Human pose estimation is а fundamental problem in computer vision. Computer’s ability to recognize and understand humans in images and videos is crucial for multiple tasks including autonomous driving, action recognition, human-computer interaction, augmented reality and robotics vision.
In recent years, significant progress has been achieved in 2D human pose estimation. The crucial factor behind this success is the availability of large-scale annotated human pose datasets that allow training networks for 2D human pose estimation. At the same time, advances in 3D human pose estimation remain limited because obtaining ground-truth information on the dense correspondence, depth, motion, body-part segmentation, occlusions is a very challenging task.
In this article, we present several recently created datasets that attempt to address the shortage of annotated datasets for 3D human pose estimation.
DensePose
Number of images: 50K
Number of annotated correspondences: 5M
Year: 2018
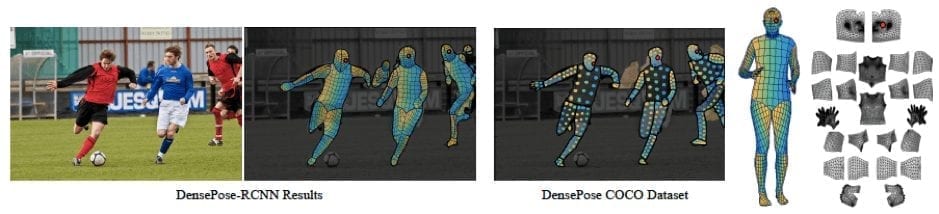
DensePose is a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images. To build this dataset FAIR team involved human annotators, who were establishing dense correspondences from 2D images to surface-based representations of the human body using a specifically developed annotation pipeline.
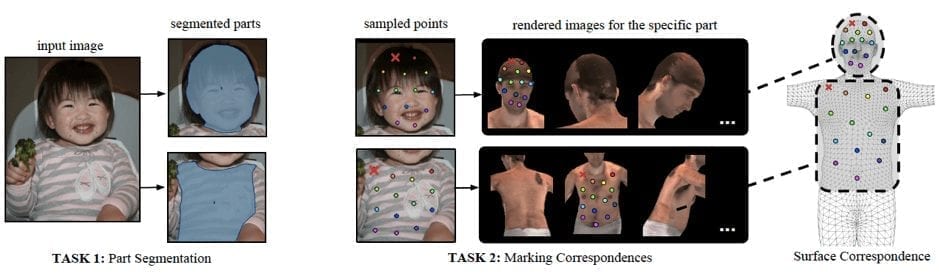
As shown below, in the first stage annotators define regions corresponding to visible, semantically defined body parts. In the second stage, every part region is sampled with a set of roughly equidistant points and annotators are requested to bring these points in correspondence with the surface. The researchers wanted to avoid manual rotation of the surface and for this purpose, they provide annotators with six pre-rendered views of the same body part and allow users to place landmarks on any of them.
Below are visualizations of annotations on images from the validation set: Image (left), U (middle) and V (right) values for the collected points.

DensePose is the first manually-collected ground truth dataset for the task of dense human pose estimation.
SURREAL
Number of frames: 6.5M
Number of subjects: 145
Year: 2017
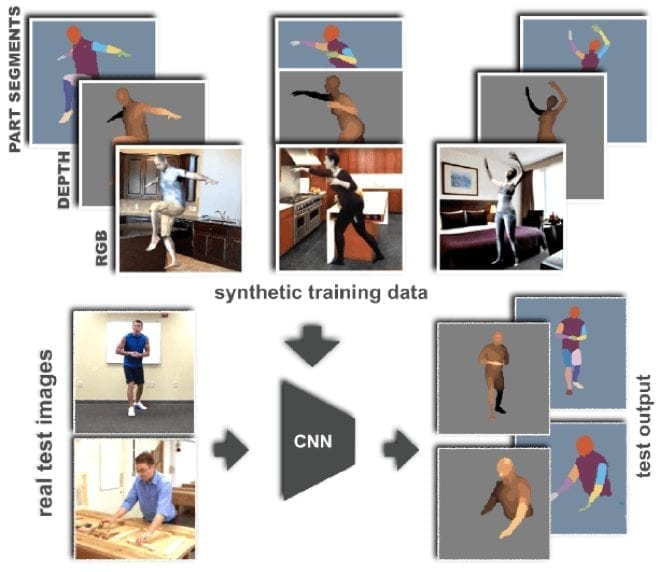
SURREAL (Synthetic hUmans foR REAL tasks) is a new large-scale dataset with synthetically-generated but realistic images of people rendered from 3D sequences of human motion capture data. It includes over 6 million frames accompanied with the ground-truth pose, depth maps, and segmentation masks.
As described in the original research paper, images in SURREAL are rendered from 3D sequences of MoCap data. The realism of synthetic data is usually limited. So, to ensure the realism of human bodies in this dataset, the researchers decided to create synthetic bodies using SMPL body model, whose parameters are fit by the MoSh method given raw 3D MoCap marker data. Moreover, creators of SURREAL dataset ensured a large variety of viewpoints, clothing, and lighting.
A pipeline for generating synthetic human is demonstrated below:
- a 3D human body model is posed using motion capture data;
- a frame is rendered using a background image, a texture map on the body, lighting and a camera position;
- all the “ingredients” are randomly sampled to increase the diversity of the data;
- generated RGB images are accompanied with 2D/3D poses, surface normal, optical flow, depth images, and body-part segmentation maps.
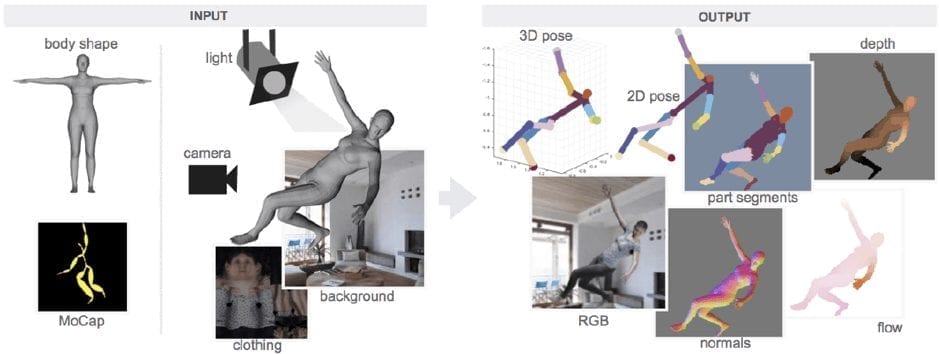
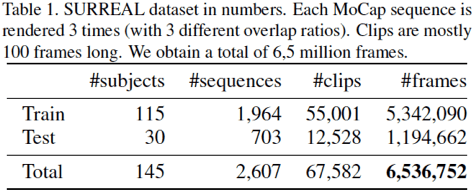
The resulting dataset contains 145 subjects, more than 67.5K clips and over 6.5M frames:
Even though SURREAL contains synthetic images, the researchers behind this dataset demonstrate that CNNs trained on SURREAL allow for accurate human depth estimation and human part segmentation in real RGB images. Hence, this dataset provides new possibilities for advancing 3D human pose estimation using cheap and large-scale synthetic data.
UP-3D
Number of subjects: 5,569
Number of images: 5,569 training images and 1208 test images
Year: 2017

UP-3D is a dataset, which “Unites the People” of different datasets for multiple tasks. In particular, using the recently introduced SMPLify method the researchers obtain high-quality 3D body model fits for several human pose datasets. Human annotators only sort good and bad fits.
This dataset combines two LSP datasets (11,000 training images and 1,000 test images) and the single-person part of the MPII-HumanPose dataset (13,030 training images and 2622 test images). While it was possible to use an automatic segmentation method to provide foreground silhouettes, the researchers decided to involve human annotators for reliability. They have built an interactive annotation tool on top of the Opensurfaces package to work with Amazon Mechanical Turk (AMT) and have been using the interactive Grabcut algorithm to obtain image consistent silhouette borders.
So, the annotators were asked to evaluate fit for:
- foreground silhouettes;
- six body part segmentation.
While the average foreground labeling task was solved in 108s on the LSP and 168s on the MPII datasets respectively, annotating the segmentation for six body parts took on average more than twice as long as annotating foreground segmentation: 236s.
The annotators were sorting good and bad fits and here are the percentages of accepted fits per dataset:

Thus, the validated fits formed the initial UP-3D dataset with 5,569 training images and 1,208 test images. After the experiments on semantic body part segmentation, pose estimation and 3D fitting, the improved 3D fits can extend the initial dataset.

The presented dataset allows for a holistic view on human-related prediction tasks. It sets a new mark in terms of levels of detail by including high-fidelity semantic body part segmentation in 31 parts and 91 landmark human pose estimation. It was also demonstrated that training the pose estimator on the full 91 keypoint dataset helps to improve the state-of-the-art for 3D human pose estimation on the two popular benchmark datasets HumanEva and Human3.6M.
Bottom Line
As you can see, there are many possible approaches to building a dataset for 3D human pose estimation. The datasets presented here focus on different aspects of recognizing and understanding humans in images. However, all of them can be handy for estimating human poses in some of the real-life applications.