Исследователи из Glint Lab, AIM for Health Lab и MVP Lab опубликовали LLaVA-OneVision-2 (LLaVA-OV-2) — мультимодальную модель нового поколения, которая переосмысливает то, как нейросеть «смотрит» видео. Вместо того чтобы нарезать видео на равномерные кадры, модель анализирует сжатый видеопоток через кодек и самостоятельно определяет, на каких фрагментах сосредоточить внимание. LLaVA-OV-2 умеет отвечать на вопросы по видео, локализовать события во времени (temporal grounding), отслеживать объекты между кадрами (video object tracking), рассуждать о пространственных отношениях в 2D и 3D сценах, а также работать с обычными изображениями и документами. Всё это одна архитектура без отдельных декодеров под каждую задачу. Проект полностью открытый: код доступен на GitHub, датасеты — на Hugging Face, где также доступны веса модели.
Почему равномерная выборка кадров не работает
Большинство существующих мультимодальных языковых моделей (MLLM) работают с видео одинаково: берут видеофайл, вырезают из него 8–32 равномерно распределённых кадра и передают их в энкодер. Всё остальное выбрасывается. Это создаёт очевидную проблему: если в видео происходит что-то важное между двумя отобранными кадрами, модель это просто пропустит.
Авторы предлагают другой подход. Видеокодеки вроде H.264 и H.265/HEVC уже содержат информацию о том, где в видео происходят изменения: I-кадры (ключевые кадры) несут полное изображение сцены, а P-кадры кодируют только разницу между соседними кадрами через векторы движения и остаточный сигнал. Именно там, где P-кадры «дорогие» по битрейту, и происходит что-то интересное.
Как устроена codec-stream токенизация
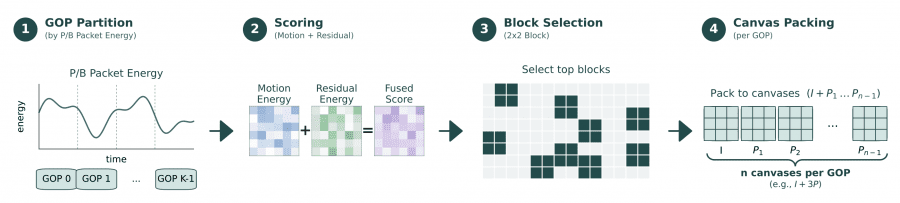
Ключевое нововведение LLaVA-OV-2 — это codec-stream токенизация. Она работает в четыре этапа, которые авторы назвали GOP Partition, Scoring, Block Selection и Canvas Packing.
Сначала видео разбивается на адаптивные группы кадров (Groups of Pictures, GOP) не по времени, а по накопленному битрейту P/B-кадров. Если в каком-то участке видео битрейт резко растёт, значит, там происходит быстрое движение или смена сцены и граница GOP устанавливается там. Потом для каждой группы вычисляется карта значимости: каждый блок 2×2 патча получает оценку, складывающуюся из нормализованной величины вектора движения и нормализованного остаточного яркостного сигнала. Блоки с высокой оценкой отбираются и упаковываются в компактные канвасы (canvases) по одному I-канвасу и нескольким P-канвасам на группу.
В результате модель тратит больше токенов на динамичные участки видео и меньше на те, где ничего не меняется. Это принципиально отличается от равномерной выборки, где бюджет токенов расходуется одинаково на информативные и на малосодержательные участки.
