approach helps to get high-resolution and high-fidelity geometric and reflectance maps from a 2D input image, which can be captured under arbitrary illumination and contain partial occlusions of the face. The inferred maps can be next used to render a compelling and realistic 3D avatar in novel lighting conditions. The whole process can be accomplished in seconds.
Considering the complexity of the task, it was decomposed into several problems, which are addressed by separate convolutional neural networks:
· Stage 1 includes obtaining the coarse geometry by fitting a 3D template model to the input image, extracting an initial facial albedo map from this model, and then using networks that estimate illumination-invariant specular and diffuse albedo and displacement maps from this texture.
· Stage 2: the inferred maps, which may have missing regions due to occlusions in the input image, are passed through networks for texture completion. High-fidelity textures are obtained using a multi-resolution image-to-image translation network, in which latent convolutional features are flipped so as to achieve a natural degree of symmetry while maintaining local variations.
· Stage 3: another network is used to obtain additional details in the completed regions.
· Stage 4: a convolutional neural network performs super-resolution to increase the pixel resolution of the completed texture from 512 × 512 into 2048 × 2048.
Let’s discuss the architecture of the suggested model in more details.
Model Architecture
The pipeline of the proposed model is illustrated below. Given a single input image, the base mesh and corresponding facial texture map are extracted. This map is passed through two convolutional neural networks (CNNs) that perform inference to obtain the corresponding reflectance and displacement maps. Since these maps may contain large missing regions, the next step includes texture completion and refinement to fill these regions based on the information from the visible regions. And finally, super-resolution is performed. The resulting high-resolution reflectance and geometry maps may be used to render high-fidelity avatars in novel lighting environments.
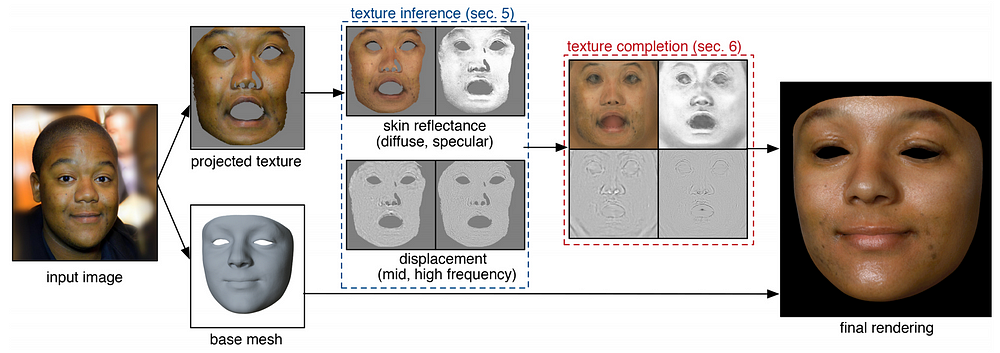
Figure 2. The pipeline of the proposed model
Reflectance and geometry inference. The pixel-wise optimization algorithm is adopted to obtain the base facial geometry, head orientation, and camera parameters. This data is then used to project the face into a texture map in the UV space. The non-skin region is removed. The RGB texture extracted is fed into the model of U-net architecture with skip connections to obtain the corresponding diffuse and specular reflectance maps and the mid- and high-frequency displacement maps.
To obtain the best overall performance, two networks with identical architectures were employed: one operating on the diffuse albedo map (subsurface component), and the other on the tensor obtained by concatenating the specular albedo map with the mid- and high-frequency displacement maps (collectively surface components).
Symmetry aware texture completion. Again, the best results were obtained by training two network pipelines: one pipeline — to complete the diffuse albedo, and another one — to complete the other components (specular albedo, mid- and high-level displacement).
Next, it was discovered that completing large areas at high resolution doesn’t give satisfactory results due to the high complexity of the learning objective. Thus, the inpainting problem was divided into simpler sub-problems as shown on the picture below.
