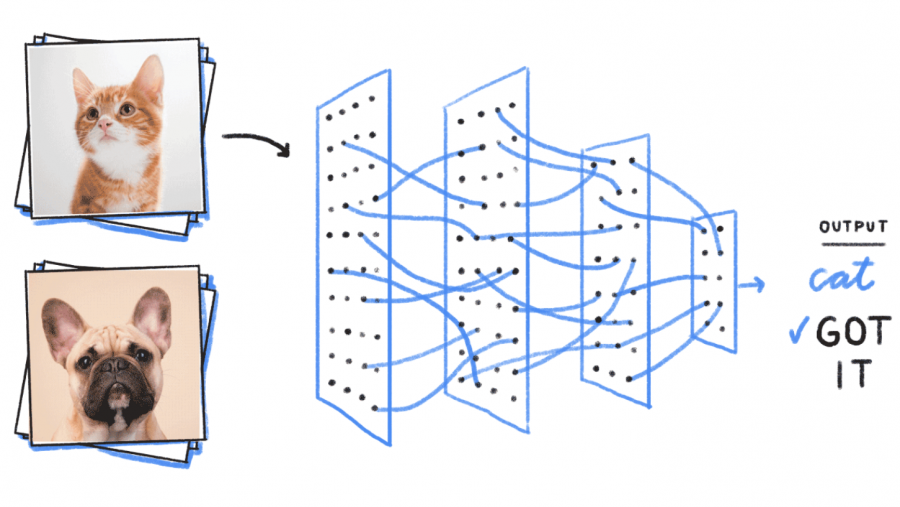
Персептрон – это нейронная сеть, которая представляет собой алгоритм для выполнения двоичной классификации. Он определяет, относится ли объект к определенной категории (например, является ли животное на рисунке кошкой или нет).
Персептрон занимает особое место в истории нейронных сетей и искусственного интеллекта, потому что первоначальные иллюзии по поводу его эффективности привели к появлению т. н. опровержения Минского-Паперта и застою в исследованиях нейронных сетей, который продлился несколько десятилетий. Лед тронулся после публикации работ Джеффа Хинтона в 2000-х годах, результаты которого преобразили все области машинного обучения.

Фрэнк Розенблатт, родоначальник персептрона, популяризировал его как устройство, а не алгоритм. Персептрон впервые вошел в мир в качестве аппаратного обеспечения. Розенблатт, психолог, который учился, а затем и читал лекции в Корнельском университете, получил финансирование от Управления по морским исследованиям в США, чтобы сконструировать машину, которая могла бы обучаться. Его машина, названная «Mark I», выглядела так:

Персептрон представляет собой линейный классификатор, то есть алгоритм, который классифицирует объект путем разделения двух категорий прямой. Объектом обычно является вектор-функция x, взятая с весом w и смещенная на b: y = w * x + b.
На выходе персептрон выдает результат y, основанный на нескольких вещественных входных объектах путем формирования линейной комбинации с использованием весовых коэффициентов (иногда с последующим пропусканием результата через нелинейную функцию активации). Вот как это выглядит на языке математики:
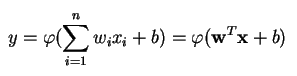
где w – вектор весовых коэффициентов, x – вектор входных объектов, b – смещение, φ – функция нелинейной активации.
Розенблатт разработал однослойный персептрон. Это значит, что его аппаратный алгоритм не включал в себя несколько уровней, которые позволяют нейронным сетям моделировать иерархию признаков. Это была мелкая нейронная сеть, которая мешала персептрону выполнять нелинейную классификацию, например, вычислять значение функции XOR (триггером оператора XOR является несовпадение двух объектов, другое название – «исключающее или»), как показали Минский и Паперт в своей книге.
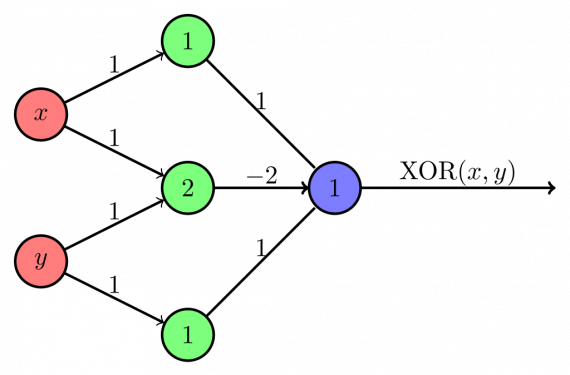
Многослойный персептрон
Последующее исследование многослойных персептронов показало, что они способны аппроксимировать как оператор XOR, так и многие другие нелинейные функции.
Так же, как Розенблатт основал персептрон на нейроне Маккаллоха-Питса, разработанном в 1943 году, так и сами персептроны являются строительными блоками, которые могут быть полезны только в таких больших функциях, как многослойные персептроны.
Многослойный персептрон — это хорошая стартовая точка для изучения глубокого обучения.

