CSTR is a convolutional neural network that recognizes text in scene images. The previous work considers the problem of text recognition on a scene image as a segmentation and seq2seq problem. The proposed model solves the problem of text recognition as a problem of image classification. Based on the results of experiments on 6 datasets, the model produces results comparable to state-of-the-art approaches. The project code is available in the open repository on GitHub.
More about the structure of the model
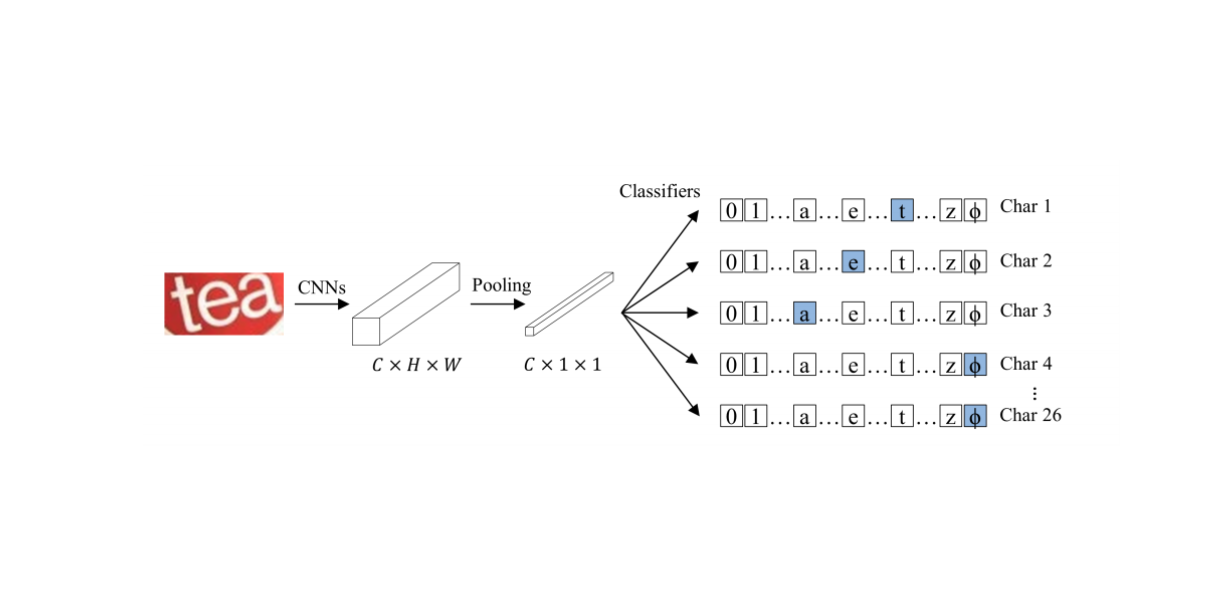
The CSTR consists of a set of convolutional layers and a global average pooling layer at the end. The pooling layer is followed by modules for multiclass classification, each of which predicts the corresponding letter from the text sequence in the input image.
Parallel cross-entropy is used as a function for CSTR errors. The CSTR architecture is comparable in ease of implementation to image classification models like ResNet.
Testing the model
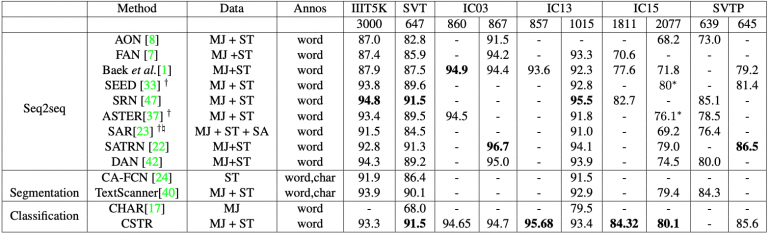
The model was tested on datasets ICDAR 2003 (IC03), ICDAR 2013 (IC13), ICDAR 2015 (IC15), IIIT 5K-Words (IIIT5k), Street View Text (SVT), and Street View Text-Perspective (SVTP). All datasets consisted of images of scenes on which there were signs with Latin text. Below you can see the test results.