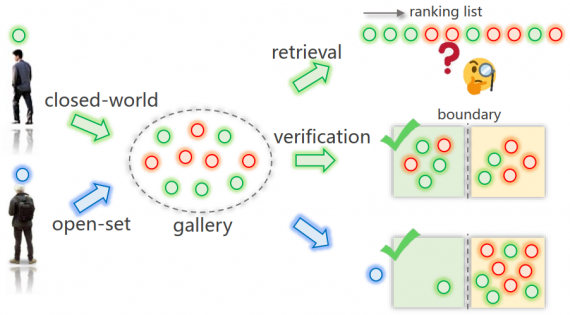
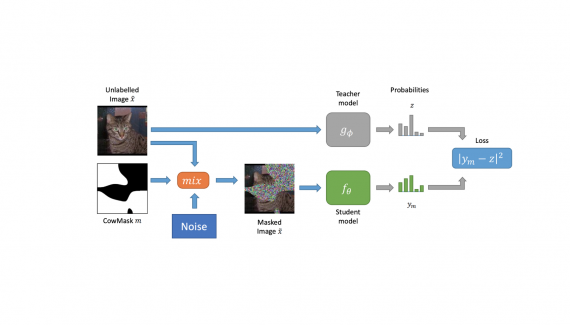
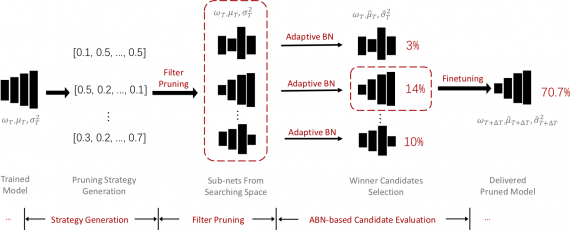
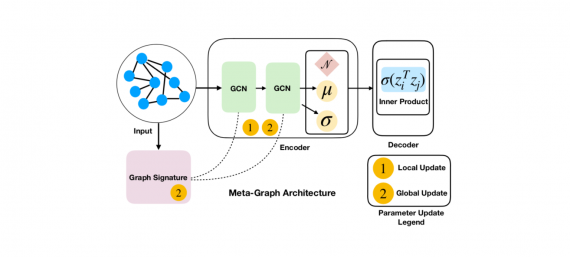
NBDT: интерпретируемые нейронные деревья решений
27 января 2021
NBDT: интерпретируемые нейронные деревья решений
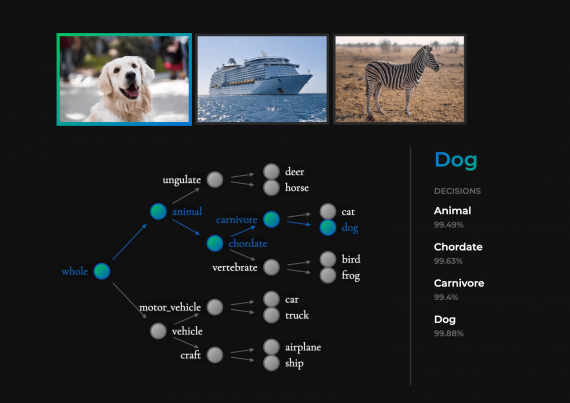
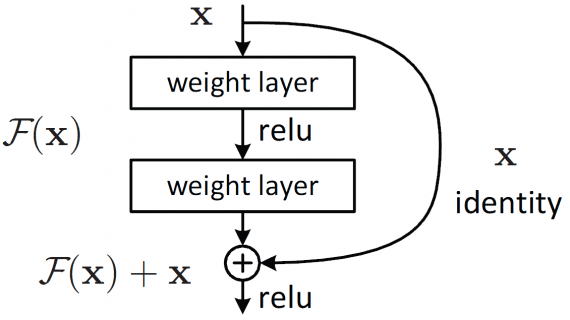
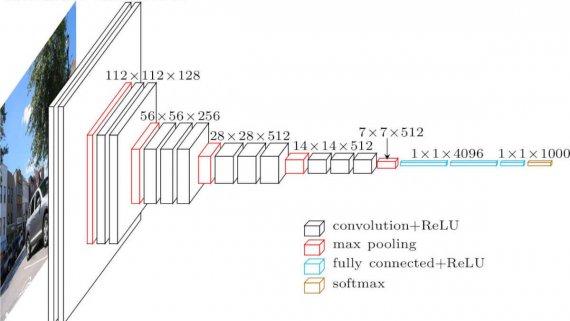
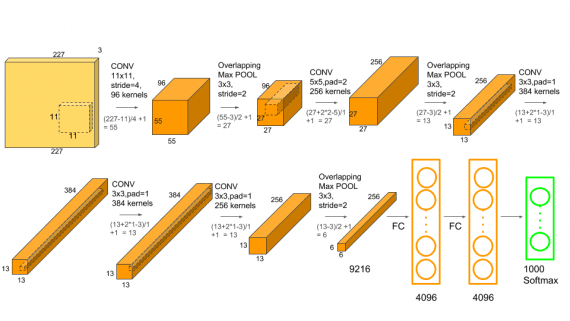
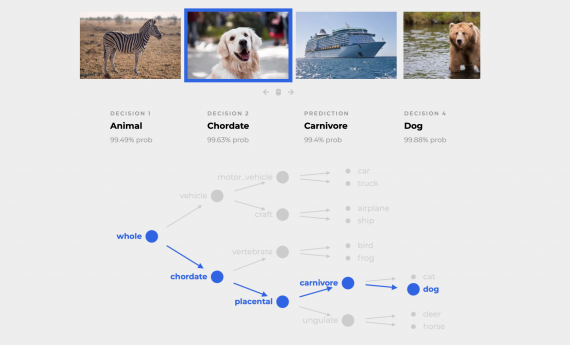
NBDT — это нейросетевая архитектура деревьев решений для задач классификации. Модель объединяет в себе интерпретируемость классического алгоритма дерева решений с качеством предсказаний современных нейросетей. Разработчики тестировали модель на задаче классификации…