Tokyo 7-Eleven Store Is Testing a “Pay With Your Face” System
20 December 2018

Tokyo 7-Eleven Store Is Testing a “Pay With Your Face” System
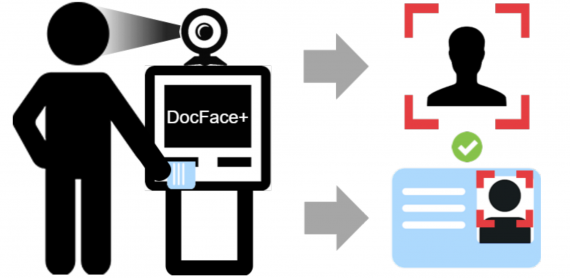
Japan’s largest convenience store, 7-Eleven has tested a facial recognition system for cashless payment at their stores. 7-Eleven has opened up a trial store in Tokyo’s Minato Ward which is…