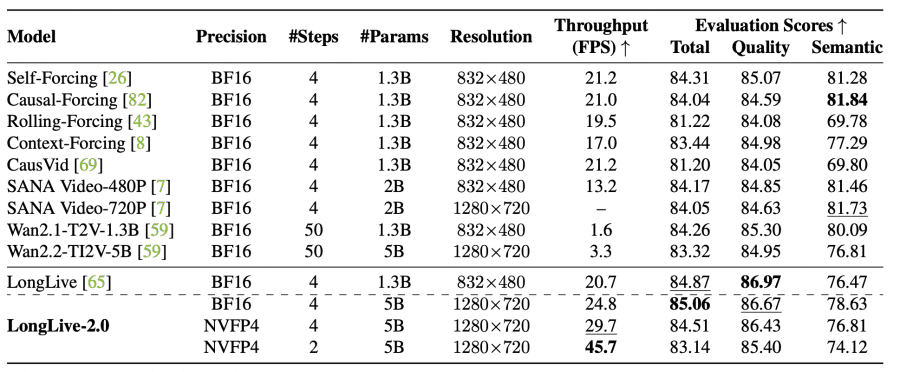
Исследователи из NVIDIA опубликовали LongLive-2.0 — инфраструктуру для обучения и запуска моделей генерации длинного видео с использованием квантования до 4-битной точности NVFP4. Квантование — это сжатие весов модели за счёт уменьшения разрядности чисел: BF16 хранит каждое число в 16 битах, NVFP4 сжимает их до 4 бит, поэтому модель занимает меньше памяти и быстрее считает. Теоретически это должно снижать качество генерации, но авторы показывают, что на практике результаты почти не отличаются от BF16. Главный результат: модель на 5 миллиардов параметров генерирует видео в разрешении 1280×720 со скоростью 45.7 кадров в секунду — это первый случай применения NVFP4 сквозь весь цикл обучения и инференса для генерации длинного видео. По сравнению с BF16-базой обучение ускорилось в 2.15 раза, а инференс — в 1.84 раза. Проект полностью открытый: веса модели, код и датасеты доступны на GitHub и Hugging Face.

Зачем вообще нужна новая инфраструктура
Генерация длинного видео — это задача, где модель должна последовательно создавать видеофрагменты, сохраняя согласованность сцен и персонажей на протяжении минут экранного времени. Проблема в том, что чем длиннее видео, тем больше видеопамяти (VRAM) нужно GPU и тем медленнее работает модель. До сих пор большинство работ в этой области фокусировались на алгоритмах, почти игнорируя инфраструктурную сторону.
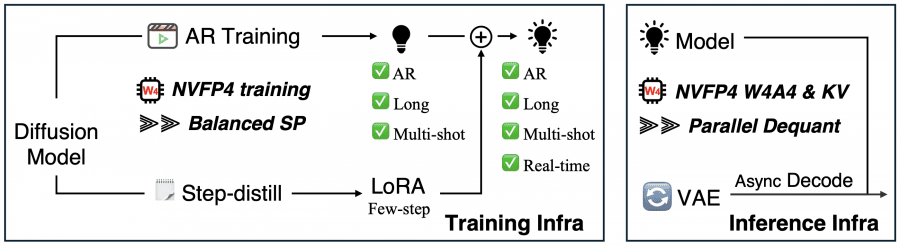
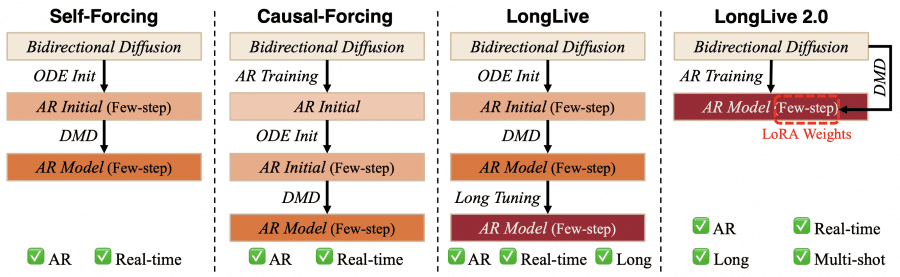
Существующие подходы, вроде Self-Forcing и Causal-Forcing, опираются на сложный многоступенчатый пайплайн обучения: сначала ODE-инициализация (метод решения дифференциальных уравнений для старта обучения), затем DMD (дистилляция с согласованием распределений), и только потом дополнительный этап обучения на длинных видео. LongLive-2.0 убирает эту сложность.
