DINO — инструмент от FAIR для самообучения современных моделей Visual Transformer. Фреймворк эффективно справляется с самостоятельным выделением важного содержимого на изображениях без лейблов. Код в открытом доступе.
Зачем это нужно
Сегментирование объектов на изображении помогает облегчить выполнение различных задач, от замены фона в видеочате до обучения роботов ориентации в окружающей среде. Это считается одной из самых сложных задач компьютерного зрения, поскольку требует, чтобы ИИ действительно понимал, что находится на изображении. Традиционно это достигается обучением с учителем и требует большого количества размеченных примеров. Но DINO показывает, что высокоточную сегментацию на самом деле можно выполнить с помощью самостоятельного обучения и подходящей архитектуры. Используя самообучение с инструментом Visual Transformer, DINO позволяет создание моделей, которые гораздо глубже понимают изображения и видео.
Как это работает
В основе архитектуры DINO лежит парадигма обучения, названная “дистилляция знаний”. Одновременно обучаются две модели, выполняющие роли ученика и учителя. И ученик, и учитель, получают на вход одно и то же изображение, слегка изменённое случайным образом. Модель-ученик обучается соответствовать ответам модели-учителя.
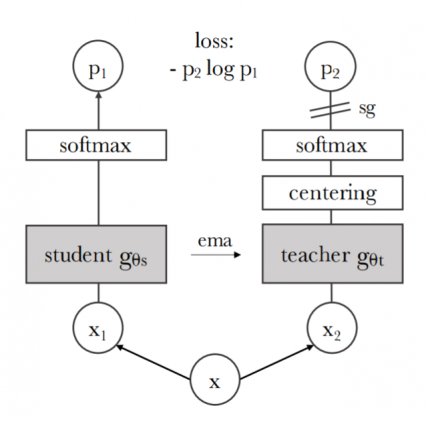
FAIR сумели адаптировать алгоритм дистилляции знаний под самообучение. На вход моделям подаются паттерны — случайные фрагменты изображения. Ученик получает как крупные паттерны, так и мелкие, а учитель — только крупные. Благодаря этому поощряется запоминание учеником взаимосвязи крупных и мелких паттернов. Обе модели имеют одинаковую архитектуру, но отличаются внутренними параметрами. Для подстройки параметров ученика используется стохастический градиентный спуск. Ключевой момент: модель-учитель строится на основании модели-ученика. Внутренние параметры учителя периодически плавно подстраиваются при помощи экспоненциального скользящего среднего.
В чём новшество
Кроме архитектурных нововведений, примечательно, что DINO многое узнает о визуальном мире. Обнаруживая закономерности в изображениях, модель запоминает пространство признаков, которое обладает явной структурой. Если при помощи DINO визуализировать категории объектов из популярного датасета ImageNet, можно увидеть, что похожие категории располагаются рядом друг с другом. Это говорит о том, что модели удаётся связать категории на основе визуальных свойств, подобно людям. Например, виды животных чётко разделены по структуре, напоминающей биологическую таксономию.