
Deep networks can be extremely powerful and effective in answering complex questions. But it is also well-known that in order to train a really complex model, you’ll need lots and lots of data, which closely approximates the complete data distribution.
With the lack of real-world data, many researchers choose data augmentation as a method for extending the size of a given dataset. The idea is to modify the training examples in such a way that keeps their semantic properties intact. That’s not an easy task when dealing with human faces.
The method should account for such complex transformations of data as pose, lighting and non-rigid deformations, yet create realistic samples that follow the real-world data statistics.
So, let’s see how the latest state-of-the-art methods approach this challenging task…
Previous approaches
Generative adversarial networks (GANs) have demonstrated their effectiveness in making synthetic data more realistic. Taking the simulated data as input, GAN produces samples that appear more realistic. However, the semantic properties of these samples might be altered, even with a loss penalizing the change in the parameters of the output.
3D morphable model (3DMM) is the most commonly used method for representation and synthesis of geometries and textures, and it was originally proposed in the context of 3D human faces. By this model, the geometric structure and the texture of human faces are linearly approximated as a combination of principal vectors.
Recently, the 3DMM model was combined with the convolutional neural networks for data augmentation. However, the generated samples tend to be smooth and unrealistic in appearance as you can observe in the figure below.

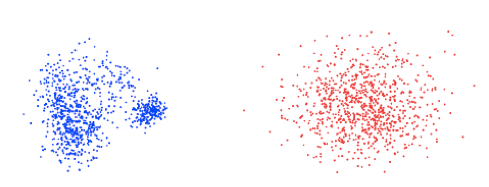
Moreover, 3DMM generates samples following a Gaussian distribution, which rarely reflects the true distribution of the data. For instance, see below the first two PCA coefficients plotted for real faces vs the synthesized 3DMM faces. This gap between the real and synthesized distributions may easily result in non-plausible samples.
State-of-the-art idea
Slossberg, Shamai, and Kimmel from Technion – Israel Institute of Technology propose a new realistic data synthesis approach for human faces by combining GAN and 3DMM model.
In particular, the researchers employ a GAN to imitate the space of parametrized human textures and generate corresponding facial geometries by learning the best 3DMM coefficients for each texture. The generated textures are mapped back onto the corresponding geometries to obtain new generated high-resolution 3D faces.
This approach produces realistic samples, and it:
- doesn’t suffer from indirect control over such desired attributes as pose and lighting;
- is not limited to producing new instances of existing individuals.
Let’s have a closer look at their data processing pipeline…
Data processing pipeline
The process includes aligning 3D scans of human faces vertex to vertex and mapping their textures onto a 2D plane using a predefined universal transformation.
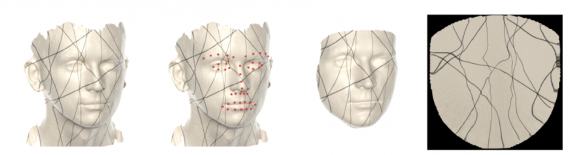
The data preparation pipeline contains four main stages:
- Data acquisition: the researchers collected about 5000 scans from a wide variety of ethnic, gender, and age groups; each subject was asked to perform five distinct expressions including a neutral one.
- Landmark annotation: 43 landmarks were added to the meshes semi-automatically by rendering the face and using a pre-trained facial landmark detector on the 2D images.
- Mesh alignment: this was conducted by deforming a template face mesh according to the geometric structure of each scan, guided by the previously obtained facial landmark points.
- Texture transfer: the texture is transferred from the scan to the template using a ray casting technique built into the animation rendering toolbox of Blender; then, the texture is mapped from the template to a 2D plane using the predefined universal mapping.
See the resulting mapped textures below:

The next step is to train GAN to learn and imitate these aligned facial textures. For this purpose, the researchers use a progressive growing GAN with the generator and discriminator constructed as symmetric networks. In this implementation, the generator progressively increases the resolution of the feature maps until reaching the output image size, while the discriminator gradually reduces the size back to a single output.
See below the new synthetic facial textures generated by the aforementioned GAN:

The final step is to synthesize the geometries of the faces. The researchers explored several approaches to finding plausible geometry coefficients for a given texture. You can observe the qualitative and quantitative (L2 geometric error) comparison between the various methods in the next figure:
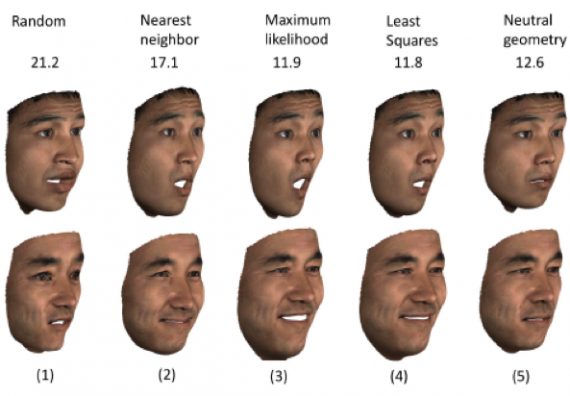
Apparently, the least squares approach produces the lowest distortion results. Considering also its simplicity, this method was chosen for all the subsequent experiments.
Experimental results
The proposed method can generate many new identities, and each one of them can be rendered under varying pose, expression, and lighting. Different expressions are added to the neutral geometry using the Blend Shapes model. The resulting images with different pose and lighting are shown below:


For quantitative evaluation of the results, the researchers used the sliced Wasserstein distance (SWD) to measure distances between distributions of their training and generated images in different scales:
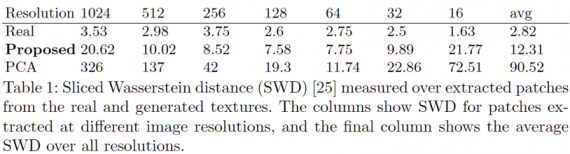
The table demonstrates that the textures generated by the proposed model are statistically closer to the real data than those generated by 3DMM.
The next experiment was designed to evaluate if the proposed model is capable of generating samples that diverge significantly from the original training set and resemble previously unseen data. Thus, 5% of the identities were held out for evaluation. The researchers measured the L2 distance between each real identity from the test set to the closest identity generated by the GAN, as well as to the closest real identity from the training set.
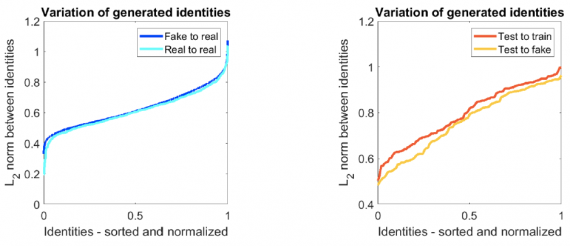
As it can be seen from the figure, the test set identities are closer to the generated identities than the training set identities. Moreover, the “Test to fake” distances are not significantly larger than the “Fake to real” distances. That implies that generated samples do not just produce IDs that are very close to the training set, but also novel IDs that resemble previously unseen examples.
Finally, a qualitative evaluation was performed to check if the proposed pipeline is able to generate original data samples. Thus, facial textures generated by the model were compared to their closest real neighbors in terms of L2 norm between identity descriptors.

As you can see, the nearest real textures are far enough to be visually distinguished as different people, which confirms the model’s ability to produce novel identities.
Bottom Line
The suggested model is probably the first to realistically synthesize both texture and geometry of human faces. It can be useful for training face detection, face recognition or face reconstruction models. In addition, it can be applied in cases where many different realistic faces are needed like for instance, film industry or computer games. Moreover, this framework is not limited to synthesizing human faces but can be actually employed to other classes of objects where alignment of the data is possible.












Post videos about it. In pictures it is not very informative.