Ключевые компоненты LongLive-2.0
Авторы выделяют три главных технических решения:
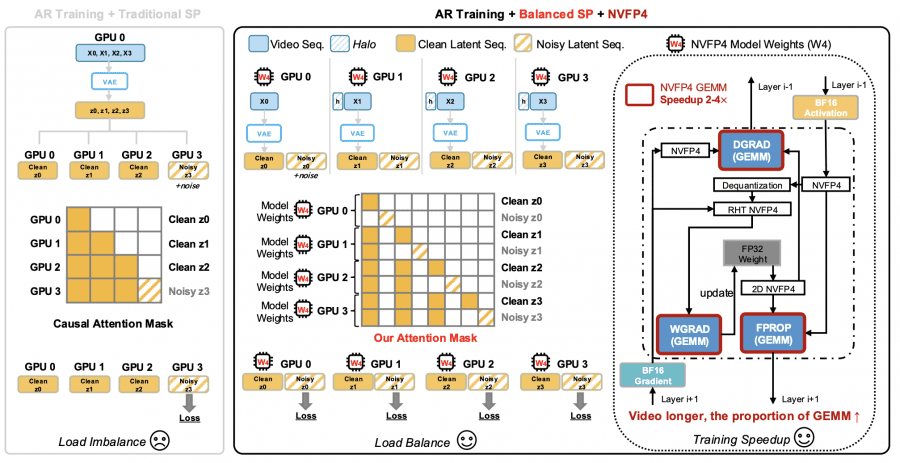
Balanced SP (сбалансированный параллелизм по последовательности). Стандартный sequence parallelism при авторегрессионном обучении на видео создаёт дисбаланс: одни GPU получают преимущественно «чистые» токены истории, другие — «зашумлённые» целевые токены. Это неравномерно распределяет вычислительную нагрузку. Balanced SP решает это за счёт того, что каждый GPU получает как чистые, так и зашумлённые токены из одного и того же временного фрагмента. Кроме того, каждый GPU самостоятельно кодирует только свой кусок видео через VAE (вариационный автоэнкодер), а не всё видео целиком, что снижает избыточные вычисления.
NVFP4-квантование. NVFP4 — формат с 4-битной плавающей точкой от NVIDIA, нативно поддерживаемый на GPU архитектуры Blackwell (GB200). Каждый элемент тензора хранится в формате E2M1 (2 бита на экспоненту, 1 бит на мантиссу) плюс иерархические масштабирующие коэффициенты: блочный (на каждые 16 элементов) и тензорный. Это важно: в отличие от обычного целочисленного квантования INT4, NVFP4 использует неравномерные шаги между значениями, что даёт лучшую точность для малых чисел. Квантование применяется к весам и активациям линейных слоёв DiT (Diffusion Transformer), а градиенты весов дополнительно проходят через RHT (случайное преобразование Адамара) для стабилизации обучения.
