Temporal Cycle-Consistency Learning (TCC) — это алгоритм для распознавания действий на видеозаписи. TCC обучается self-supervised. Одно из применений алгоритма — перенос звука с одной видеозаписи на другую. Код нейросети доступен публично.
Прошлые алгоритмы для анализа видеозаписей основывались на обучении с учителем. Однако задача распознавания содержания видео предполагает классификацию каждого кадра видеозаписи. Это ресурсоемкая в разметке задача. Исследователи из Google AI предложили self-supervised метод для распознавания содержания видео, — TCC. Подход использует соответствия между примерами схожих последовательных процессов, чтобы выучить представления частей видеозаписей.
Что внутри TCC
Действия, как, например, человек, наливающий в стакан воду, имеют четкую последовательной событий. Видеозаписи таких действий содержат в себе временные отсылки от кадра к кадру (temporal correspondences). У всех видеозаписей какого-то одного действия есть общие элементы последовательности событий. TCC пытается выучить такие общие временные отсылки в разных видео одного действия. Это происходит с помощью cycle consistency функции потерь.
Цель алгоритма — обучить кодировщик кадров. В качестве архитектуры использовалась ResNet. Чтобы обучить кодировщик, на вход кодировщику подавались все кадры видео. На выходе кодировщика получаются эмбеддинги кадров. Затем отбираются два видео для обучения TCC. Видео 1 (видео-отсылка) и видео 2. Выбирается кадр из видео-отсылки (видео 1) и для этого кадра находится эмбеддинг ближайшего кадра из видео 2. После того циклично для этого кадра из видео 2 ищется эмбеддинг ближайшего кадра из видео 1. Если отобранные эмбеддинги cycle-consistent, то ближайший эмбеддинг из видео 1 будет отсылать к изначально отобранному кадру.
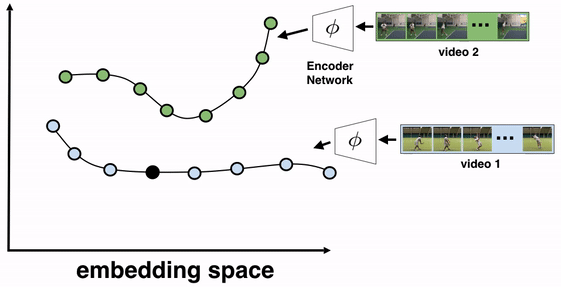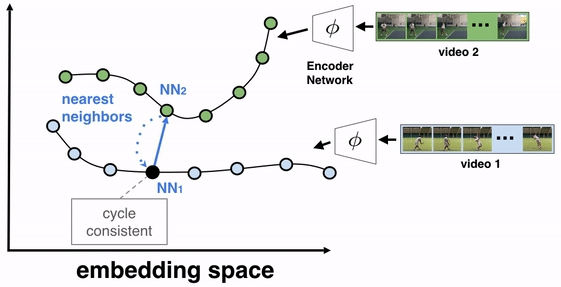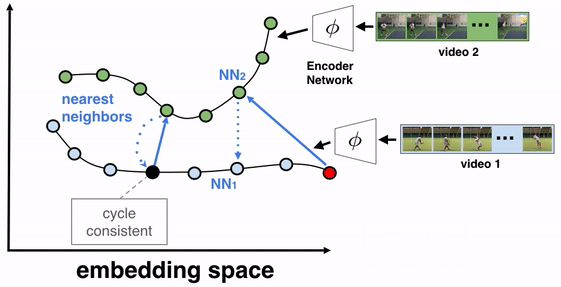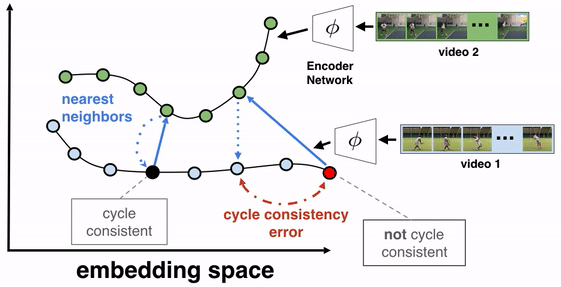
Кодировщик обучается так, чтобы cycle-consistency loss уменьшалась и эмбеддинги видеокадров лучше отражали семантическую близость кадров.
Где это можно применить
Так же, как TCC находит схожие кадры с использованием поиска ближайших соседей в пространстве эмбеддингов, алгоритм может переносить метаданные между семантически схожими кадрами. Эти метаданные могут быть в формате временных семантических лейблов или в другом формате (звук или текст). В видео ниже — два примера переноса звука из одного видео в другое.