MinerU — open-source модель для извлечения данных из документов с точностью 93,5%
30 сентября 2024

MinerU — open-source модель для извлечения данных из документов с точностью 93,5%
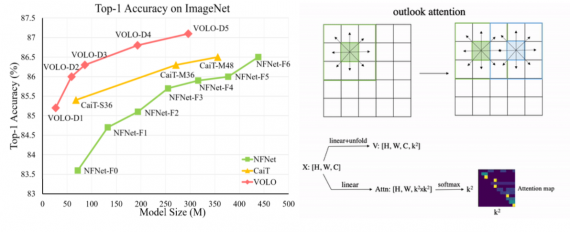
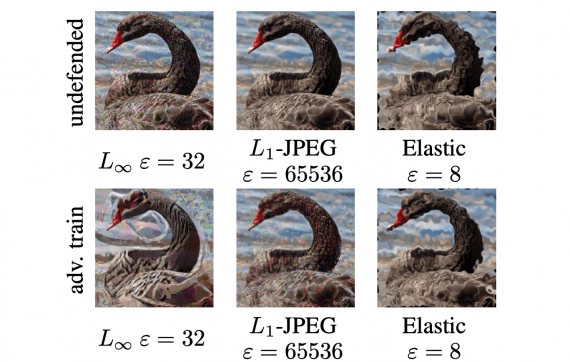
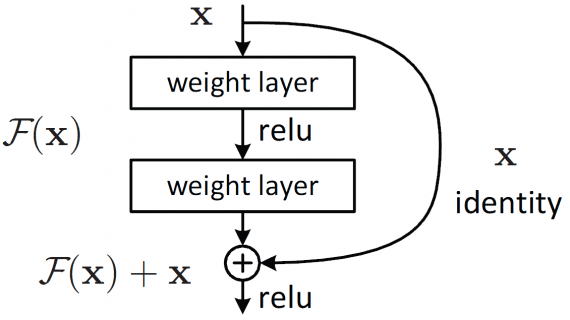
MinerU — open-source модель для извлечения и структурирования контента из документов, представленная исследователями из Лаборатории Искусственного Интеллекта Шанхая. MinerU автоматизирует извлечение текста, формул, таблиц и изображений из документов, таких как…