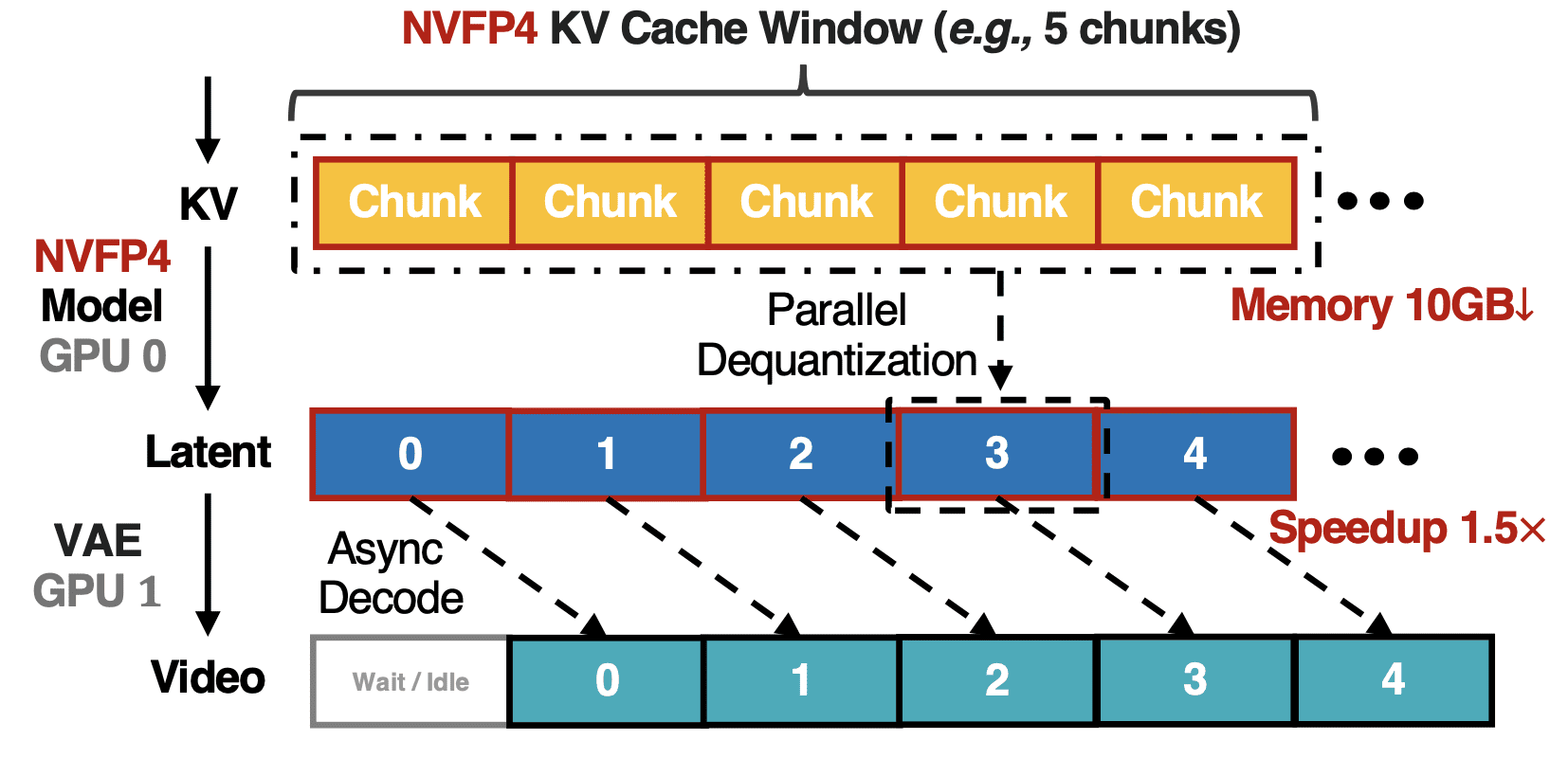
Асинхронное потоковое декодирование VAE. В базовой версии модель сначала генерирует все латентные (скрытые) представления, и только потом декодирует их в пиксели через VAE. LongLive-2.0 запускает декодирование каждого фрагмента параллельно с денойзингом (диффузным восстановлением) следующего фрагмента на отдельном GPU. Поскольку денойзинг обычно занимает больше времени, чем декодирование, VAE-часть практически полностью «прячется» за вычислениями DiT.
Пайплайн обучения стал проще
Ключевое архитектурное решение LongLive-2.0 — возможность отказаться от сложного многоступенчатого обучения. Авторы берут готовую двунаправленную диффузионную модель Wan2.2-TI2V-5B и напрямую дообучают её на длинных multi-shot видео с AR-целевой функцией (авторегрессионной). Никакой ODE-инициализации, никакого промежуточного DMD на коротких видео.
После этого единственного этапа дообучения получается AR-модель, поддерживающая длинные multi-shot видео с 4 шагами денойзинга. Чтобы получить версию с 2 шагами (реальное время), поверх замороженной основы обучаются только LoRA-адаптеры (Low-Rank Adaptation — метод дообучения малой части параметров). Эти веса можно подключать к любой модели семейства Wan2.2-TI2V-5B.
