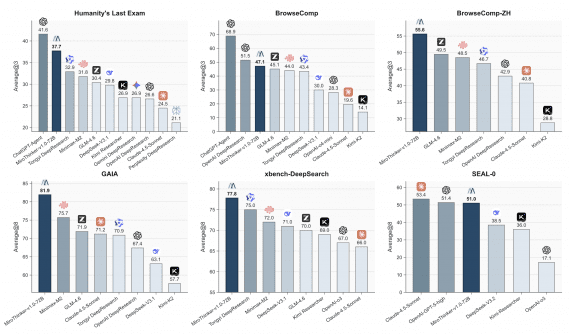
MIRA: модель мира целиком симулирует Rocket League, не требуя установки самой игры
8 июля 2026

MIRA: модель мира целиком симулирует Rocket League, не требуя установки самой игры
Команды General Intuition, Kyutai и Epic Games представили MIRA — мировую модель (world model), которая целиком симулирует игровую среду Rocket League для четырёх игроков одновременно и рисует каждому свою картинку…