
Сейчас многие интересуются машинным обучением и анализом данных. После чтения книг и работы с обучающими курсами по машинному обучению на python может возникнуть ощущение, что полноценная картина не складывается. В таком состоянии браться за реальную задачу совсем не хочется, но выбрать задачу по душе и довести её до конца — лучший способ набраться уверенности в собственных силах. Представляем детальный разбор реальной задачи из сферы Data science.
Чтобы научиться анализу данных на языке Python, использовать библиотеки и визуализировать данные, рекомендуем пройти недорогой курс Python для анализа данных от Skypro. За 2,5 месяца вы научитесь использовать инструменты, описанные в этой статье.
Читайте также:
В общем случае процесс решения задач возникающих в машинном обучении состоит из следующих этапов:
- Очистка и форматирование данных
- Предварительный анализ данных
- Выбор наиболее полезных признаков и создание новых более репрезентативных
- Сравнение качества работы нескольких моделей
- Оптимизация гиперпараметров в лучшей модели
- Проверка модели на тестовой выборке
- Интерпретация результатов
- Итоговое представление результатов работы
По пути увидите, как каждый новый этап выходит из предыдущего.
Постановка задачи
Постановка задачи и оценка имеющихся данных — первый шаг на пути к решению. Cделать это нужно ещё до того, как будет написана первая строчка кода.
Наши данные — открытые сведения о энергопотреблении зданий в Нью-Йорке.
Наша цель — предсказать рейтинг энергопотребления (Energy Star Score) здания и понять, какие признаки оказывают на него сильнейшее влияние.
Данные уже содержат в себе Energy Star Score, так что задача относится к классу задач машинного обучения с учителем, и представляет собой построение регрессии:
- Обучение с учителем: у нас есть как все необходимые признаки, на основе которых выполняется предсказание, так и сам целевой признак.
- Регрессия: будем считать, что рейтинг энергопоребления — это непрерывная величина.
В конечном итоге нужно построить как можно более точную модель, которая на выходе дает легкоинтерпретируемые результаты, т.е. мы сможем понять на основании чего модель делает тот или иной вывод. Грамотно поставленная задача уже содержит в себе решение.
Чистка данных
Вопреки тому, какое впечатление может сложиться после посещения различных курсов и чтения статей по машинному обучению, данные не всегда представляют собой идеально организованный набор наблюдений без каких-либо пропусков или аномалий (например, можно взглянуть на известные наборы данных mtcars и iris). Обычно данные содержат в себе кучу мусора, который необходимо почистить, да и вообще сами данные порой лучше воспринимать критически, для того чтобы затем привести их в приемлемый формат. Чистка данных — это необходимый этап решения почти любой реальной задачи.
Для начала можно используя Pandas загрузить данные в DataFrame:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# Display top of dataframe
data.head()
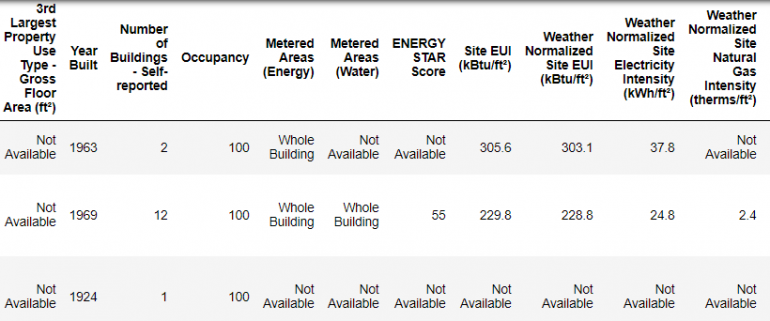
Это только фрагмент данных, весь набор содержит 60 признаков. Уже заметна пара проблем: во-первых, мы уже знаем, что хотим предсказать ENERGY STAR Score, но хорошо бы понять, что из себя представляют остальные признаки. Это не всегда проблема, иногда удается построить качественную модель, не имея почти никакого представления о том, что признаки из себя представляют. Но для нас важна интерпретируемость, поэтому важно понимать, что несут в себе основные признаки.
