LongLive-2.0: NVIDIA научила модель генерировать длинное видео в реальном времени с квантованием NVFP4
20 мая 2026

LongLive-2.0: NVIDIA научила модель генерировать длинное видео в реальном времени с квантованием NVFP4
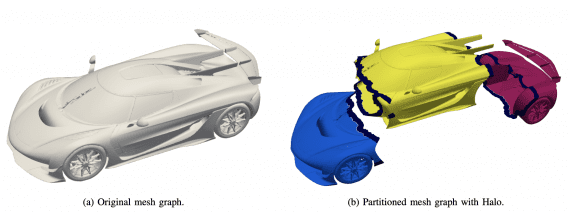
Исследователи из NVIDIA опубликовали LongLive-2.0 — инфраструктуру для обучения и запуска моделей генерации длинного видео с использованием квантования до 4-битной точности NVFP4. Квантование — это сжатие весов модели за счёт…