Как работает инференс: KV-кэш и якоря внимания (attention sinks)
При авторегрессионной генерации модель держит в памяти KV-кэш (кэш ключей и значений внимания) всех уже сгенерированных фрагментов. Для длинного видео это быстро становится узким местом по памяти. LongLive-2.0 квантует KV-кэш в NVFP4 прямо во время генерации, достигая практически 3.6-кратного сжатия.
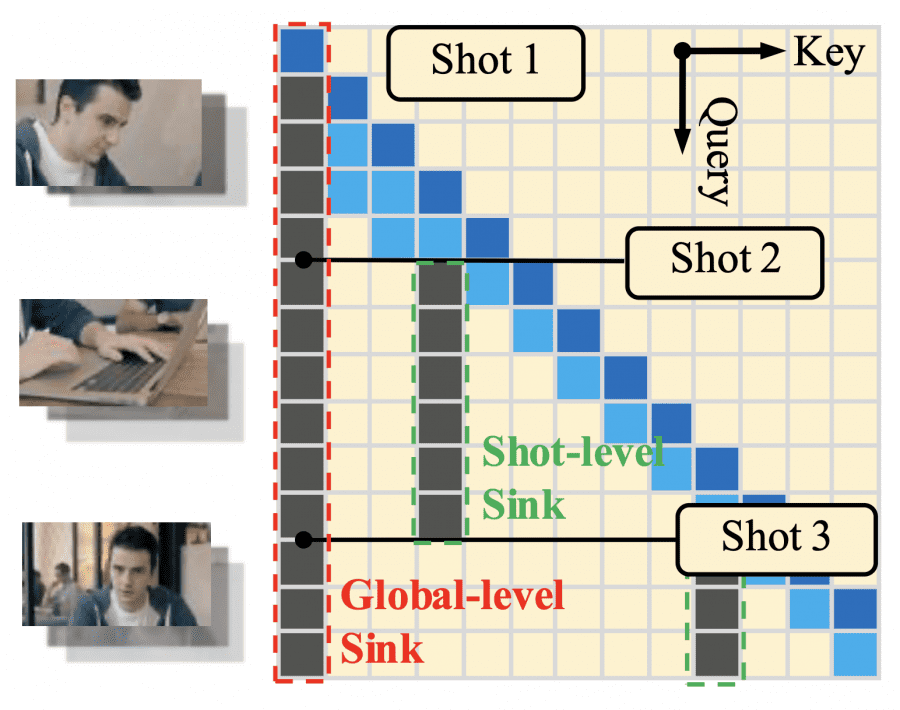
Для поддержания согласованности при скользящем окне внимания авторы вводят двухуровневые «якоря» (attention sinks):
первые несколько кадров всего видео (глобальный якорь) фиксируются навсегда, а первые несколько кадров текущего кадра (локальный якорь) переопределяются при каждой смене сцены. Это позволяет модели не терять ни глобальную идентичность персонажей, ни локальную согласованность внутри шота.
