LFM2.5-230M: ультракомпактная модель работает на Raspberry Pi и почти любом современном телефоне
29 июня 2026

LFM2.5-230M: ультракомпактная модель работает на Raspberry Pi и почти любом современном телефоне
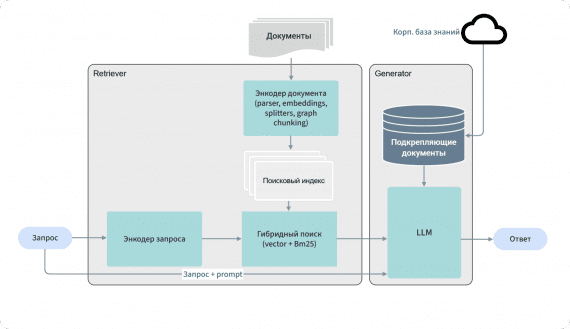
Команда Liquid AI выпустила LFM2.5-230M — одну из самых маленьких языковых моделей на сегодня, всего на 230 миллионов параметров. Она настолько компактная, что без проблем запускается на небольшом устройстве: ей…