Computer vision is an interdisciplinary field that has been gaining huge amounts of traction in recent years (since CNN), and self-driving cars have taken center stage. One of the most important part of computer vision is object detection. Object detection helps in solving the problem in pose estimation, vehicle detection, surveillance, etc.
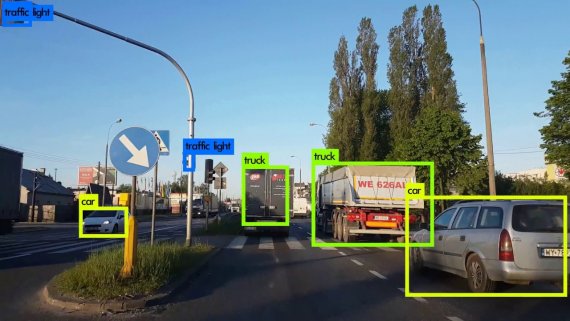
The difference between object detection algorithms and classification algorithms is that in detection algorithms, we try to draw a bounding box around the object of interest to locate it within the image. With object detection, it is possible to draw many bounding boxes around different objects which represent different objects or may be same objects.
The main problem with standard convolutional network followed by a fully connected layer is that the size of the output layer is variable — not constant, which means the number of occurrences of the objects appears in the image is not fixed. A very simple approach to solving this problem would be to take different regions of interest from the image and use a CNN to classify the presence of the object within that region.
DataSet
ImageNet is a dataset of over 15 million labeled high-resolution images belonging to roughly 22,000 categories. The images were collected from the web and labeled by human labelers using a crowd-sourcing tool like Amazon’s Mechanical Turk. Starting in 2010, as part of the Pascal Visual Object Challenge, an annual competition called the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC2013) has been held. ILSVRC uses a subset of ImageNet with roughly 1000 images in each of 1000 categories.
At all, there are roughly 1.2 million training images, 50,000 validation images, and 150,000 testing images. ImageNet consists of variable-resolution images. Therefore, the images have been down-sampled to a fixed resolution of 256×256. Given a rectangular image, the image is rescaled and cropped out the central 256×256 patch from the resulting image.
The PASCAL VOC provides standardized image data sets for object class recognition. It also provides a standard set of tools for accessing the data sets and annotations, enables evaluation and comparison of different methods and ran challenges evaluating performance on object class recognition.
The Architecture
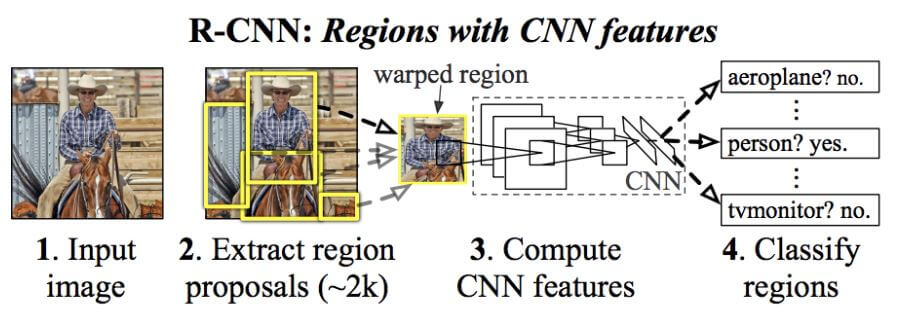
The goal of R-CNN is to take in an image, and correctly identify where the primary objects (via a bounding box) in the picture.
- Inputs: Image;
- Outputs: Bounding boxes and labels for every object in images.