Рещультаты: насколько это быстро и точно
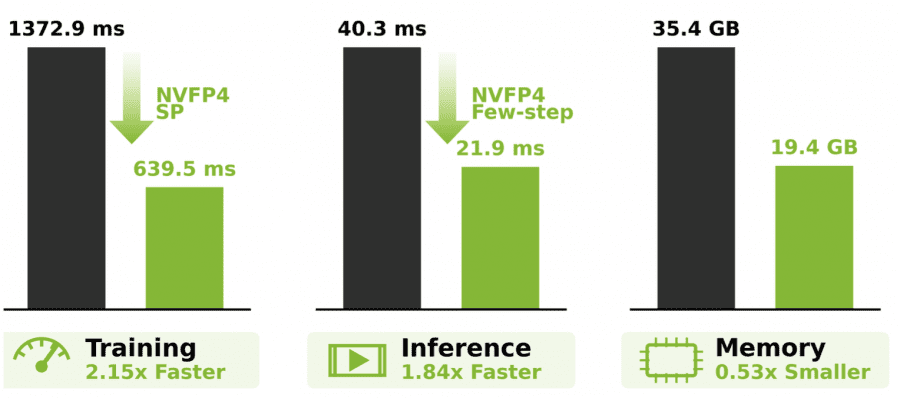
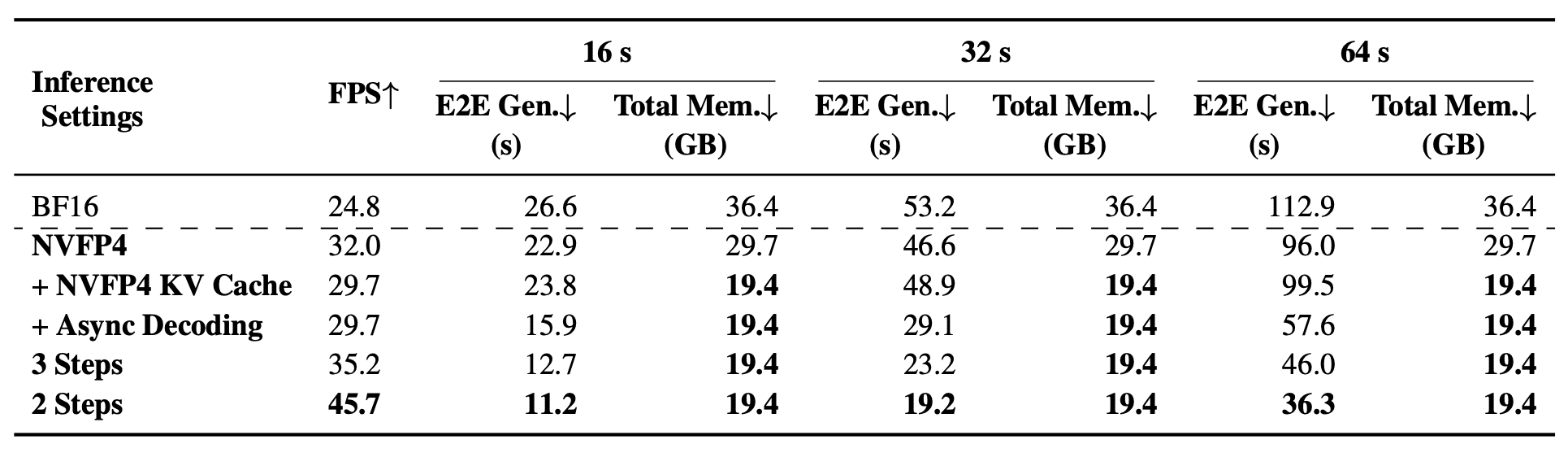
На видео длиной 64 секунды BF16-версия без параллелизма вообще не помещается в память (out of memory). С BF16 и стандартным sequence parallelism одна итерация обучения занимает 1372.9 секунды. Balanced SP снижает это до 1196.5 секунды. Добавление NVFP4 опускает цифру до 639.5 секунды — это тот самый прирост 2.15×, о котором говорят авторы.
При инференсе модель с двумя шагами денойзинга генерирует 64-секундное 720p-видео за 36.3 секунды, занимая при этом 19.4 ГБ видеопамяти. Для сравнения, BF16-версия с 4 шагами требовала 112.9 ГБ памяти.
На бенчмарке VBench-Long (генерация 60-секундных видео) LongLive-2.0 занимает первое место по среднему рангу среди всех сравниваемых методов — 3.67 против 4.17 у оригинального LongLive. Особенно сильные показатели по согласованности субъекта (97.48%) и фона (97.00%) — это значит, что персонажи и окружение практически не «плывут» на протяжении всего видео.
Ограничения
Авторы честно указывают главное ограничение: ускорение от NVFP4 при инференсе работает только на GPU архитектуры Blackwell (например, GB200). На A100 (Ampere) и H100 (Hopper) нативной аппаратной поддержки NVFP4 нет. Для таких GPU предлагается sequence parallelism как альтернатива для ускорения — это позволяет достичь сопоставимой скорости, но уже через параллелизацию по нескольким GPU, а не через низкоразрядное квантование.
Иными словами, чтобы получить 45.7 FPS на одной карте, нужен GB200. На старом железе потребуется либо несколько GPU, либо мириться с более низкой скоростью.








