Графическая информация требует больших ресурсов для хранения, и основная задача разработчиков — научиться сжимать изображения без потери качества.
Решение от Computer Vision Laboratory
Группа исследователей из швейцарской лаборатории Computer Vision предложили способ обработки изображений и видео, позволяющий значительно сократить объемы памяти, требуемой для хранения графической информации. По их сообщениям, этот подход предназначен для изображений с небольшим битрейтом и способен сэкономить до 67% памяти по сравнению с методом BPG.

Разработчики решили хранить не все изображение, а только самые значимые его части. Остальное будет достраиваться при извлечении данных. Например, если мы смотрим видео с идущим человеком, взгляд в первую очередь фокусируется на нём. Фон не имеет особого значения, если там нет ничего экстраординарного.
Генерация незначимых областей не может происходить на пустом месте. Для этого из оригинального изображения создается карта семантических меток. В ней отмечается, что в этом месте изображения находится, например, зеленая листва, а в этом асфальт и т.д.
Такое решение стало возможным благодаря использованию глубоких нейронных сетей (DNNs) в качестве систем сжатия изображения. Мы сталкиваемся с их применением при поиске информации в Google или Яндекс, а также при переводе текста с помощью Google Translate и Яндекс.Переводчик.
Режимы работы GANs
Генеративно-состязательные сети (GANs), разработанные в лаборатории компьютерного зрения, могут функционировать в двух режимах:
а) глобального генерирующего сжатия (GC);
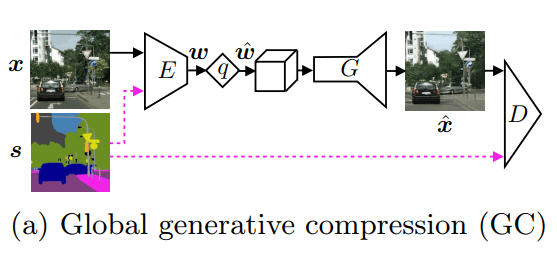
б) выборочного генерирующего сжатия (SC).
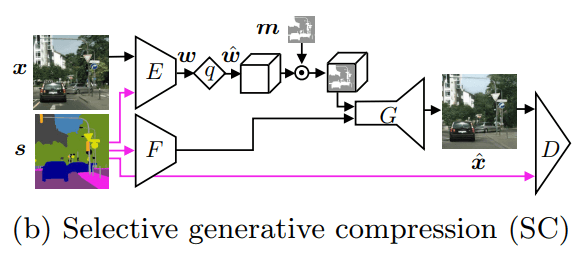
На схеме оригинальное изображение обозначено как x, а карта семантических меток — s. В модели GC семантическая карта может использоваться опционально. В выборочном сжатии она применяется в обязательном порядке.
Другие обозначения на схеме:
- E — кодировщик изображения;
- w — код изображения;
- w (c галочкой) — код после процедуры квантования (второго уровня дискретизации информации);
- G — генератор сжатого изображения;
- x (c галочкой) — сжатое изображение.
В схему SC добавляется устройство F, которое извлекает данные из семантической карты и указывает их место генератору.
Такая система позволяет эффективно обрабатывать и индексировать любые сжатые изображения.
Серьезные погрешности в сжатом изображении возникают при битрейтах ниже 0,1 бит на пиксель (bpp). При стремлении bpp к нулю сохранять полное содержание изображения становится невозможным.
Поэтому важно выйти за пределы стандартных показателей уровня отношения пикового сигнала к уровню шума (PSNR). Перспективным инструментом считаются соперничающие потери, которые использовались для захвата глобальной семантической информации и местной текстуры. Они позволяют получать изображения с высоким разрешением из семантической карты меток.
Для работы с этой технологией используются два вида нейронных сетей: аутоэнкодеры и рекурсивные нейронные сети. Они преобразуют входящее изображение в поток битов, который сжимается с помощью математического кодирования или методом Хаффмана. Качество изображения при этом остаётся прежним.
Заключение
Генеративно-состязательные сети (GANs) стали популярным инструментом для обучения нейронных сетей. Они позволяют создавать более чёткие изображения по сравнению с прежними технологиями.