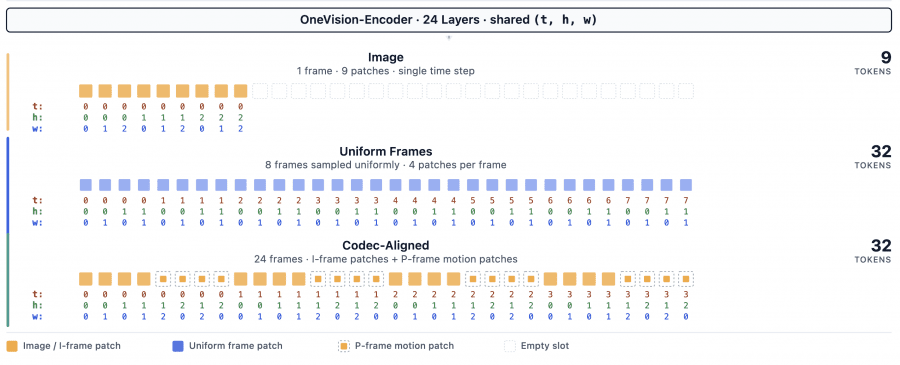
Все входные данные: видео через кодек, видео с равномерной выборкой и статичные изображения, — обрабатываются единым энкодером OneVision-Encoder с нативным разрешением и трёхмерным позиционным кодированием (3D RoPE). Далее лёгкий двуслойный MLP-коннектор проецирует визуальные эмбеддинги в пространство языковой модели, а декодирование выполняет Qwen3-8B.
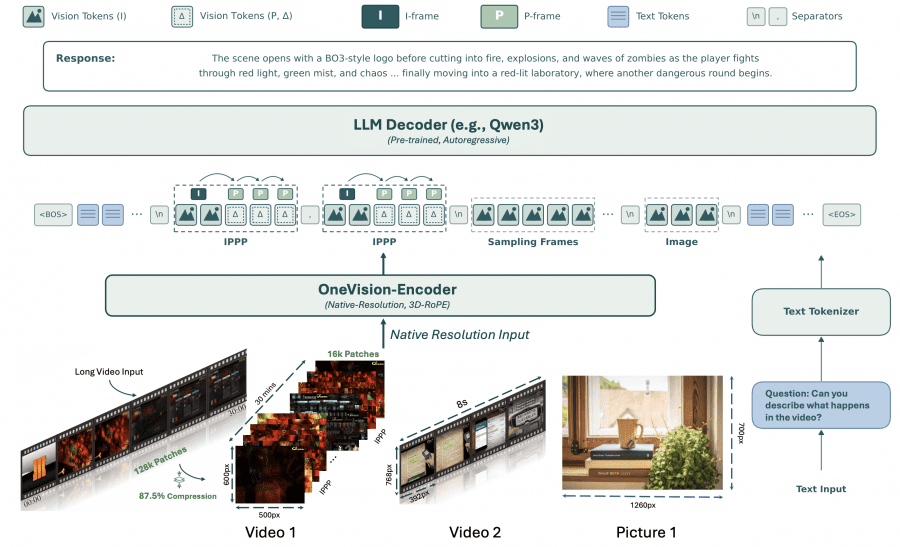
Как модель обучали
Обучение проходило в четыре этапа. На первом модель инициализировали из LLaVA-OneVision-1.5 и добавили 4,2 млн коротких (до 30 секунд) видеопар. На втором добавили масштабные инструкционные данные (~22 млн и ~24 млн сэмплов) и видео до 3 минут. На третьем этапе максимальное число кадров выросло до 384, а в обучение добавили видео длиной 10–15 минут. На четвёртом этапе включили codec-stream токенизацию для длинных видео (384 и 768 кадров) и добавили 4 млн пространственных вопросно-ответных пар в датасете LLaVA-OneVision-2-Spatial-4M.
JumpScore: новый бенчмарк для трудных случаев
Авторы также предложили собственный бенчмарк JumpScore, который закрывает важный пробел в существующих оценках. Датасет опубликован на Hugging Face. Большинство бенчмарков на temporal grounding (локализацию событий во времени) проверяют, может ли модель найти событие, когда соседние кадры визуально непохожи. JumpScore ставит обратную задачу: найти конкретный момент среди множества визуально почти одинаковых циклов. В нём 189 видео со скакалкой, где нужно точно указать начало каждого прыжка с точностью до 0,1–0,3 секунды. Медианный период цикла — около 0,4 секунды, поэтому ошибка в 0,1 секунды означает, что модель почти угадала правильный цикл.
