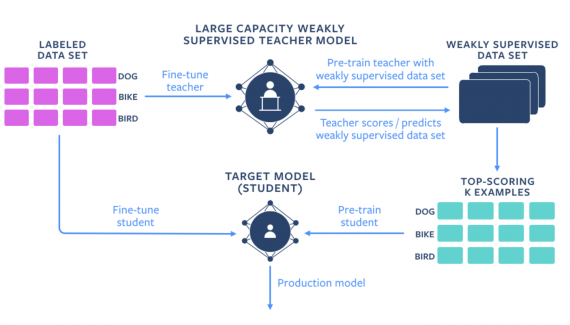
FAIR опубликовали новую модель для обучения представлений слов, — MOE. Misspelling Oblivious Embeddings (MOE) комбинирует в себе модель fastText и задачу по подбору наиболее близкого слова к слову с опечаткой.
Эмбеддинги — это представления слов или фраз в формате сжатых векторов, которые отражают их семантическое значение. Несмотря на то, что популярные методы эмбеддинга слов, — word2vec и GloVe, — выдают разумные результаты во время обучения, у них есть ряд ограничений. Модели не могут выдать эмбеддинг слову, которое не находилось в обучающем словаре (out-of-vocabulary words). Это наиболее важный недостаток, когда тексты содержат аббревиатуры, сленг или опечатки. Чтобы обойти этот недостаток, исследователи из FAIR предложили модель MOE.
MOE помещает в векторном пространстве слова с опечаткой близко к корректной форме слова. Это осуществляется с помощью обучения с учителем. fastText, на котором основана MOE, — это модель для эмбеддинга слов, которую также разработали в FAIR. Исследователи проверили работу MOE на разных задачах. Модель обошла fastText для текстов, которые были сгенерированы пользователями.
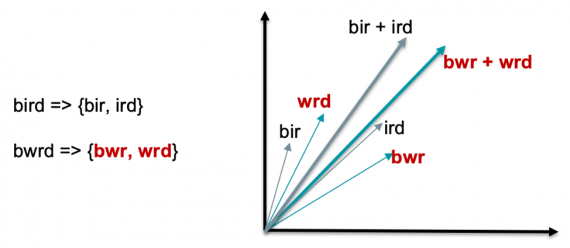
Как это работает
Функция потерь у fastText нацелена на расположение в пространстве слов, которые встречаются в одном контексте, близко друг к другу. Это называется семантической функцией потерь. Помимо семантической функции потерь, MOE также берет в расчет дополнительную функцию потерь классификатора (spell correction loss). Spell correction функция потерь имеет цель располагать в пространстве слова с опечаткой близко к верной форме слова. Это происходит через минимизацию взвешенной суммы семантической и spell correction функций потерь.
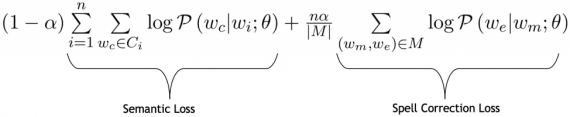
Исследователи опубликовали датасет с опечатками на английском языке, на котором обучалась MOE. Датасет включает в себя статьи из Wikipedia и содержит 20 миллионов примеров.
Чтобы оценить подход, необходимо было оценить, как близко слова с опечаткой находятся к верным формам слов. Ниже для примера представлены топ-6 самых близких слов к слову “samallest”.

Почему это имеет значение
Существующие методы для представления слов не справляются с неидеальными текстами, которые содержат слова не из словаря В реальных задачах входной текст генерируется человеком и часто содержит опечатки. Опечатки встречаются в 15% поисковых запросах.