
One hallmark of human cognition is the splendid capacity of recalling thousands of different images, some in details, after only a single view. Not all photos are remembered equally in a human brain. Some images stick in our minds, while others fade away in a short time. This kind of capacity is likely to be influenced by individual experiences and is also subject to some degree of inter-subject variability, similar to some individual image properties.
Interestingly, when exposed to the overflow of visual images, subjects have a consistent tendency rather remember or forget the same pictures. Previous research suggests and analyzes the reason why people have the intuition to remember images and provide reliable solutions for ranking images by memorability scores. These works are mostly for generic images, object images and face photographs. However, it is difficult to dig out the obvious cues relevant to the memorability of a natural scene. To date, methods for predicting the visual memorability of a natural scene are scarce.
Previous Works
Previous work showed that memorability is an intrinsic property of an image. DNN has demonstrated splendid achievement in many research areas, e.g., video coding and computer vision. Also, several DNN approaches were proposed to estimate image memorability, which significantly improves the prediction accuracy.
- Data scientists from MIT trained the MemNet on a large-scale database, achieving a splendid prediction performance close to human consistency.
- Baveye et al. fine-tuned the GoogleNet exceeding the performance of handcrafted features. Researchers also studied and targeted the certain objects like faces, natural scenes, etc.
- Researchers from MIT have also created a database for studying the memorability of human face photographs. They further explored the contribution of certain traits (e.g., kindness, trustworthiness, etc.) to face memorability, but such characteristics only partly explain facial memorability.
State-of-the-art idea
As a first step towards understanding and predicting the memorability of a natural scene, LNSIM database is built. In LNSIM database, there are in total 2,632 natural scene images. For obtaining these natural scene images, 6,886 images are selected, which contain natural scenes from the existing databases, including MIR Flickr, MIT1003, NUSEF, and AVA database. Natural scenes images are selected from these databases. Fig. 1 shows some example images from LNSIM database.

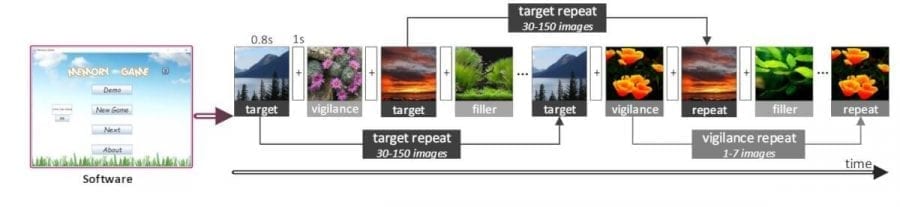
A memory game is used to quantify the memorability of each image in LNSIM database. A software is developed in which 104 subjects (47 females and 57 males) were involved. They do not overlap with the volunteers who participated in the image selection. The procedure of our memory game is summarized in Fig. 2.
Analysis of Natural Scene Memorability
LNSIM database is mined to better understand how natural scene memorability is influenced by the low, middle and high-level handcrafted features and the learned deep feature.
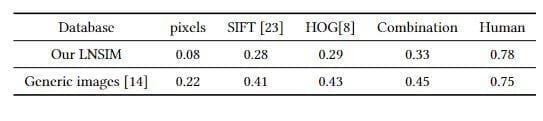
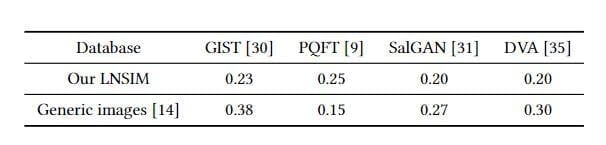
The middle-level feature of GIST describes the spatial structure of an image. However, Table 2 shows that the SRCC of GIST is only 0.23 for the natural scene, much less thanρ=0.38 of generic images. This illustrates that structural information provided by the GIST feature is less effective for predicting memorability scores on natural scenes.
- Task 1(Classification Judgement): 5 participants are asked to indicate which scene categories an image has. A random image query was generated for each participant. Participants had
to choose proper scene category labels to interpret scene stuff for each image.
