
Нейросети критичны к объемам выборки, которая необходима для обучения. Большие датасеты далеко не так доступны, как хотелось бы разработчикам. На сбор информации уходит много времени, это дорого, и полученные данные не всегда точны. Поэтому много проектов сегодня посвящены исключительно работе над созданием датасетов.
Датасет “Falling Things”
В NVidia проблема сбора решена благодаря использованию синтетически сгенерированных данных. Синтетический датасет — это производные данные, применимые к заданной ситуации, которые не получены посредством измерений. Разработчики использовали синтетические датасеты для тренировки глубоких нейронных сетей, которым нужны опорные данные для сегментации и оценки положения объекта в трёхмерном пространстве.
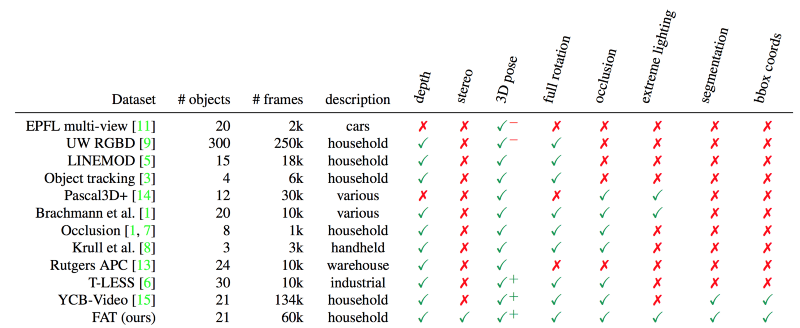
Falling Things (FAT) состоит из 61 000 изображений для обучения и проверки алгоритмов распознавания изображения в бытовой среде. Кроме него существует только два набора с точными опорными данными по положению множественных объектов: T-LESS и YCB-Video. Но в них нет примеров с экстремальными условиями освещения и несколькими модальностями. В FAT такие примеры есть.

Unreal Engine
FAT работает с помощью Unreal Engine 4 (UE4). Данные генерируются для трех виртуальных локаций: кухня, солнечный храм и лес. Локации были выбраны из-за их достоверного моделирования в UE4 и для разнообразия. Для каждой среды вручную выбрано пять мест с разным рельефом и освещением, например: на кухонном столе или плиточном полу, рядом со скалой, над травой и т. д. Таким образом, получаются 15 локаций с не повторяющимся трехмерным фоном, условиями освещения и тенями.
Из YCB взяли 21 бытовой предмет. Предметы размещались в случайных положениях в вертикальном цилиндре радиусом 5 см и высотой 10 см. Для сбора данных, по мере того как объекты падали, объектив виртуальной камеры снимал объекты с разных координат (углы возвышения и азимуты относительно цилиндра). Азимут варьировался от -120◦ до 120◦ (чтобы “увернуться” от стены в тех случаях, где она была), углы возвышения от 5 до 85◦ и расстояние от 0,5 м до 1,5 м.
Виртуальная камера, используемая для генерации данных, состоит из пары стереофонических RGBD-камер. Такое решение позволяет поддерживать по меньшей мере три модальности датчиков. Хотя одиночные датчики RGBD широко применяются в робототехнике, стереодатчики дают меньшее количество искажений, а монокулярной камеры RGB есть очевидные преимущества с точки зрения стоимости, простоты и доступности.
Датасет FAT состоит из 61 500 изображений с разрешением 960 x 540 и разделен на две части:
Одиночные объекты: первая часть набора сгенерирована путем “бросания” каждого предмета по отдельности по ~ 5 раз в каждой из 15 локаций.
Смешанные объекты: вторая часть датасета сгенерирована таким же образом, однако “бросалось” от 2 до 10 объектов. Чтобы на изображениях попадались несколько экземпляров одного и того же объекта, он сэмплировался с заменой.
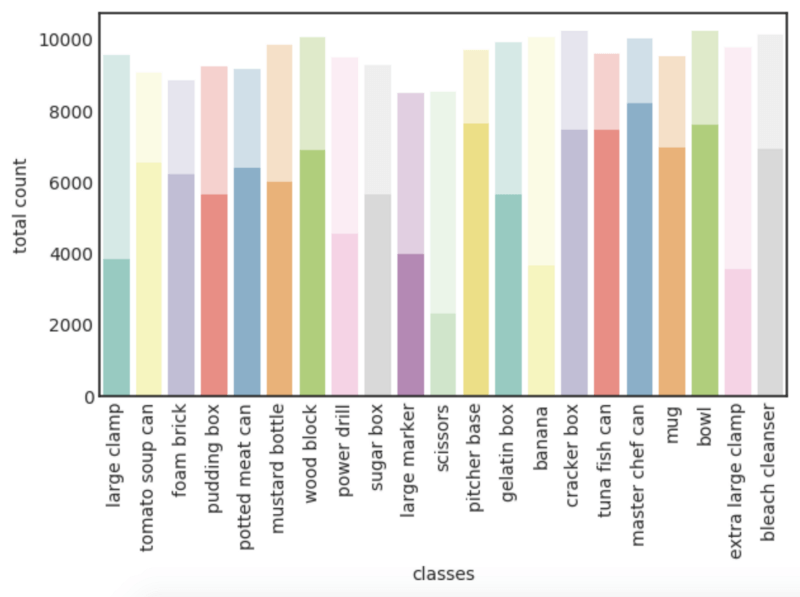
Одна локация из каждой среды была контрольной, а остальные использовались для обучения. Рисунок 2 показывает общее количество вхождений каждого класса объектов в наборе FAT.
Подводя итог
FAT поможет ускорить исследования в области обнаружения объектов и оценки их положения в 3D-пространстве в контексте робототехники. В предлагаемом датасете основное внимание уделяется бытовым предметам из набора YCB.
Синтетически комбинируя объекты и фоны алгоритм генерирует фотореалистичные изображения с точными позициями в 3D-пространстве для каждого объекта на изображении.







