The ability to reason about the relations between entities over time is crucial for intelligent decision-making. Temporal relational reasoning allows intelligent species to analyze the current situation relative to the past and formulate hypotheses on what may happen next. Figure 1 shows that given two observations of an event, people can easily recognize the temporal relation between two states of the visual world and deduce what has happened between the two frames of a video.

Humans can easily infer the temporal relations and transformations between these observations, but this task remains difficult for neural networks. Figure 1 shows
- a – Poking a stack of cans, so it collapses;
- b – Stack something;
- c – Tidying up a closet;
- d – Thumb up.
Activity recognition in videos has been one of the core topics in computer vision. However, it remains difficult due to the ambiguity of describing activities at appropriate timescales.
Previous Work
With the rise of deep convolutional neural networks (CNNs) which achieve state-of-the-art performance on image recognition tasks, many works have looked into designing effective deep convolutional neural networks for activity recognition. For instance, various approaches of fusing RGB frames over the temporal dimension are explored on the Sport1M data-set.
Another technique uses two stream CNNs with one stream of static images, and the other stream of optical flows are proposed to fuse the information of object appearance and short-term motions.
One more technique uses CNN+LSTM model. CNN is used to extract frame features and an LSTM to integrate features over time, is also used to recognize activities in videos. For temporal reasoning, instead of designing the temporal structures manually, it uses a more generic structure to learn the temporal relations in end-to-end training.
This suggestion uses a two-stream Siamese network to learn the transformation matrix between two frames, then uses the brute force search to infer the action category.
State-of-the-art idea
The idea is to use TRN(Temporal Relation Networks). The focus is to model the multi-scale temporal relations in videos. Time contrast networks are used for self-supervised limitation learning of object manipulation from third-person video observation. This work aims to learn various temporal relations in videos in a supervised learning setting. The proposed TRN can be extended to self-supervised learning for robot object manipulation.
-

Figure 2: The illustration of Temporal Relation Networks.
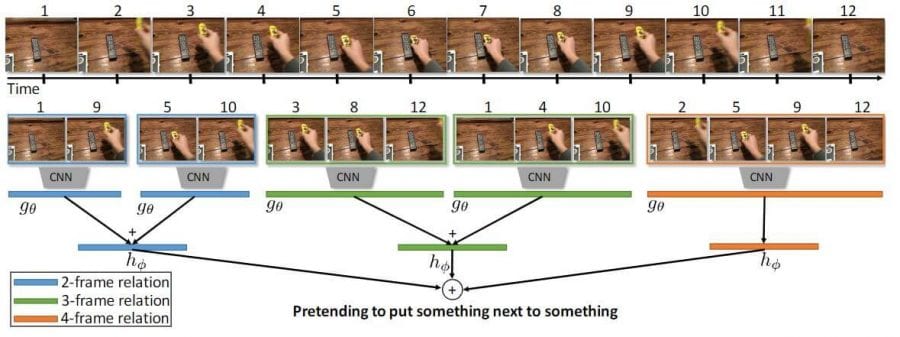
TRN is simple and can be easily plugged into any existing convolutional neural network architecture to enable temporal relational reasoning. It is defined as the pairwise temporal relation as a composite function below:
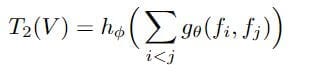
where the input is the video V with n selected ordered frames as V={f1,f2,…,fn}, where fi is a representation of the ith frame of the video, e.g., the output activation from some standard CNN. To further extend the composite function of the 2-frame temporal relations to higher frame relations such as the 3-frame relation function are given below:
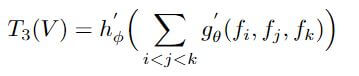
where the sum is again over sets of frames i,j,k that have been uniformly sampled and sorted.
Experiments
Evaluation has been done on a variety of activity recognition tasks using TRN-equipped networks. For recognizing activities that depend on temporal relational reasoning, TRN-equipped networks outperform a baseline network without a TRN by a large margin. The TRN-equipped networks also obtain competitive results on activity classification in the Something-Something dataset for human-interaction recognition Charades dataset and on Jester Dataset for hand gesture recognition.
-
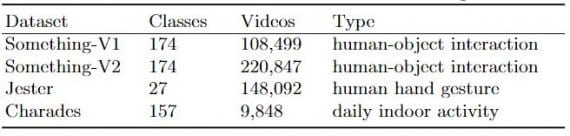
Statistics of the datasets used in evaluating the TRNs
The networks used for extracting image features play an important factor in visual recognition tasks. Features from deeper networks such as ResNet usually perform better. The goal here is to evaluate the effectiveness of the TRN module for temporal relational reasoning in videos. Thus, the base network is fixed throughout all the experiments and compare the performance of the CNN model with and without the proposed TRN modules.
Result
Something-Something is a recent video dataset for human-object interaction recognition. There are 174 classes, some of the ambiguous activity categories are challenging, such as ‘Tearing Something into two pieces’ versus ‘Tearing Something just a little bit’, ‘Turn something upside down’ versus ‘Pretending to turn something upside down’. The results on the validation set and test set of Something-V1 and Something-V2 datasets are listed in Figure 3.
-
Fig:03 Results on the validation set and test set (LEFT), Comparison of TRN and TSN as the number of frames (RIGHT)

RN outperforms TSN in a large margin as the number of frames increases, showing the importance of temporal order.TRN equipped networks also evaluated on the Jester dataset, which is a video dataset for hand gesture recognition with 27 classes. The results on the validation set of the Jester dataset are shown in figure 4.
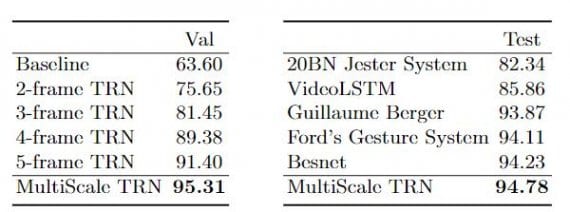
Comparison with other state-of-the-art
The approach was compared with other state-of-the-art methods. They evaluate the MultiScale TRN on the Charades dataset for daily activity recognition. The results are listed in Fig 5. This method outperforms various methods such as 2-stream networks and the recent Asynchronous Temporal Field (TempField) method.
- Fig:05 Results on Charades Activity Classification

TRN model is capable of correctly identifying actions for which the overall temporal ordering of frames is essential for a successful prediction. This outstanding performance shows the effectiveness of the TRN for temporal relational reasoning and its strong generalization ability across different datasets.
Conclusion
The proposed simple and interpret-able module Temporal Relation Network can do temporal relational reasoning in neural networks for videos. It is evaluated on several recent datasets and established competitive results using only discrete frames and also shown that TRN module discovers visual common sense knowledge in videos.
-
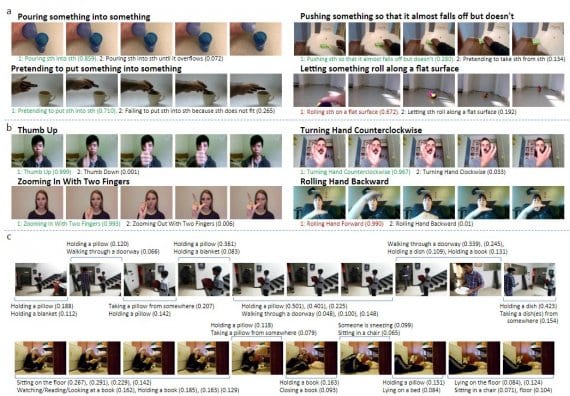
Temporal alignment of videos from the (a) Something-Something and (b)Jester datasets using the most representative frames as temporal anchor points.