- Task 2 (Verification Judgement): A separate task ran on the same set of images by recruiting another 5 participants after Task 1. The participants were asked to provide a binary answer to the question for each image. The default answer was set to “No”, and the participants can check the box of image index to set “No” to “Yes”.
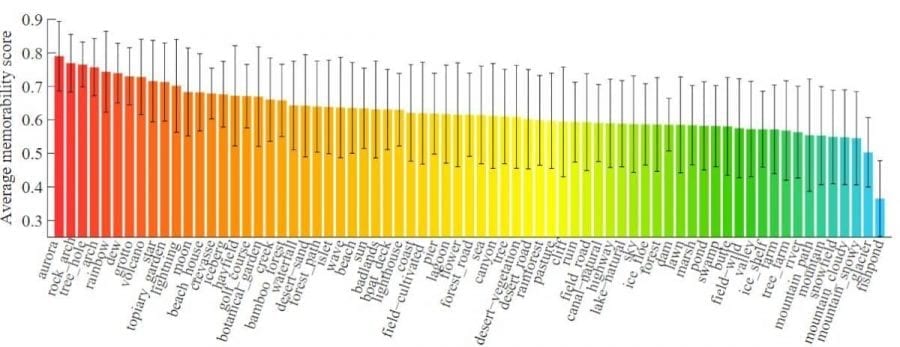
All images are annotated with categories through the majority voting over Task 1 and Task 2. Afterward, an SVR predictor with the histogram intersection kernel is trained for scene category. The scene category attribute achieves a good performance of SRCC(ρ=0.38), outperforming the results of low-level feature combination. This suggests that high-level scene category is an obvious cue of quantifying the natural scene memorability. As shown in below Figure, the horizontal axis represents scene categories in the descending order of corresponding average memorability scores. The average score ranges from 0.79 to 0.36, giving a sense of how memorability changes across different scene categories. The distribution in below Figure indicates that some unusual classes like aurora tend to be more memorable, while usual classes like mountain are more likely to be forgotten. This is possibly due to the frequency of each category appears in daily life.
DeepNSM: DNN for natural scene memorability
Fine-tuned MemNet model serves as the baseline model in predicting natural scene memorability. In the proposed DeepNSM architecture, the deep feature is concatenated with the category-related element to predict the memorability of natural scene images accurately. Note that the “deep feature” refers to the 4096-dimension feature extracted from the baseline model.
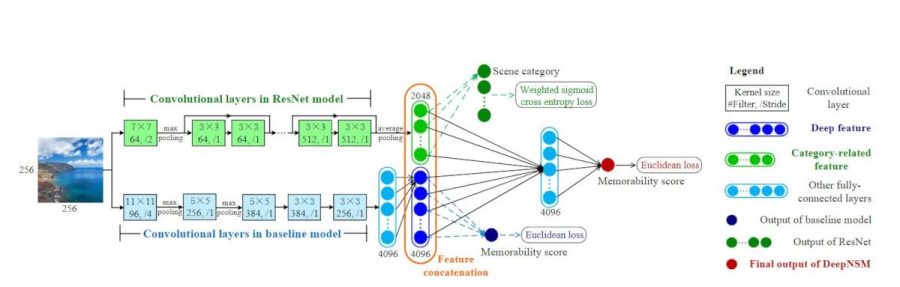
Comparison with other models
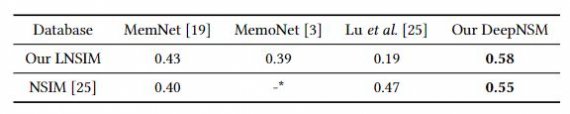
Fig: 3 shows the SRCC performance of DeepNSM and the three compared methods. DeepNSM successfully achieves the outstanding SRCC performance, i.e., ρ=0.58 and 0.55, over the LNSIM and NSIM databases, respectively. It significantly outperforms the state-of-the-art DNN methods, MemNet and MemoNet. The above results demonstrate the effectiveness of DeepNSM in predicting natural scene memorability.
Conclusion








