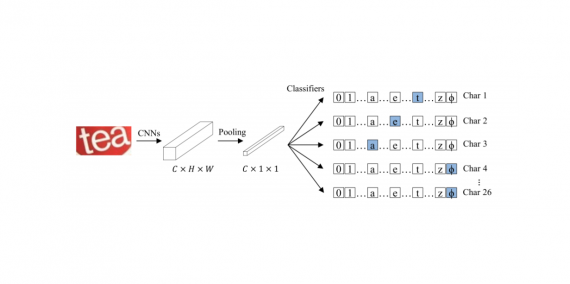
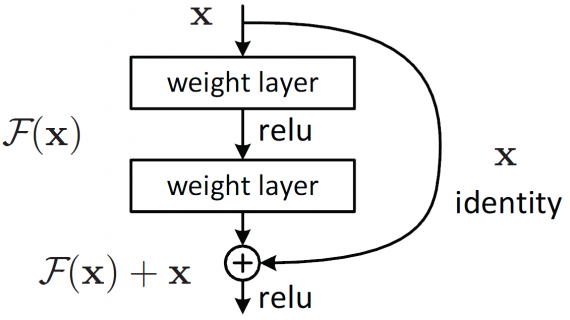
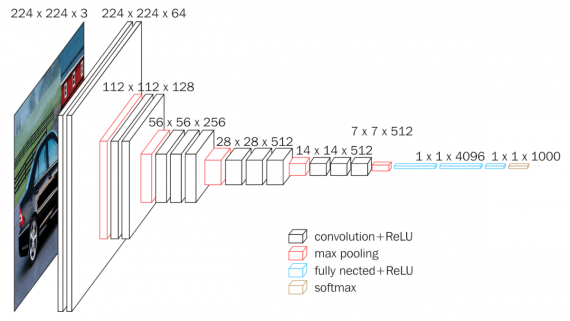
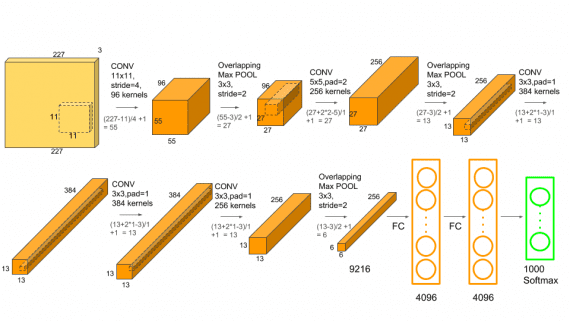
Artificial Intelligence System Predicts Worsening Patient in Emergency Room
14 May 2021

Artificial Intelligence System Predicts Worsening Patient in Emergency Room
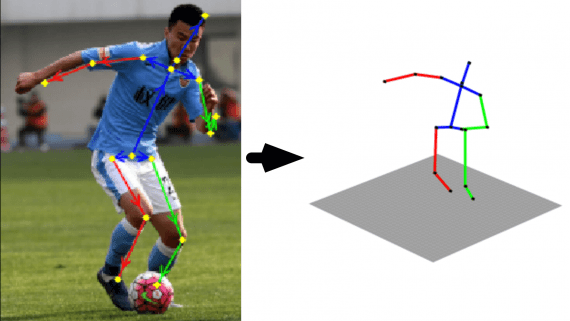
A group of researchers has created an approach to automatically predict the deterioration of patients’ condition using a neural network. The system was trained on chest x-rays and non-visual clinical…