Результаты: на сколько баллов модель обходит конкурентов
LLaVA-OV-2-8B сравнивали с четырьмя моделями того же класса (8 млрд параметров): Qwen3-VL-8B, Keye-VL-1.5-8B, InternVL-3.5-8B и LLaVA-OV-1.5-8B. Наибольший отрыв — на JumpScore (+44,8 пункта над Qwen3-VL) и на задачах temporal grounding и пространственного рассуждения. На большинстве остальных бенчмарков модель лидирует или держится в топ-2.
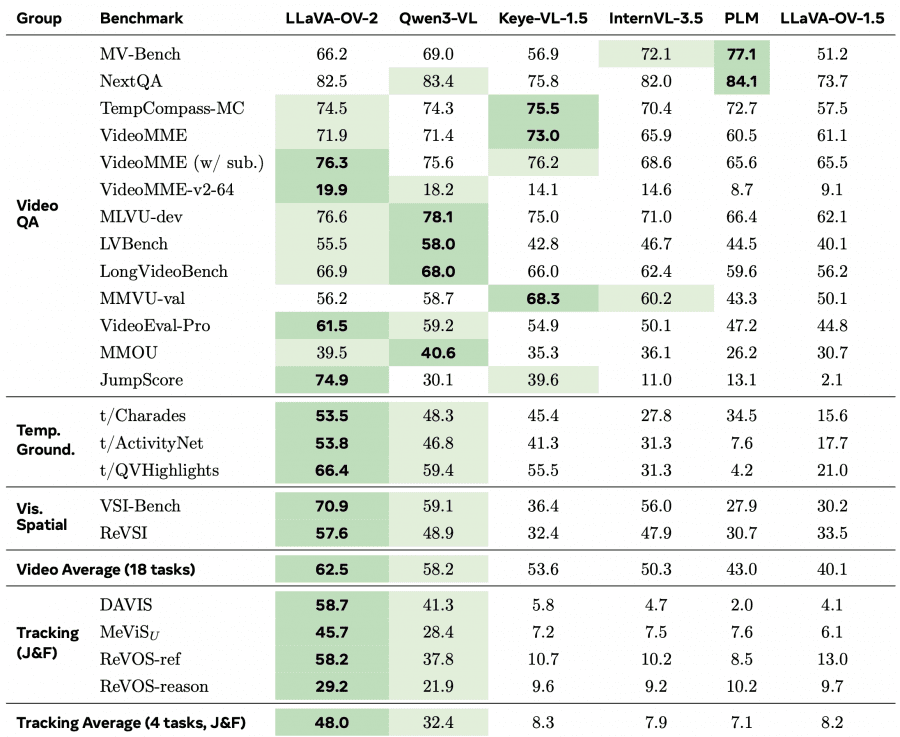
По трекингу видеообъектов модель тоже впереди: средний J&F составляет 48,0 против 32,4 у Qwen3-VL. При этом отдельной головы сегментации нет — модель предсказывает координаты точек (x, y) для каждого кадра, а затем передаёт их в SAM 2 как подсказки для построения масок.
Где codec лучше, где хуже равномерной выборки
Авторы тщательно проверили, в каких задачах codec-stream токенизация действительно помогает, а где равномерная выборка кадров справляется лучше или не хуже.