Я начал с того, что вдумчиво прочитал название файла и решил почитать немного про «Local Law 84». Это привело меня сюда, после чего стало ясно, что это закон, действующий на территории Нью-Йорка, требующий владельцев всех зданий определенных габаритов предоставлять отчеты о потреблении электроэнергии. Поискав ещё немного, я даже нашел описание всех признаков.
Название файла, возможно, очевидное место для начала анализа, но торопиться при анализе не стоит, чтобы не упустить ничего важного.
Не все признаки для нас одинаково важны, но с нашим целевым признаком точно нужно разобраться. А он представляет собой «Оценку в баллах от 1 до 100 основанную на предоставленных сведениях о потреблении электроэнергии. Рейтинг энергопотребления это относительная величина, используемая для сравнения эффективности использования энергии различными зданиями.»
Пожалуй, с первой проблемой мы справились. Есть ещё одна: пропущенные данные, вставленные в набор, выглядят как строка с записью “Not Available”. Это означает, что Python, даже если эта колонка содержит в себе преимущественно числовые признаки, будет интерпретировать её как тип данных object, потому что Pandas интерпретируют любой признак содержащий строковые значения как строку. Посмотреть на то, какой тип данных имеет тот или иной признак, можно, используя метод dataframe.info():
# See the column data types and non-missing values data.info()
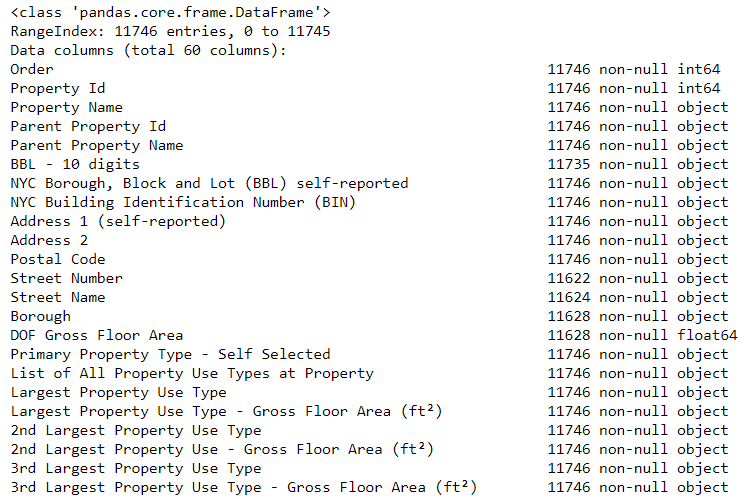
Очевидно, многие признаки, являющиеся изначально числовыми (например, площади), интерпретированы как object. Анализировать их крайне сложно, так что сначала конвертируем их в числа, а именно в тип float.
Заменим значение “Not Available” в данных на «не число» ( np.nan — «not a number»), которое Python все же интерпретирует как число. Это позволит изменить тип соответствующих числовых признаков на float:
Как только числовые признаки стали числами, за них уже можно браться всерьез.
Пропущенные данные и выбросы
В добавок к некорректному определению типов данных, другая частая проблема — это пропуски в данных. У наличия пропусков могут быть разные причины, но пропуски нужно либо заполнить, либо исключить из набора полностью. Для начала попробуем оценить масштаб проблемы (код можно посмотреть в тетрадке).
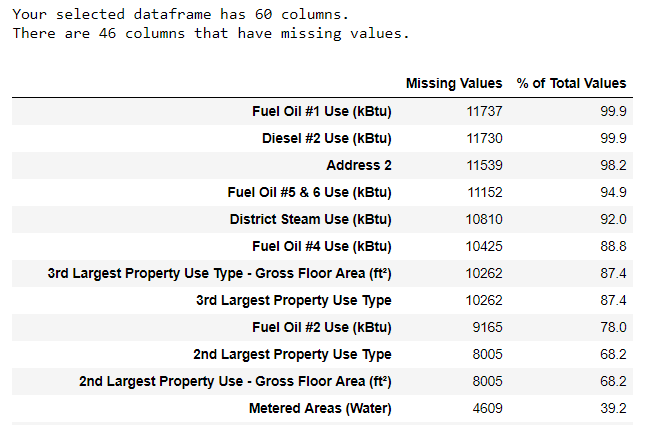
(Для того чтобы построить эту таблицу, я воспользовался кодом со Stack Overflow Forum).
При удалении данных следует быть осторожным, тем не менее, признак нам вряд ли вообще пригодится, если пропусков в нем слишком много. В данном случае я решил удалить признаки, в которых пропусков больше 50%.
Затем стоит избавиться от выбросов. Они могут быть связаны с опечатками, ошибками в единицах измерения или являться корректными, но чересчур экстремальными значениями. Я решил удалить аномальные значения полагаясь на данный критерий:
- Ниже первой квартили, минус 3 ∗ межквартильных расстояния
- Выше третьей квартили, плюс 3 ∗ межквартильных расстояния
(Код содержится в упомянутой тетрадке). На этом этапе в наборе остается более 11,000 записей (строений) и 49 признаков.
Предварительный анализ данных
Теперь когда утомительный, но совершенно необходимый — этап чистки данных закончен, можно углубляться в анализ. Предварительный анализ данных (Exploratory Data Analysis — EDA) — это процесс который можно продолжать до бесконечности, на этом этапе мы строим графики, ищем закономерности, аномалии или связи между признаками.
В общем цель этого этапа понять что эти данные могут дать нам. Обычно процесс начинается с обзора всего набора, затем переходит к его специфическим подмножествам. Любые находки могут быть по-своему интересны, также они могут дать нам ценные подсказки, например, по поводу относительной значимости различных признаков.
Графики от одной переменной
Напомню, что цель — это предсказание значения целевого признака, рейтинга энергопотребления (переименуем его в score в нашем наборе), так что целесообразно для начала понять, какое эта величина имеет распределение. Посмотрим на него, построив гистограмму с matplotlib.
import matplotlib.pyplot as plt
# Histogram of the Energy Star Score
plt.style.use('fivethirtyeight')
plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k');
plt.xlabel('Score'); plt.ylabel('Number of Buildings');
plt.title('Energy Star Score Distribution');
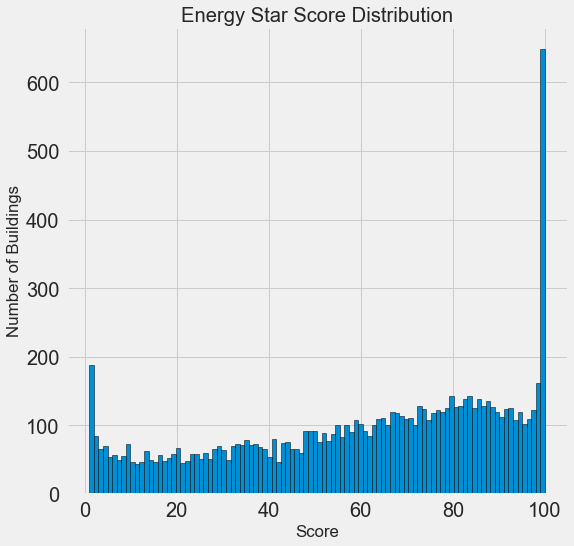
Пока выглядит довольно подозрительно. Интересующий нас рейтинг представляет собой перцентиль, так что ожидаемо было бы увидеть равномерное распределение, где каждому значению соответствует примерно одинаковое количество зданий. Хотя в нашем случае на лицо диспропорция, больше всего зданий имеют максимальное значение рейтинга — 100, либо минимальное — 1 (высокий рейтинг это хороший показатель).
Обратимся к описанию признака и вспомним, что он основывается на “предоставляемых отчетах об энергопотреблении”. Это, возможно, кое-что объясняет. Просить владельцев зданий отчитаться об эффективности использования электроэнергии, это почти то же самое, что просить поставить студента оценку самому себе на экзамене. В результате мы получаем не самую объективную оценку эффективности использования электроэнергии в зданиях.