Многослойный персептрон представляет собой глубокую искусственную нейронную сеть, включающую в себя несколько персептронов. Многослойные персептроны состоят из входного слоя для приема сигнала, выходного слоя, который принимает решение или делает предсказание о входном объекте, а между ними – произвольное количество скрытых слоев, которые являются истинным вычислительным движком. Многослойные персептроны с одним скрытым слоем способны аппроксимировать любую непрерывную функцию.
Как работает персептрон
Персептроны часто применяются для решения контролируемых задач обучения: они тренируются по набору пар входных/выходных объектов и учатся моделировать корреляции (т. е. зависимости) между этими данными. Обучение включает в себя настройку параметров модели (весовых коэффициентов, смещений) для минимизации погрешности. Для корректировки этих параметров относительно погрешности используется алгоритм обратного распространения, а сама погрешность может быть вычислена различными способами, в том числе путем вычисления среднеквадратичного отклонения (RMSE).
Сети прямого распространения, такие как многослойный персептрон, похожи на теннис или пинг-понг. Они в основном состоят из двух видов движений: вперед и назад. Получается своеобразная игра в пинг-понг между догадками и ответами, поскольку каждая догадка – это проверка того, что мы знаем, а каждый ответ – это обратная связь, позволяющая нам узнать, насколько сильно мы ошибаемся.
При шаге вперед поток сигнала перемещается от входного слоя через скрытые к выходному, а решение, полученное на выходном слое, сравнивается с априорно известным верным ответом.
При шаге назад с использованием правила дифференцирования сложных функций через персептрон в обратном направлении распространяются частные производные функции, погрешности по весовым коэффициентам и смещениям. Данный акт дифференцирования дает нам градиент погрешности, с использованием которого могут быть скорректированы параметры модели, так как они приближают МП на один шаг ближе к минимуму погрешности. Это можно сделать с помощью любого алгоритма градиентной оптимизации, например, методом стохастического градиентного спуска. Сеть продолжает играть в пинг-понг, пока погрешность не исчезнет. В этом случае, как говорят, наступает сходимость.
Совершенствование персептрона
Важно отметить, что программное обеспечение и аппаратные средства существуют на блок-схеме: программное обеспечение может быть представлено как аппаратное, так и наоборот. Когда программируются микросхемы (такие как FPGA) или конструируются интегральные схемы (например, ISIC), путем вытравливания определенного алгоритма в кремнии, мы всего навсего реализуем программное обеспечение на одном уровне ниже для увеличения скорости его работы. Аналогично, то, что вытравлено в кремнии или связано с лампами и потенциометрами (например, «Mark I» Розенблатта), также может быть выражено в виде кода. Вот почему Алан Кей сказал: «Люди, которые действительно серьезно относятся к программному обеспечению, должны создавать собственное оборудование». Но бесплатный сыр бывает только в мышеловке: выигрывая в скорости работы путем вытравливания алгоритмов, вы проигрываете в возможности их модификации. Это является реальной проблемой в машинном обучении, где алгоритмы самопроизвольно изменяются по мере обработки данных. Задача состоит в том, чтобы найти те части алгоритма, которые остаются стабильными даже при изменении параметров, например, операции с линейной алгеброй, которые в настоящее время обрабатываются GPU быстрее всего.
Дальнейшее изучение вопроса может привести вас к потребности разработки все более и более сложных и полезных алгоритмов. Мы переходим от одного нейрона к совокупности нескольких, называемой слоем; затем переходим от одного слоя к совокупности нескольких, называемой многослойным персептроном. Можем ли мы перейти от одного МП к нескольким, или же мы просто будем дальше нагромождать слои, как это сделала Microsoft со своим лидером ImageNet, ResNet, в котором было более 150 слоев? Или же правильным является комбинирование МП – ансамбля многих алгоритмов, голосующих в своего рода вычислительной демократии за лучший прогноз? Или это по сути лишь встраивание одного алгоритма в другой, как это происходит со сверточными графовыми сетями?