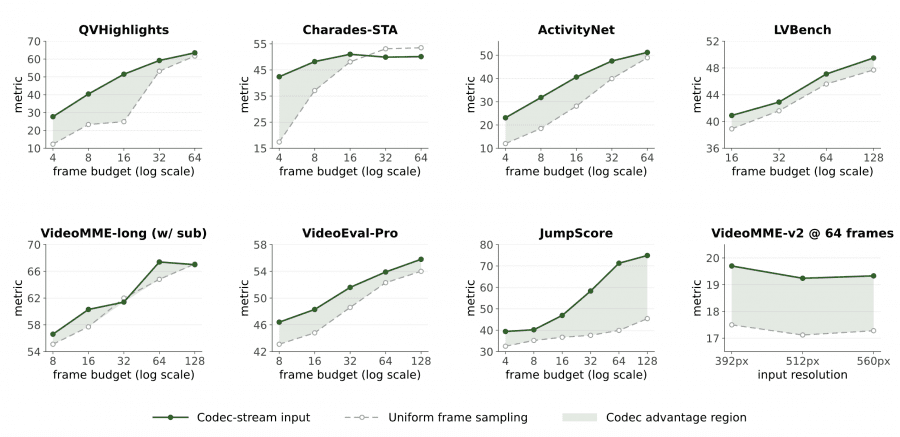
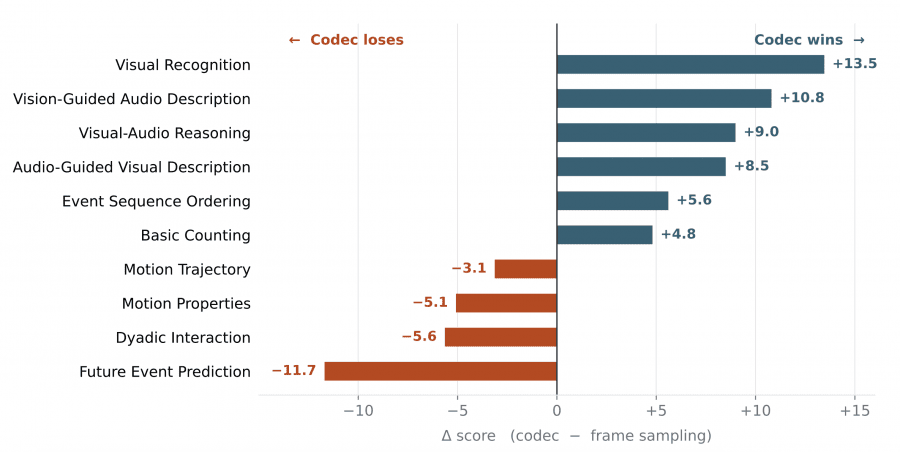
Codec-stream токенизация даёт наибольший прирост там, где ответ зависит от конкретного момента события: temporal grounding (+9,7 пункта в среднем), JumpScore (+17,3 пункта в среднем по всем бюджетам кадров), распознавание событий и подсчёт объектов. На задачах по длинным видео (VideoMME-Long, LVBench, VideoEval-Pro) codec сохраняет паритет или даёт небольшой плюс — то есть не теряет семантического понимания ради компрессии.
Равномерная выборка остаётся предпочтительной для задач, требующих непрерывного анализа траекторий: предсказание будущих событий, отслеживание деталей движения, взаимодействие двух людей в кадре. Там, где нужна плотная последовательность кадров для мелкотекстурных деталей, codec пропускает часть информации.
Пример работы: JumpScore при 128 кадрах
Авторы демонстрируеют показательный пример на клипе с 85 циклами прыжков. При равномерной выборке 128 кадров модель правильно определяет 14 из 85 циклов (mAP 0,116). При codec-stream выборке с тем же бюджетом токенов — 82 из 85 (mAP 0,894). Разница в 7,7 раза объясняется именно тем, что codec концентрирует токены на границах циклов, где битрейт и остаточный сигнал максимальны.
Что это означает
LLaVA-OV-2 показывает, что принцип codec-stream токенизации — не просто очередной способ сжать токены, а другой взгляд на то, что значит «смотреть» видео. Ключевой вывод авторов: кодек и равномерная выборка не конкуренты, а взаимодополняющие инструменты. Codec лучше там, где важны события; равномерная выборка лучше там, где важна непрерывность. Оба режима поддерживаются единой архитектурой без дополнительных адаптеров.
Авторы планируют развивать этот подход в сторону потоковой обработки видео и работы с видео длиной в часы, где визуальные свидетельства нужно постоянно обновлять, сжимать и извлекать из памяти по мере поступления нового контента.









