Статья о том, как научить машинку участвовать в гонке с помощью обучения с подкреплением, а персонажей — избегать файерболов. При этом агент способен научиться играть в игру в своем собственном «воображении». В статье — пример обучения с подкреплением (reinforcement learning) на Python с библиотекой Keras. Автор статьи — Давид Фостер.
Эта работа стоит внимания по трем причинам:
- Она сочетает в себе несколько методов глубокого обучения и обучения с подкреплением для достижения удивительных результатов — получен первый известный «агент» для популярной виртуальной среды обучения с подкреплением «Автомобильные гонки»;
- Она написана в доступном стиле, и является отличным учебным ресурсом для всех, кто интересуется передовым AI;
- Вы можете самостоятельно запрограммировать решение!
Другие полезные статьи по теме:
- Пример решения задачи по машинному обучению на Python
- Как создать собственную нейронную сеть с нуля на языке Python
Шаг 1: Постановка задачи для обучения с подкреплением
Мы собираемся построить алгоритм обучения с подкреплением (создать «агента»), который бы хорошо справлялся с вождением автомобиля на виртуальном 2D-треке. Эта среда («Автомобильные гонки») доступна через OpenAI Gym.
На каждом временном шаге алгоритм получает наблюдаемые данные трека (64×64-пиксельное цветное изображение автомобиля и ближайшего окружения, «наблюдение»), и ему необходимо вернуть набор предпринятых действий: направление рулевого управления (от -1 до 1), ускорение (от 0 до 1) и торможение (от 0 до 1). Это действие затем передается в среду, которая возвращает следующие данные трека, и цикл повторяется.
Трек разбит на N фрагментов. За посещение каждого из них агент получает 1000/N баллов, каждый потраченный временной промежуток отнимает 0,1 балла. Например, если агент проходит трек целиком за 732 кадра, вознаграждение составляет 1000 — 0,1 * 732 = 926,8 балла.

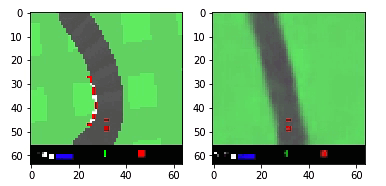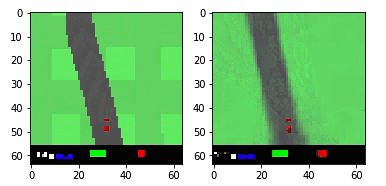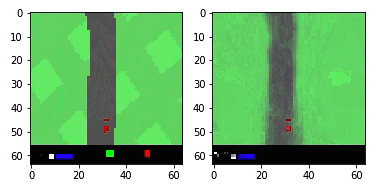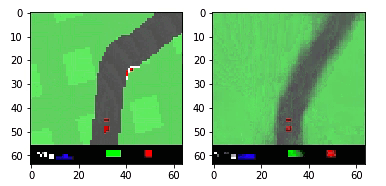
Выше представлен пример агента, который выбирает действие [0, 1, 0] для первых 200 временных шагов, а затем случайное… не самая лучшая стратегия вождения.
Цель состоит в том, чтобы научить агента понимать, что для выбора следующего лучшего действия (давить ли на газ, тормозить или поворачивать) он может использовать информацию из своего окружения.
Шаг 2: Решение
Авторы представили отличное интерактивное объяснение своей методологии, поэтому не будем вдаваться в подробности, а лучше сосредоточимся на кратком обзоре того, как части решения взаимодействуют друг с другом, и проведем аналогию с реальным вождением, чтобы объяснить интуитивный смысл.
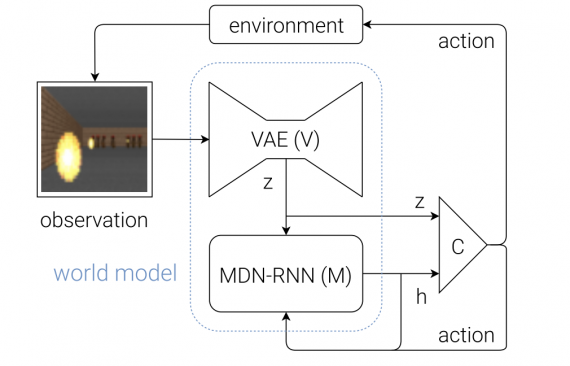
Решение состоит из трех отдельных частей, которые обучаются отдельно:
Вариационный автоэнкодер (VAE)
В процессе вождения машины вы не будете активно анализировать каждый «пиксель» того, что видите. Вместо этого ваш мозг превращает визуальную информацию в меньшее количество «скрытых» признаков, таких как прямолинейность дороги, предстоящие изгибы и позицию относительно дороги, чтобы подумать и сообщить о следующем действии.
Это именно то, чему обучается VAE — сжимать входное изображение 64x64x3 (RGB) в 32-мерный скрытый вектор z, удовлетворяющий нормальному распределению.
Такое представление визуального окружения полезно, т.к. гораздо меньше по размеру, и агент может обучаться эффективнее.
Рекуррентная нейронная сеть с сетью смеси распределений на выходе (Recurrent Neural Network with Mixture Density Network output, MDN-RNN)

Если в принятии решений вы обходитесь без компонента MDN-RNN, ваше вождение может выглядеть примерно так. Когда вы едете на машине, каждое последующее наблюдение не является для вас полной неожиданностью. Вы знаете, что если в данный момент окружение предполагает поворот налево на дороге, и вы поворачиваете колеса влево, вы ожидаете, что следующий кадр покажет, что вы все еще на одной линии с дорогой.
Подобное «мышление наперед» — суть работы RNN, сети долгой краткосрочной памяти (LSTM) с 256 скрытыми значениями. Вектор скрытых состояний обозначим за h.
Подобно VAE, RNN пытается зафиксировать внутреннее «понимание» текущего состояния автомобиля в своем окружении, но на этот раз с целью предсказать, как будет выглядеть последующий z на основе предыдущего z и совершённого действия.
Выходной слой MDN просто учитывает тот факт, что следующий z может быть фактически выведен из любого из нескольких нормальных распределений.
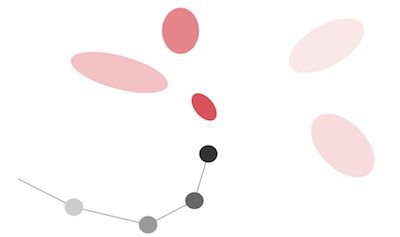
Тот же автор применил данный метод в этой статье для задачи генерации почерка, чтобы описать тот факт, что следующая точка пера может оказаться в любой из красных отдельных областей.
Аналогично, в статье «Модели мира» следующее наблюдаемое скрытое состояние может быть составлено из любого из пяти гауссовских распределений.
Контроллер
До этого момента мы ничего не говорили о выборе действия. Эта ответственность лежит на Контроллере.
Контроллер — это обычная полносвязная нейронная сеть, где вход представляет собой конкатенацию z (текущее скрытое состояние от VAE, длина 32) и h (скрытое состояние RNN, длина 256). 3 выходных нейрона соответствуют трем действиям, их значения масштабируются для попадания в соответствующие диапазоны.
Диалог
Чтобы понять разные роли трех компонентов и то, как они работают вместе, можно представить себе своеобразный диалог между ними:
VAE: (смотрит последнее наблюдение размера 64 * 64 * 3) “Это выглядит как прямая дорога, с легким левым поворотом, приближающимся к машине, движущейся вдоль дороги”.
RNN: “Из того, что мне описал VAE (вектор z) и того факта, что Контроллер решил ускориться на последнем шаге, я обновлю свое скрытое состояние (h), чтобы предсказание следующего наблюдения все еще была прямая дорога, но с чуть более сильным левым поворотом”.
Контроллер: “На основании описания из VAE (z) и текущего скрытого состояния из RNN (h) моя нейронная сеть выводит следующее действие как [0.34, 0.8, 0]”.
Затем это действие передается в окружение, которая возвращает новое наблюдение, и цикл повторяется снова.
Теперь мы рассмотрим, как настроить среду, которая позволяет вам обучать собственную версию агента для автогонок.
Пора писать код!
Шаг 3. Настройка среды
Если у вас компьютер с высокой производительностью, вы можете запускать решение локально, но я бы рекомендовал использовать Google Cloud Compute для доступа к мощным машинам.
Описанное ниже было проверено на Linux (Ubuntu 16.04); если вы используете Mac или Windows, измените соответствующие команды установки пакетов.
Склонируйте репозиторий
В командной строке, перейдите в папку, в которую вы хотите сохранить репозиторий, и введите следующее:
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
Репозиторий адаптирован из весьма полезной библиотеки estool, разработанной Дэвидом Ха, первым автором статьи «Модели мира».
Для обучения нейронной сети данная реализация использует Keras над Tensorflow, хотя в оригинальной статье авторы использовали чистый Tensorflow.
Настройте виртуальную среду
Создайте себе виртуальную среду (virtual environment) для Python 3 (я использую virutalenv и virtualenvwrapper):
sudo apt-get install python-pip sudo pip install virtualenv sudo pip install virtualenvwrapper export WORKON_HOME = ~/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh mkvirtualenv --python=/usr/bin/python3 worldmodels
Установите пакеты
sudo apt-get install cmake swig python3-dev zlib1g-dev python-opengl mpich xvfb xserver-xephyr vnc4server
Установите requirements.txt
cd WorldModels pip install -r requirements.txt
Эта команда устанавливает больше, чем нужно для примера с гонками. Зато если вы захотите протестировать другие окружения от Open AI, для которых требуются дополнительные пакеты, у вас будет все необходимое.
Шаг 4: Создание случайных «трасс»
Для среды автомобильных гонок VAE и RNN могут быть запущены на случайных данных трассы, то есть наблюдения можно генерировать случайным образом на каждом шаге. На самом деле, действия псевдослучайны, т. к. в самом начале заставляют автомобиль ускоряться, чтобы оторвать его от стартовой линии.
Поскольку VAE и RNN не зависят от принимающего решения Контроллера, все, что нам нужно — это «сохранить» в качестве учебных данных наши встречи с широким кругом наблюдений и выборы разнообразных действий.
Чтобы сгенерировать случайные трассы, выполните следующую команду из командной строки:
python 01_generate_data.py car_racing --total_episodes 2000 --start_batch 0 --time_steps 300
или же если запускаете на сервере без дисплея:
xvfb-run -a -s "-screen 0 1400x900x24" python 01_generate_data.py car_racing --total_episodes 2000 --start_batch 0 --time_steps 300
Это приведет к выпуску 2000 новых примеров трасс (сохраняются в десяти пакетах (batch) размера 200), начиная с номера 0. Каждая трасса будет иметь максимум 300 временных шагов.
Два набора файлов сохраняются в ./data, (* — номер батча)
obs_data_*.npy (сохраняет изображения 64 * 64 * 3 в виде массивов numpy)
action_data_*.npy (хранит три измерения действий)
Шаг 5: Обучение VAE
Для обучения VAE требуется только obs_data_*.npy. Убедитесь, что вы выполнили шаг 4, и эти файлы существуют в папке ./data.
В командной строке выполните:
python 02_train_vae.py --start_batch 0 --max_batch 9 --new_model
Эта команда обучит новый VAE на каждом пакете от 0 до 9.
Веса модели будут сохранены в ./vae/weights.h5. Флаг --new_model сообщает скрипту, что модель нужно строить с нуля.
Если в этой папке есть файл weights.h5 уже существует, а флаг --new_model при запуске не указан, скрипт загрузит веса из этого файла и продолжит тренировать существующую модель. Таким образом, можно итеративно обучать VAE партиями, а не за один раз.
Спецификация архитектуры VAE в файле ./vae/arch.py.

Шаг 6: Создание данных RNN
Теперь, когда у нас есть подготовленный VAE, с его помощью можно создать обучающий набор для RNN.
RNN принимает кодированное изображение z из VAE и вектор команд управления a в качестве входных данных, в качестве выхода — вектор z на один временной шаг вперед.
Сгенерировать эти данные можно, выполнив:
python 03_generate_rnn_data.py --start_batch 0 --max_batch 9
Это потребует наличия файлов obs_data_*.npy и action_data_*.npy из батчей от 0 до 9, и сконвертирует их в правильный формат, необходимый для обучения RNN.
Два набора файлов будут записаны в ./data, (* — номер батча):
rnn_input_*.npy (сохраняет сконкатенированные векторы [z a])
rnn_output_*.npy (сохраняет следующий по времени вектор z)

Шаг 7: Обучение рекуррентной нейросети
Для обучения RNN требуется только rnn_input_*.npy и rnn_output_*.npy. Убедитесь, что вы успешно выполнили шаг 6, и файлы находятся в папке ./data.
В командной строке выполните:
python 04_train_rnn.py --start_batch 0 --max_batch 9 --new_model
Это запустит процессы обучения новых RNN для каждого пакета данных от 0 до 9.
Веса модели будут сохранены в ./rnn/weights.h5. Флаг --new_model сообщает скрипту, что модель нужно подготавливать с нуля.
Аналогично VAE, если в этой папке weights.h5 существуют, а флаг --new_model не указан, скрипт загрузит веса из этого файла и продолжит тренировку существующей модели. Аналогично это позволяет итеративно обучать RNN партиями.
Спецификация архитектуры RNN находится в файле ./rnn/arch.py.

Шаг 8: Обучение контроллера
Теперь забавная часть! До сих пор мы просто применяли Deep Learning для создания VAE, который способен «сжимать» изображения большого размера вплоть до низкоразмерного пространства, и обучения RNN, предсказывающего, как со временем будет изменяться скрытый вектор. Это было возможно, потому что мы смогли создать обучающие наборы данных, используя данные случайных карт.
Для обучения контроллера мы будем применять особую форму обучения с подкреплением. В ней используется эволюционный алгоритм, известный под названием CMA-ES (Covariance Matrix Adaptation — Evolution Strategy).
Так как вход представляет собой вектор размерности 288 (= 32 + 256), а выход — вектор размерности 3, то для тренировки мы имеем 288 * 3 + 1 (смещение) = 867 параметров.

CMA-ES работает, сначала создавая несколько случайно инициализированных копий 867 параметров («популяцию»). Затем он тестирует каждого члена популяции на трассе и записывает его средний балл. По принципу естественного отбора, наборам весов, которые получают самые высокие баллы, разрешено «воспроизводиться» и порождать следующее поколение.
Чтобы запустить этот процесс на вашем компьютере, выполните следующую команду с соответствующими значениями для аргументов:
python 05_train_controller.py car_racing --num_worker 16 --num_worker_trial 2 --num_episode 4 --max_length 1000 --eval_steps 25
или на сервере без дисплея:
xvfb-run -s "-screen 0 1400x900x24" python 05_train_controller.py car_racing --num_worker 16 --num_worker_trial 2 --num_episode 4 --max_length 1000 --eval_steps 25
--num_worker 16 : установите это значение не большим, чем количество доступных ядер
--num_work_trial 2 : количество представителей популяции, которое будет тестировать каждый поток (num_worker * num_work_trial дает общий размер популяции для каждого поколения)
--num_episode 4 : количество тестовых запусков каждого члена популяции (таким образом, оценка будет средним по баллам за это количество эпизодов)
--max_length 1000 : максимальное количество временных шагов в эпизоде
--eval_steps 25 : количество поколений до выбора наилучшего набора весов, через 100 эпизодов
--init_opt ./controller/car_racing.cma.4.32.es.pk По умолчанию контроллер запускается с нуля каждый раз при его запуске и сохраняет текущее состояние процесса в файле pickle в каталоге controller. Этот аргумент позволяет продолжить обучение с последней точки сохранения, указав ее в соответствующем файле.
После каждого поколения текущее состояние алгоритма и лучший набор весов будут выводиться в папку ./controller.

Шаг 9: Визуализация работы агента
На момент написания статьи мне удалось подготовить агента для достижения среднего балла ~833,13 после 200 поколений обучения. Запуски проводились в Google Cloud под Ubuntu 16.04, 18 vCPU, 67,5 ГБ оперативной памяти с шагами и параметрами, приведенными в этом уроке.
Авторам статьи удалось достичь среднего балла ~906, после 2000 поколений обучения, который считается самым высоким показателем в этой виртуальной среде на сегодняшний день. Были использованы несколько более высокие настройки (например, 10 000 эпизодов учебных данных, 64 размер популяции, 64-ядерная машина, 16 эпизодов за испытание и т. д.).
Чтобы визуализировать текущее состояние вашего контроллера, запустите:
python model.py car_racing --filename ./controller/car_racing.cma.4.32.best.json --render_mode --record_video
--filename : путь к json-файлу весов, который вы хотите подключить к контроллеру
--render_mode : отображение среды на экране
--record_video : выводит файлы mp4 в папку ./video, показывая каждый эпизод
--final_mode : выполняет 100 эпизодов в тестовом режиме контроллера и выводит средний балл.
Пример работы


Шаг 10: Обучение «в воображении»
Уже увиденнные нами вещи довольно круты, но следующая часть статьи просто потрясает мозг, и, полагаю, может серьезно повлиять на развитие ИИ.
Далее в статье описываются другие удивительные результаты, на основе другой среды DoomTakeCover. Здесь цель состоит в том, чтобы перемещать агента, избегать огненных шаров и оставаться в живых как можно дольше.
Агент действительно способен научиться играть в игру в своем собственном «воображении», построенном VAE/RNN, а не внутри самой окружающей среды.
Единственное обязательное дополнение состоит в том, что RNN обучается также прогнозировать вероятность быть убитым на следующем шаге. Таким образом, комбинация VAE/RNN может быть обернута как самостоятельная среда и использоваться для обучения Контроллера. Это и есть концепция «Моделей мира».
Мы могли бы описать обучение с воображением следующим образом:
- Первоначальные данные обучения агента представляют собой не что иное, как случайное взаимодействие с реальной средой. Благодаря этому он создает скрытое понимание того, как мир «работает» — его естественные признаки, физика и то, как собственные действия агента влияют на состояние мира.
- Затем он может использовать это понимание, чтобы установить оптимальную стратегию для поставленной задачи, не проверяя при этом ее в реальном мире. Эта проверка не требуется потому, что агент может использовать свою собственную внутреннюю, скрытую модель окружающей среды как «игровую площадку» для того, чтобы попытаться разобраться в том, что происходит.
Можно провести сравнение с ребенком, учащимся ходить — поразительные сходства! Возможно, это глубже, чем просто аналогия, что делает задачу по-настоящему увлекательной областью исследований.