Если бы время не было ничем ограничено, стоило бы выяснить, почему большинство зданий имеют слишком высокие или слишком низкие значения рейтинга. Для этого нужно отфильтровать записи по этим зданиям и посмотреть, что у них общего. В нашу задачу не входит изобретение метода новой оценки эффективности энергопотребления, так что лучше сфокусироваться на предсказании рейтинга с тем, что есть.
В поисках отношений
Значительную часть работы на этапе EDA занимает поиск взаимосвязей между различными признаками. Очевидно что признаки и значения признаков, оказывающие основное влияние на целевой, интересуют нас сильнее, чем прочие, по ним лучше всего и предсказывать значение целевого. Одним из способов оценить влияние значений категориальных признаков (число значений такого признака подразумевается конечным) на целевой — density plot, например, используя модуль seaborn.
Density plot можно представить себе как сглаженную гистограмму, потому что она показывает распределение одного значения категориально признака. Раскрасим распределения разными цветами и посмотрим на распределения. Код ниже строит density plot рейтинга энергопотребления. Разными цветами показаны рейтинги различных типов зданий (рассмотрены типы с как минимум сотней записей в нашем наборе):
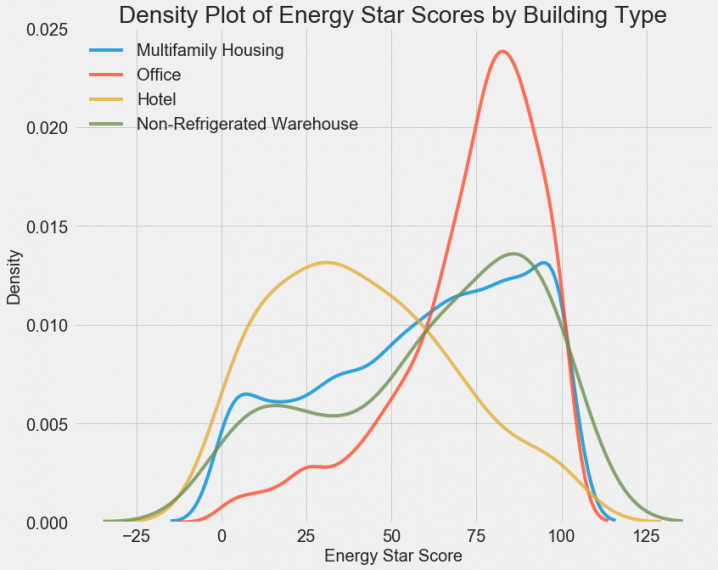
Видно, что тип здания оказывает существенное влияние на рейтинг энергопотребления. Здания, используемые как офисы, чаще имеют хороший рейтинг, а отели наоборот. Получается, такой признак, как тип здания, для нас важен. Так как это признак категориальный, нам ещё предстоит выполнить с ним так называемый «one-hot encode».
То же самое посмотрим для различных районов:
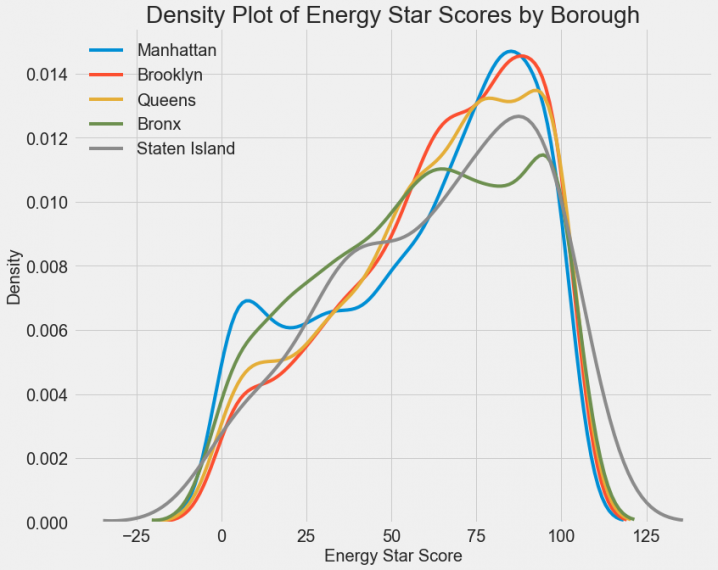
Похоже, что район оказывает уже не такое большое влияние. Тем не менее, пожалуй, стоит включить этот признак в модель, так как определенная разница между районами все же есть.
Чтобы численно оценить степень влияния признаков можно использовать коэффициент корреляции Пирсона. Это мера степени и положительности линейных связей между двумя переменными. Значение в +1 означает идеальную пропорциональность между значениями признаков и, соответственно, в -1 аналогично, но с отрицательным коэффициентом. Несколько значений коэффициента корреляции показаны ниже:
Несмотря на то что это не дает нам никакого понятия о непропорциональных взаимосвязях, это уже хорошее начало. В Pandas рассчитать величину корреляции довольно легко:
# Find all correlations with the score and sort correlations_data = data.corr()['score'].sort_values()
Самые высокие отрицательные и положительные корреляции с целевым признаком:


Можно видеть что есть несколько признаков имеющих высокие отрицательные значения коэффициента Пирсона, с самой большой корреляцией для разных категорий EUI (они между собой слегка отличаются по способу расчета). EUI — Energy Use Intensity — это количество использованной энергии, разделенное на площадь помещений в квадратных футах. Значит, чем этот признак ниже, тем лучше. Соответственно: с ростом EUI, рейтинг энергопотребления становится ниже.
Графики от двух переменных
Чтобы посмотреть на связь между двумя непрерывными переменными, можно использовать scatterplots (точечные графики). Дополнительную информацию, такую как значения категориальных признаков, можно показывать различными цветами. Например, график снизу показывает разброс рейтинга энергопотребления в зависимости от величины Site EUI, а разными цветами показаны типы зданий:
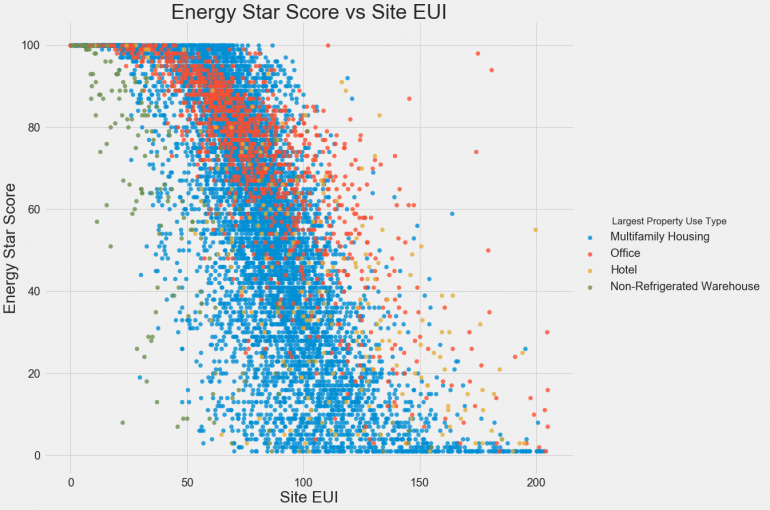
Этот график наглядно демонстрирует, что такое коэффициент корреляции со значением -0.7. Site EUI уменьшается, и рейтинг энергопотребления уверенно возрастает, независимо от типа здания.
Ну и наконец, построим Pairs Plot. Это мощный исследовательский инструмент, он позволяет взглянуть на взаимосвязи сразу между несколькими признаками одновременно, а так же на их распределение. В примере при построении использовался модуль seaborn и функция PairGrid. Построен Pairs Plot со scatterplots выше главной диагонали, гистограммами на главной диагонали и 2D kernel density plots, с указанием корреляции, ниже главной диагонали.
