
Nowadays, it is pretty common for people to share their pictures on social media. A large percentage of them featuring people-centric content. There is little doubt that realistic face retouching algorithms are a growing research topic within the computer vision and machine learning communities. Some examples include red-eye fixing, blemish removal, where patch matching and Poisson blending have been used to create plausible-looking results. However, humans are very sensitive to small errors in facial structure, especially if those faces are our own or are well-known to us; moreover, the so-called “uncanny valley” is a difficult impediment to cross when manipulating facial features.
Recently, deep convolutional networks (DNNs) have produced high-quality results when in-painting missing regions of pictures showing natural scenery. For the particular problem of facial transformations, they learn not only to preserve features such global lighting and skin tone (which patch-like and blending techniques can also potentially preserve), but can also encode some notion of semantic plausibility.
In this study, FAIR focus on the problem of eye in-painting. While DNNs can produce semantically plausible, realistic-looking results, most deep techniques do not preserve the identity of the person in a photograph. For instance, a DNN could learn to open a pair of closed eyes, but there is no guarantee encoded in the model itself that the new eyes will correspond to the original person’s specific ocular structure. Instead, DNNs will insert a pair of eyes that correspond to similar faces in the training set, leading to undesirable and biased results; if a person has some distinguishing feature (such as an uncommon eye shape), this will not be reflected in the generated part.
Generative adversarial networks (GANs) are a specific type of deep network that contains a learnable adversarial loss function represented by a discriminator network. GANs have been successfully used to generate faces from scratch or to in-paint missing regions of a face. They are particularly well-suited to general facial manipulation tasks, as the discriminator uses images of real faces to guide the generator network into producing samples that appear to arise from the given ground-truth data distribution.
The architecture of an Exemplar GAN (ExGAN)
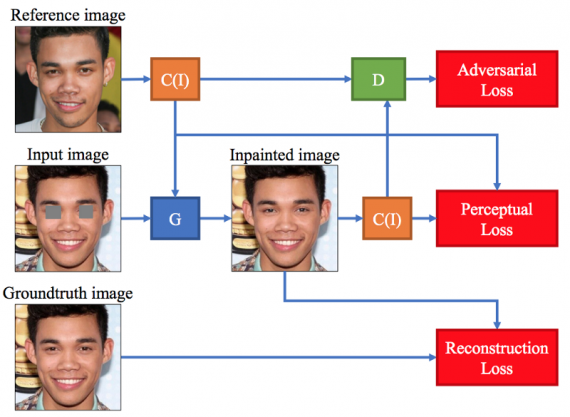
Instead of relying on the network to generate images based only on data seen in the training set, ExGANs use a second source of related information to guide the generator as it creates an image. As more datasets are developed and more images are made available online, it is reasonable to assume that the second image of a particular object exists at inference time. For example, when in-painting a face, the reference information could be a second image of the same person taken at a different time or in a different pose. However, instead of directly using the exemplary information to produce an image (such as using nearby pixels for texture synthesis, or by copying pixels directly from a second photograph), the network learns how to incorporate this information as a semantic guide to producing perceptually-plausible results. Consequently, the GAN learns to utilize the reference data while still retaining the characteristics of the original photograph.
FAIR scientists presented two separate approaches to ExGAN in-painting. The first is reference-based in-painting, in which a reference image ri is used in the generator as a guide, or in the discriminator as additional information when determining if the generated image is real or fake. The second approach is code-based in-painting, where a perceptual code ci is created for the entity of interest. For eye in-painting, this code stores a compressed version of a person’s eyes in a vector ci ∈ R N , which can also be used in several different places within the generative and discriminator networks.
Reference image in-painting: Assume that for each image in the training set xi, there exists a corresponding reference image ri . Therefore the training set X is defined as a set of tuples X = {(x1, r1), . . . , (xn, rn)}. For eye in-painting, ri is an image of the same person in xi , but potentially taken in a different pose. Patches are removed from xi to produce zi , and the learning objective is defined as:
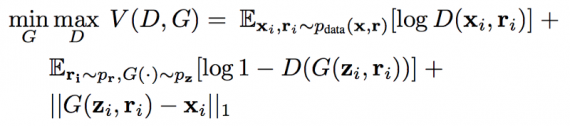
For better generalization, a set of reference images Ri corresponding to a given xi can also be utilized, which expands the training set to the set of tuples comprised of the Cartesian product between each image-to-be-in-painted and its reference image set, X = {x1 × R1, . . . , xn × Rn}
Code in-painting: For code-based in-painting, and for datasets where the number of pixels in each image is |I|, assume that there exists a compressing function C(r) : R ^|I| → R ^N , where N <<|I|. Then, for each image to be in-painted zi and its corresponding reference image ri , a code ci = C(ri) is generated using a ri . Given the codified exemplary information, we define the adversarial objective as:
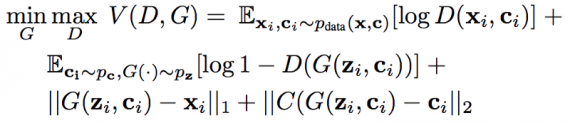
The above equation is an optional loss that measures the distance of the generated image G(zi , ci) to the original reference image ri.
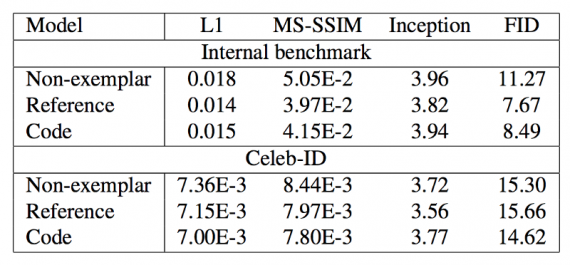
The below table shows the quantitative results for the 3 best GAN models. For all metrics except inception score, lower is better.
Exemplar GANs provide a useful solution for image generation or in-painting when a region of that image has some sort of identifying the feature. They provide superior perceptual results because they incorporate identifying information stored in reference images or perceptual codes. A clear example of their capabilities is demonstrated by eye in-painting. Because Exemplar GANs is a general framework, they can be extended to other tasks within computer vision, and even to other domains.
Results
Comparison between (a) ground truth (the left column), (b) non-exemplar and (c, d) exemplar-based results. An ExGAN that uses a reference image in the generator and discriminator is shown in column c, and an ExGAN that uses a code is shown in the right column (d):



Closed-eye-opening results generated with a reference-based Exemplar GAN. The left column is the reference image, and the right column is the in-painted version of the images in the middle column generated with an Exemplar GAN:







