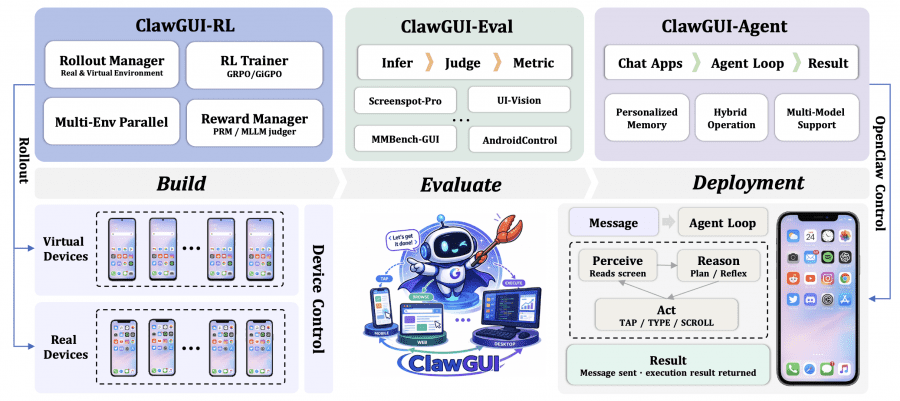
Исследователи из Чжэцзянского университета опубликовали ClawGUI — полностью открытый фреймворк для разработки GUI-агентов, которые управляют приложениями через визуальный интерфейс, как это делает человек: касаниями, свайпами и вводом текста. На практике это открывает несколько направлений применения: автоматизация тестирования мобильных приложений без написания скриптов вручную, управление корпоративным ПО без доступа к API, голосовое или текстовое управление телефоном через привычные мессенджеры, а также исследовательская платформа для тех, кто занимается GUI-агентами и хочет воспроизводимые результаты на общих бенчмарках. Проект распространяется под лицензией Apache 2.0: код доступен на GitHub, веса модели ClawGUI-2B опубликованы на HuggingFace и ModelScope, а датасет для оценки доступен на HuggingFace Datasets.
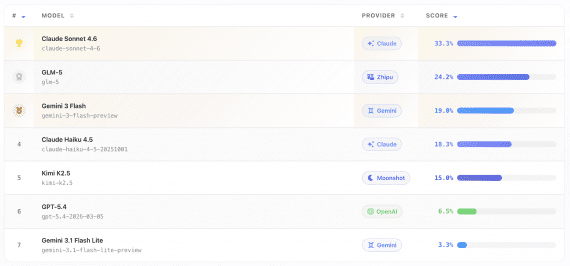
Модель ClawGUI-2B была обучена целиком внутри фреймворка методом обучения с подкреплением в режиме онлайн: агент сам взаимодействует с 64 параллельными эмуляторами телефонов на 8 GPU, пробует выполнить задачи и обновляет свои веса на основе того, что получилось, без заранее собранного датасета. На бенчмарке MobileWorld GUI-Only модель набирает 17.1% успешных завершений. Бенчмарк состоит из 117 реальных мобильных задач: отправить сообщение, найти контакт, изменить настройку, оформить заказ, — и агент выполняет их только через визуальный интерфейс, без какого-либо программного доступа к приложениям. Засчитывается только полное выполнение: частичный прогресс не считается. 17.1% — на 54% лучше базовой MAI-UI-2B того же масштаба и выше значительно более крупных моделей: Qwen3-VL-32B (в 16 раз больше параметров) показывает 11.9%, UI-Venus-72B (в 36 раз больше) — 16.4%.
Что такое GUI-агент
GUI-агент — это модель, которая видит экран и управляет им: нажимает, скроллит, вводит текст. В отличие от агентов на основе API, он работает с любым приложением без специальной интеграции, как человек за компьютером. Это касается не только телефонов: десктопные приложения, браузер, веб-сервисы. Всё, у чего есть визуальный интерфейс.
Прогресс в этой области тормозит не нехватка идей, а три конкретные инфраструктурные проблемы. Никто не публикует код для обучения таких агентов. Результаты есть, воспроизвести их нельзя. Числа из разных статей несравнимы, потому что каждая команда оценивает модели по-своему. И наконец, обученные агенты почти никогда не доходят до реальных пользователей — остаются внутри лаборатории.
ClawGUI-RL: обучение GUI-агентов с подкреплением на реальных устройствах
ClawGUI-RL — первая открытая инфраструктура для онлайн-RL обучения GUI-агентов с подтверждённой поддержкой как параллельных виртуальных сред (Android-эмуляторов в Docker-контейнерах), так и реальных физических устройств. Код модуля находится в директории clawgui-rl.
Ключевая техническая проблема — управление средой. Эмуляторы могут зависать или падать во время долгих тренировочных прогонов. ClawGUI-RL решает это через ротацию серверов: когда контейнер становится «нездоровым», он автоматически заменяется исправным из очереди, и задача продолжается без прерывания обучения. Каждый прогон можно записать и посмотреть заново, что помогает понять, где агент ошибся, и при необходимости использовать эти записи для построения новых датасетов.
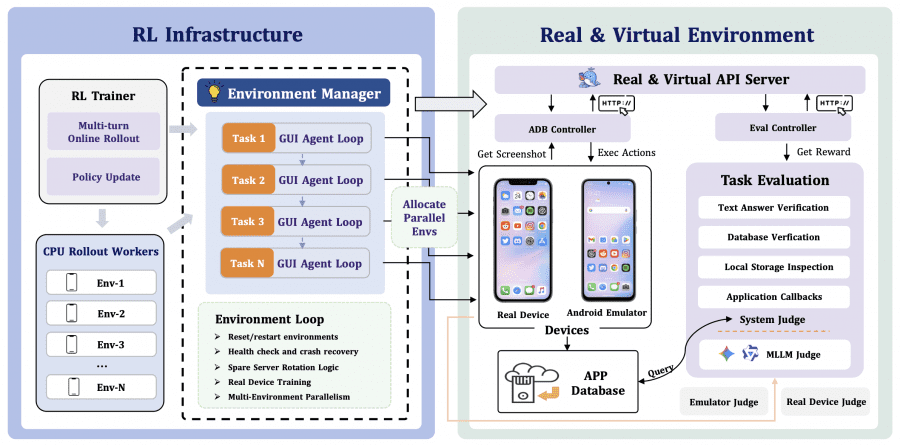
В ClawGUI-RL применяется двухуровневая функция вознаграждения. По умолчанию агент получает сигнал только в конце задачи: справился — получил 1, провалился — получил 0. Для длинных задач это плохо работает: агент делает десятки шагов вообще без какой-либо обратной связи и не понимает, движется ли он в правильном направлении. Авторы добавили отдельную модель-оценщик, чтобы это исправить. После каждого действия она смотрит на скриншоты до и после, анализирует историю шагов и выставляет оценку: насколько этот конкретный шаг приблизил к цели. Итоговый сигнал — сумма финальной оценки и пошаговых оценок за весь эпизод.
Фреймворк поддерживает несколько RL-алгоритмов, авторы сравнивали два из них. GRPO оценивает всю траекторию целиком и присваивает одинаковый сигнал каждому шагу эпизода — неважно, был ли это случайный промах в начале или решающее нажатие в конце. GiGPO работает тоньше: он сравнивает между собой шаги, которые оказались в одинаковой ситуации в разных прогонах, и выставляет оценку каждому действию отдельно. Это особенно важно для длинных задач, где качество промежуточных действий сильно различается. Замена GRPO на GiGPO дала +2.6% к Success Rate, или +17.9% относительно.
ClawGUI-Eval: воспроизводимая оценка на 6 бенчмарках
ClawGUI-Eval решает проблему несравнимых результатов через жёстко стандартизированный пайплайн из трёх шагов: сначала инференс (inference) — модель делает предсказания, затем оценка — предсказания сверяются с эталоном, затем подсчёт метрик. Все настройки для каждой модели зафиксированы и задокументированы. Датасет опубликован на HuggingFace, код — в директории clawgui-eval/.
Фреймворк покрывает 6 бенчмарков и 11+ моделей, включая Qwen3-VL, UI-TARS, MAI-UI, Gemini и Seed 1.8. Запустить оценку можно как локально на своём GPU, так и через любой API совместимый с форматом OpenAI. Итог: 95.8% воспроизводимости официальных результатов на 48 парах модель-бенчмарк — результат считается воспроизведённым, если разница с официальным числом не превышает 2%. Это первый раз в области GUI-агентов, когда чужие числа можно реально проверить.
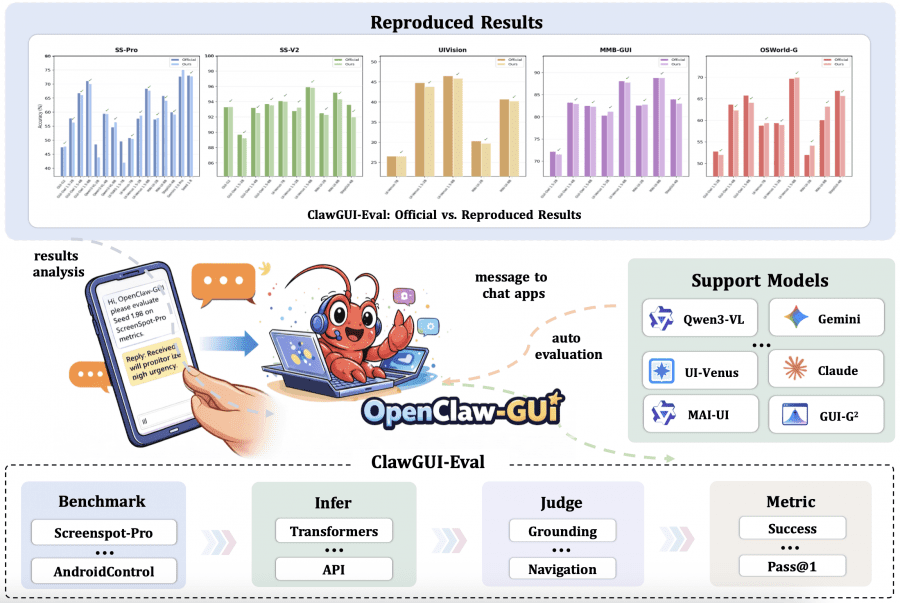
Два из 48 случаев воспроизведения провалились: Qwen3-VL-2B и UI-TARS 1.5-7B на ScreenSpot-Pro. Обе модели объединяет одно: их официальные конфигурации оценки публично не раскрыты. Это прямо указывает на то, что главная причина нереплицируемости в области GUI-агентов — не фундаментальная проблема, а инфраструктурная: незадокументированные настройки промптов и разрешений. Для закрытых моделей (Gemini, Seed 1.8) авторы применили стратегию Zoom — двухэтапную обрезку с последующей локализацией, что позволило успешно воспроизвести официальные результаты без доступа к весам.
Отдельная возможность: ClawGUI-Eval встроен в ClawGUI-Agent как навык. Вместо того чтобы писать скрипты, достаточно написать в мессенджер фразу вроде «benchmark qwen3vl on screenspot-pro» — агент сам проверит окружение, запустит параллельный инференс, оценит результаты и вернёт отчёт со сравнением с официальными числами.
ClawGUI-Agent: деплой на Android, HarmonyOS и iOS
ClawGUI-Agent замыкает цикл от исследования до реальных пользователей. Построен поверх OpenClaw и работает на движке nanobot. Поддерживает управление устройствами через три протокола: Android через ADB, HarmonyOS через HDC, iOS через XCTest. Подключается к 12+ чат-платформам, включая WeChat, DingTalk, Feishu, Telegram, Discord, Slack и QQ. Код модуля — в директории clawgui-agent/.
Есть два режима работы: удалённый (пользователь управляет телефоном с другого устройства через мессенджер) и локальный (команды прямо с того же телефона, облако не нужно). Для тех, кто предпочитает веб-интерфейс, доступен Gradio UI для управления устройствами, просмотра задач и инспекции памяти агента.
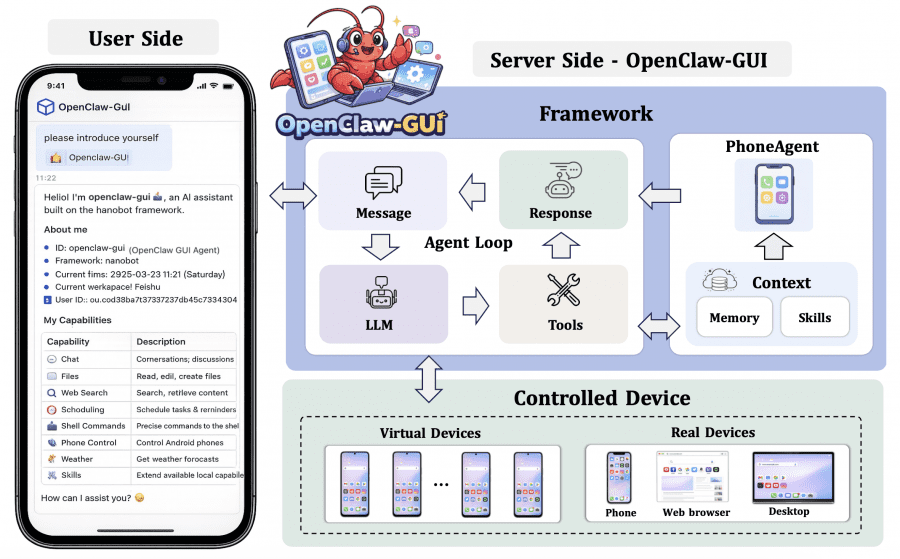
Гибридный подход к управлению устройством: там, где приложение поддерживает программный интерфейс, агент использует CLI (быстро и точно); там, где интерфейса нет, переключается на GUI (универсально). Во время выполнения задач агент автоматически запоминает структурированные факты — имена контактов, часто используемые приложения, привычки пользователя — и хранит их как векторные эмбеддинги (vector embeddings) в персистентном хранилище. При следующих задачах наиболее релевантные воспоминания достаются из хранилища и добавляются в контекст. Дубликаты обнаруживаются и объединяются, а не накапливаются. Каждое выполнение задачи записывается как структурированный эпизод — это позволяет воспроизводить сценарии и использовать их для построения новых датасетов.
Модель ClawGUI-2B
ClawGUI-2B построена на базе MAI-UI-2B и обучена с нуля внутри ClawGUI-RL: 64 параллельных Android-эмулятора, 8 GPU A6000 по 48 ГБ каждый, алгоритм GiGPO, 3 эпохи обучения. В качестве модели-оценщика для пошаговых наград использовался Qwen3.5-72B. Он смотрел на каждое действие агента и решал, насколько оно приблизило к цели. Скачать модель можно на HuggingFace и ModelScope.
Результаты: маленькая хорошо обученная модель против больших необученных
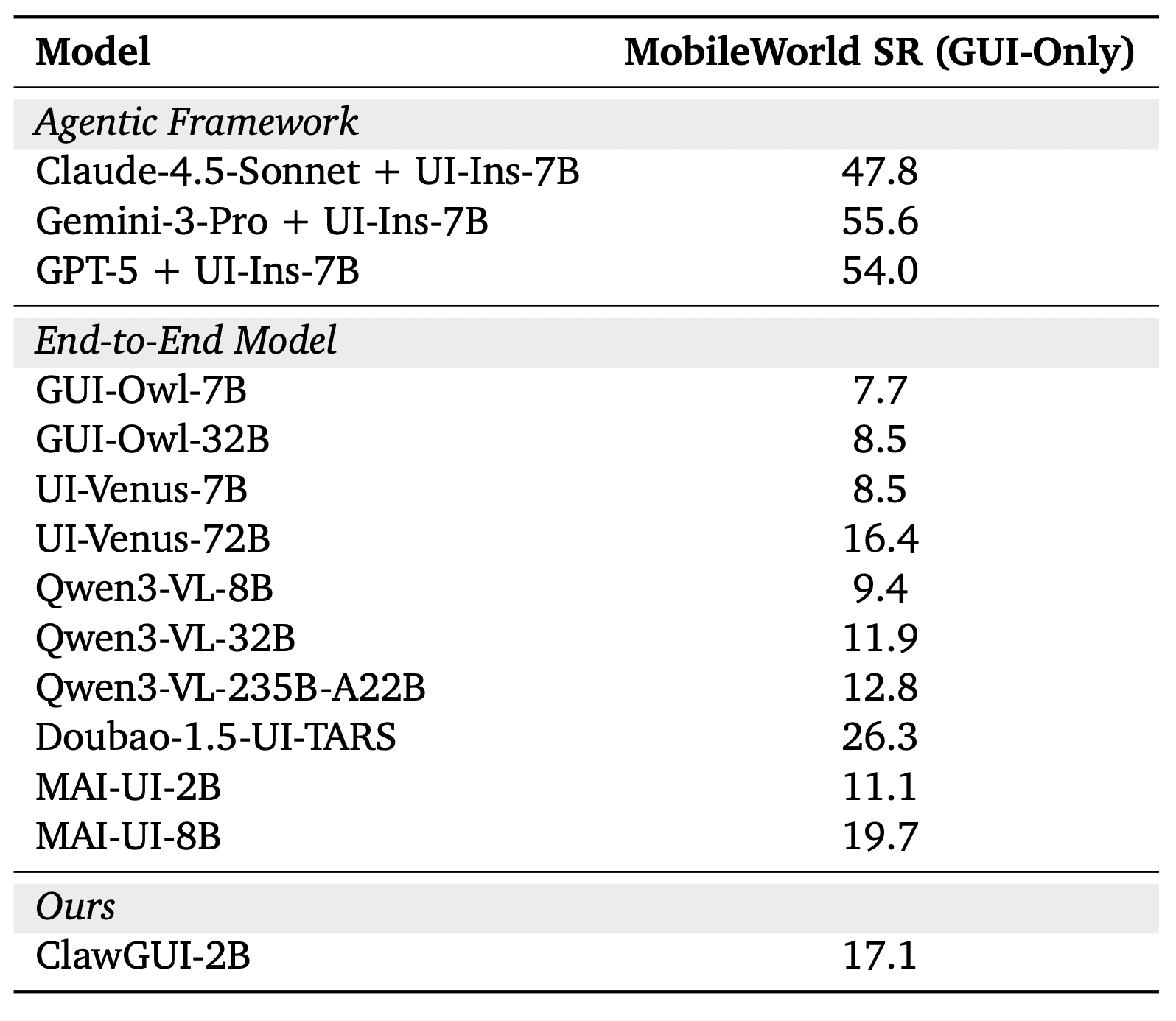
ClawGUI-2B показал 17.1% завершённых задач на бенчмарке MobileWorld GUI-Only. MAI-UI-2B при тех же весах и том же масштабе показывает 11.1%. Весь прирост объясняется исключительно инфраструктурой ClawGUI-RL: оба стартуют с одних и тех же весов. Это прямое доказательство того, что качество обучения важнее масштаба модели.

Агентные фреймворки с проприетарными моделями (Gemini-3-Pro + UI-Ins-7B: 55.6%, GPT-5 + UI-Ins-7B: 54.0%) показывают значительно более высокие результаты. Но сравнение не совсем честное: Claude и Gemini здесь работают в связке с отдельной моделью, которая умеет точно находить элементы на экране, и значительно дороже в эксплуатации. ClawGUI-2B — это компактная модель, которую можно запустить локально и дообучить под свои задачи.
Можно ли использовать это прямо сейчас
Модель можно дообучить под конкретное приложение, и это повысит точность по сравнению с универсальной версией. Если задачи однотипные и хорошо определённые, например один и тот же smoke-тест одного приложения, модель может выучить этот сценарий значительно лучше. Инфраструктура открыта. Аренда одной A6000 в облаке на апрель 2026 обходится от $0.27/час на Thunder Compute до $0.91/час на Lambda. При реалистичной оценке в 10–50 часов на весь прогон на 8 GPU итоговая стоимость составит от $70 до $365 — это значит, что воспроизвести эксперимент может небольшая команда без доступа к дорогой инфраструктуре.
При этом ожидания стоит оценивать аккуратно. 17.1% на MobileWorld — это результат на разнообразных задачах из разных приложений. На узкой специализированной задаче результат будет выше, но насколько — зависит от стабильности UI между версиями приложения, длины цепочки действий и того, насколько хорошо модель воспринимает конкретные элементы интерфейса. По грубой оценке, для коротких сценариев можно ориентироваться на 40–60%, и агент скорее всего будет полезен как инструмент под наблюдением человека, а не как полностью автономный тестировщик. Это всё равно лучше, чем писать и поддерживать скрипты вручную.
Что планируется дальше
Согласно роадмапу на GitHub, следующие шаги разработчиков: запуск агента напрямую на телефоне без облачного сервера-посредника (сейчас команды пользователя обрабатываются на сервере и только потом отправляются на устройство — это поднимает вопросы приватности), расширение обучения на десктопные и веб-среды, обучение в реальном времени.
Более далёкая цель — научить агента предсказывать, как изменится экран в ответ на действие, до того как это действие совершено. Сейчас агент работает реактивно: увидел скриншот, сделал шаг, посмотрел что вышло. Если модель научится представлять последствия действий заранее, она сможет планировать на несколько шагов вперёд — примерно так, как это делает человек, когда мысленно прокручивает сценарий перед тем как что-то нажать.