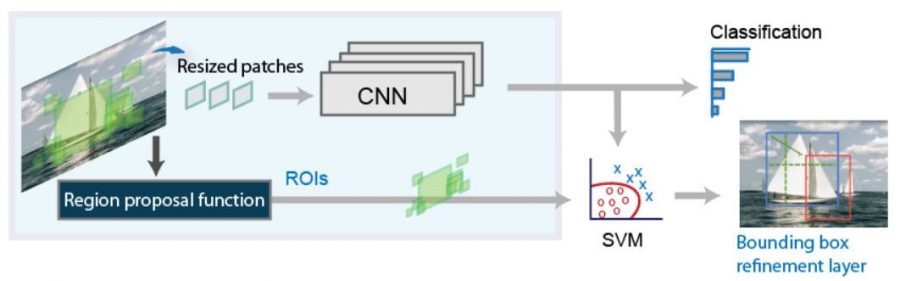
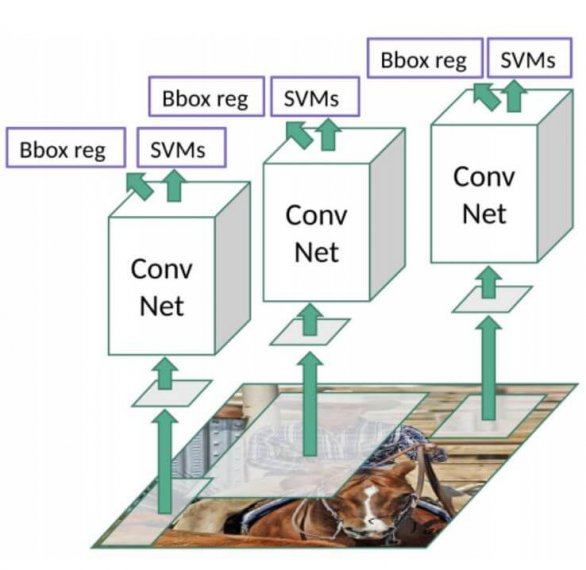
R-CNN detection system consists of three modules. The first generates category-independent region proposals. These proposals identify the set of candidate detections present in an image. The second module is a deep convolutional neural network that extracts a feature vector from each region. The third module is a set of class-specific classifier i.e. linear SVMs.
R-CNN does what we might intuitively do as well – propose a bunch of boxes in the image and see if any of them correspond to an object. R-CNN creates these bounding boxes, or region proposals, using a process called Selective Search. At a high level, Selective Search (shown in Fig:1 below) looks at the image through windows of different sizes, and for each size tries to group adjacent pixels by texture, color, or intensity to identify objects.

As soon as the proposals are created, R-CNN enclosed the region to a standard square size and passed it through to a modified version of AlexNet. On the last layer of the CNN, R-CNN adds a Support Vector Machine (SVM) that classifies whether this is an object and if so what object. This is step 4 in the image above.
Improving the Bounding Boxes
- Inputs: sub-regions of the image corresponding to objects.
- Outputs: New bounding box coordinates for the object in the sub-region.
So, to summarize, R-CNN is just the following steps:
- Generate a set of region proposals for bounding boxes.
- Run the images in the bounding boxes through a pre-trained AlexNet and finally an SVM to see what object the image in the box is.
- Run the box through a linear regression model to output tighter coordinates for the box once the object has been classified.
Implementation
Time taken to train the network is very huge as the network have to classify 2000 region proposals per image. It cannot be implemented real time as it takes around 47 seconds for each test image. The particular search algorithm is a fixed algorithm. Therefore, no learning is happening at that stage. This will lead to a generation of bad region of proposal.
[Tensorflow][Keras]
Result
R-CNN provides the state of the art results. Previous systems were complex ensembles combining multiple low-level image features with high-level context from object detectors and scene classifiers. R-CNN presents a simple and scalable object detection algorithm that gives a 30% relative improvement over the best previous results on ILSVRC2013.
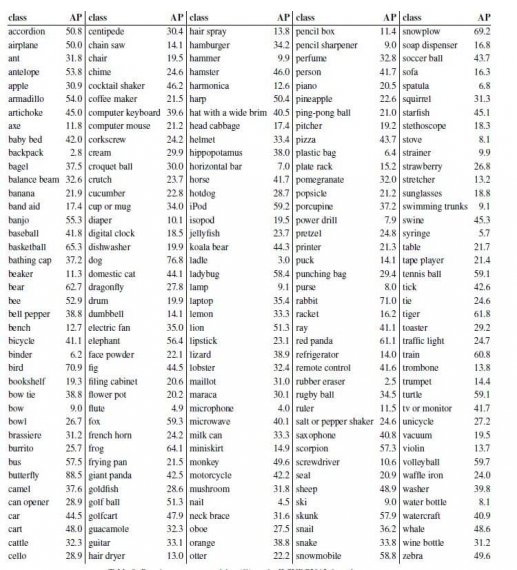
R-CNN achieved this performance through two insights. The first is to apply high-capacity convolutional neural networks to bottom-up region proposals to localize and segment objects. The second is to train large CNNs when labels of training data are scarce. R-CNN results show that it is highly useful to pre-train the network with supervision.