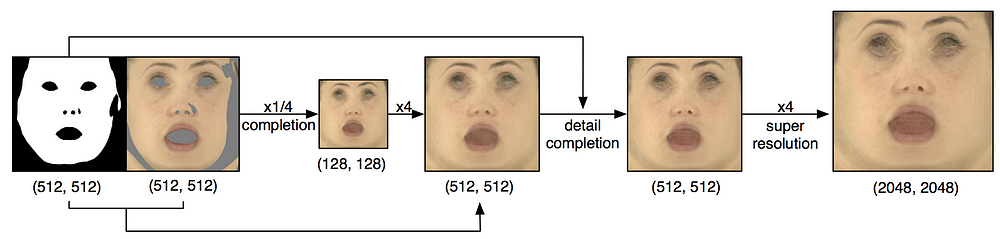
Figure 3. Texture completion pipeline
Furthermore, the researchers leveraged the spatial symmetry of UV parameterization and maximized the feature coverage by flipping intermediate features over the V-axis in UV space and concatenate them to the original features. This allowed completed textures to contain a natural degree of symmetry as seen in real faces instead of an uncanny degree of near-perfect symmetry.
Each network was trained using the Adam optimizer with a learning rate set to 0.0002.

Figure 4. Examples of resulting renderings in new lighting conditions
Results
Quantitative evaluations of the system’s ability to faithfully recover the reflectance and geometry data from a set of 100 test images are depicted in the Table below.

Table 1. Peak signal-to-noise ratio (PSNR) and the structural similarity (SSIM) of the inferred images for 100 test images compared to the ground truth
Even though we observe relatively large differences from the ground truth of the specular albedo results, qualitative evaluations demonstrate that the inferred data is still sufficient for rendering compelling and high-quality avatars.
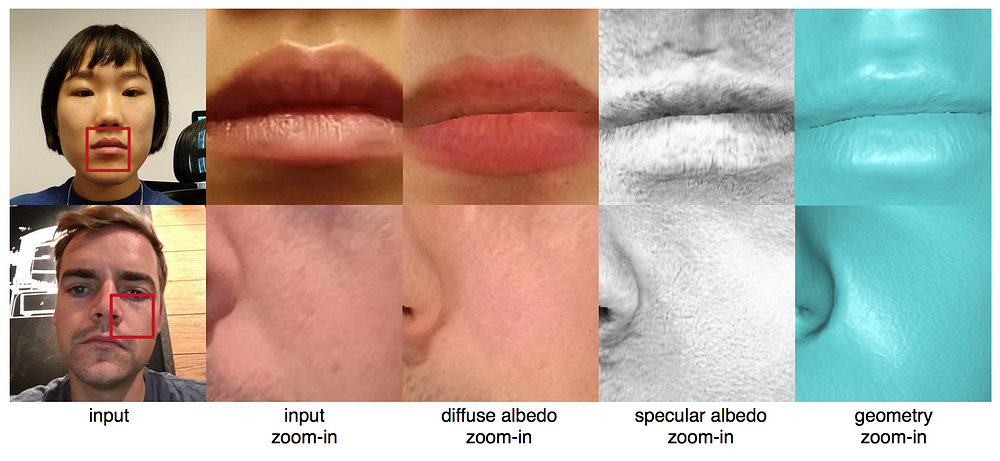
Figure 5. Zoom-in results showing synthesized mesoscopic details
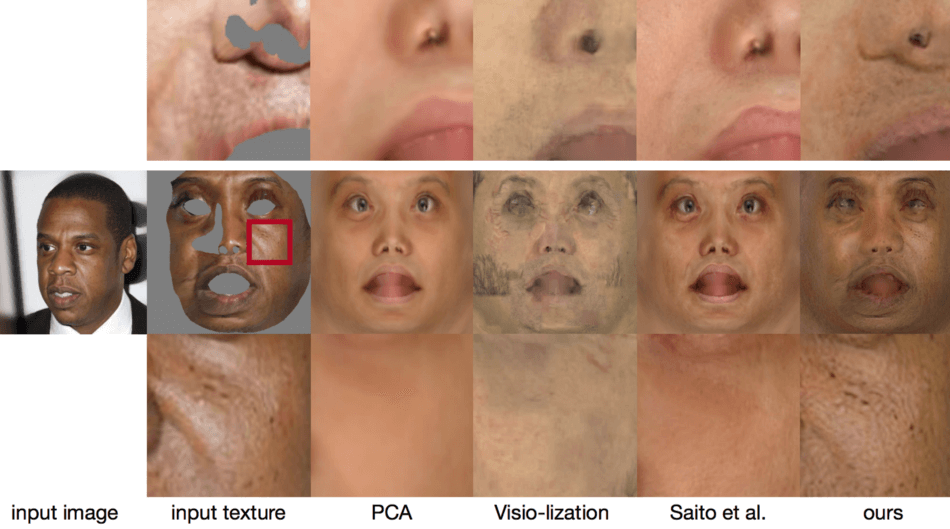
Furthermore, the results were compared quantitatively and qualitatively to other state-of-the-art methods. This comparison revealed that the new approach presented here results in more coherent and plausible facial textures than any of the alternative methods.
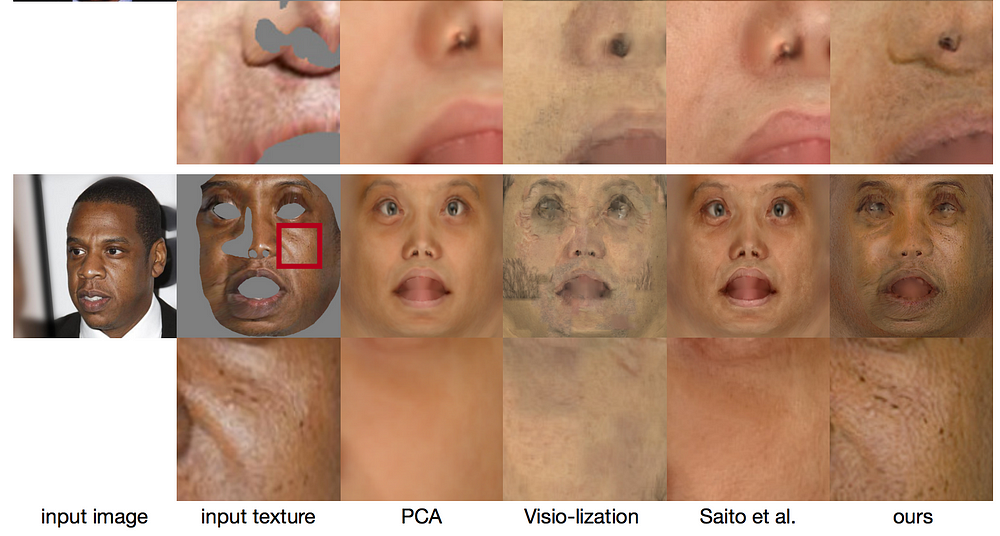
Figure 6. Comparison with PCA, Visio-lization [Mohammed et al. 2009], and a state-of-the-art diffuse albedo inference method [Saito et al. 2017]
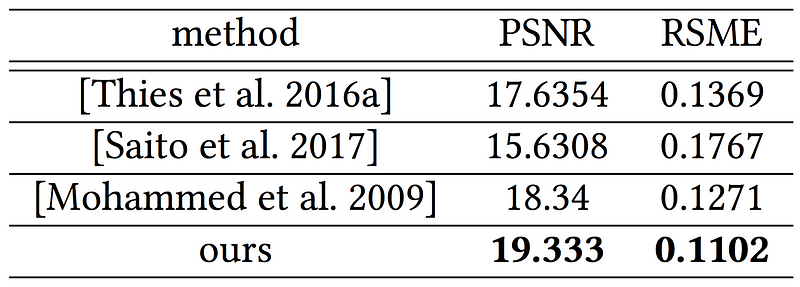
Table 2. Quantitative comparison of the suggested model with several alternative methods, measured using the PSNR and the root-mean-square error (RMSE)
Conclusion
In summary, the suggested approach makes it feasible to infer high-resolution reflectance and geometry maps using a single unconstrained image. Not only these maps are sufficient for rendering compelling and realistic avatars, but they can be obtained within only several seconds rather than several minutes like it’s required for alternative methods. These great results are possible in large part due to the use of high-quality ground truth 3D scans and the corresponding input images. Moreover, the technique of flipping and concatenating convolutional features encoded in the latent space of the model allowed to perform texture completion with preserving the natural degree of facial symmetry.

Figure 7. Demonstration of the model’s limitations
Still, the suggested approach has several limitations that are demonstrated in the figure above. The method produces artifacts in the presence of strong shadows and non-skin objects due to segmentation failures. Also, volumetric beards are not faithfully reconstructed, and strong dynamic wrinkles may cause artifacts in the inferred displacement maps.
Nevertheless, these limitations could not deny the great contribution that the suggested approach makes to the problem of creating high-fidelity avatars for the simulated environments.









please make a plugin for 3d sculpting software?