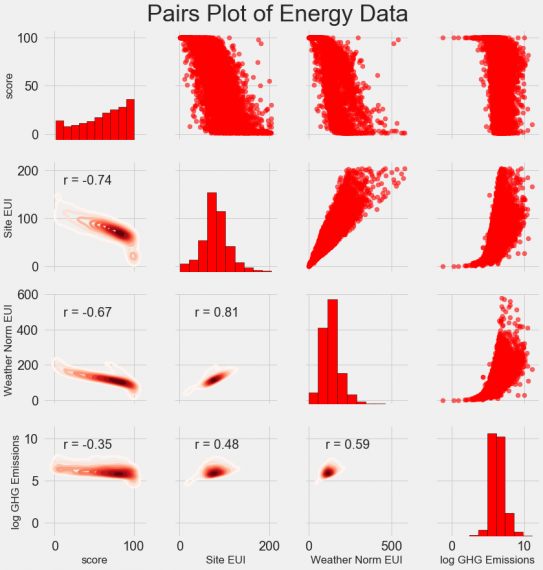
Чтобы посмотреть на интересующие нас отношения между величинами, ищем пересечения строк и колонок. Например, чтобы взглянуть на корреляцию между Weather Norm EUI со score, смотрим на строку Weather Norm EUI и колонку score. Видно, что коэффициент Пирсона равен -0.67. Помимо того, что график красиво выглядит, он ещё может помочь понять, какие признаки стоит включить в нашу модель.
Выбор и создание новых признаков
Выбор и создание новых признаков зачастую оказывается одним из самых «благодарных» занятий по соотношению усилия/вклад в результат. Для начала, пожалуй, поясню что это такое:
- Создание новых признаков (Feature engineering): процесс при котором берутся данные как они есть и затем на основе имеющихся данных конструируются новые признаки. Это может означать изменение непосредственно самих значений, например логарифмирование, взятие корня, или one—hot encoding категориальных признаков для того чтобы модель могла их эти признаки обработать. Иногда это создание совершенно новых признаков, которые раньше явным образом в данных не содержались, но, в общем, это всегда добавление в набор новых признаков, полученных из первоначальных данных.
- Выбор признаков (Feature selection): процесс выбора наиболее релевантных признаков. При этом из набора удаляются признаки для того чтобы модель уделила больше внимания и ресурсов первостепенным признакам, а также это помогает получить более легкоинтерпретируемые результаты. В общем, это чистка набора при которой остаются только наиболее важные для нашей задачи данные.
В машинном обучении модель обучается целиком на данных которые мы подаем на вход модели, так что важно быть уверенным в том что все ключевые данные для эффективного решения задачи у нас есть. Если данных способных нам обеспечить решение задачи у нас нет, то какой бы модель не была хорошей, научить мы её ничему не сможем.
На данном этапе я выполнил следующую последовательность действий:
- One-hot кодирование категориальные признаков (район и тип здания);
- Логарифмирование числовых данных.
One-hot кодирование необходимо выполнить для того, чтобы модель могла учесть категориальные признаки. Модель не сможет понять, что имеется ввиду, когда указано, что здание используется как “офис”. Нужно создать новый соответствующий признак и присвоить ему значение 1, если данная запись содержит сведения об офисе и 0 в противном случае.
При применении различных математических функций к значениям в наборе модель способна распознать не только линейные связи между признаками. Взятие корня, логарифмирование, возведение в степень и т.д. — распространенная в науке о данных практика, и она может основываться на наших представлениях о поведении и связях между признаками, а так же просто на эмпирических сведениях о том, при каких условиях модель работает лучше. Тут я, как уже упоминалось, решил взять натуральный логарифм от всех числовых признаков.
Приведенный ниже код этим и занимается: логарифмирует числовые признаки, а так выделяет два упомянутых категориальных признака и применяет к ним one-hot кодирование. Затем объединяет полученные при этом наборы. Звучит довольно утомительно, но Pandas позволяет это проделать относительно легко.
В итоге в нашем наборе теперь всё ещё 11,000 записей (зданий) и 110 колонок (признаков). Не все эти признаки одинаково важны для нашей задачи, так что перейдем к следующему шагу.
Выбор признаков
Многие из 110 признаков для нашей модели избыточны, т.к. некоторые из них сильно коррелируют. Например, зависимость Site EUI от Weather Normalized Site EUI, которая имеют коэффициент корреляции 0.997.
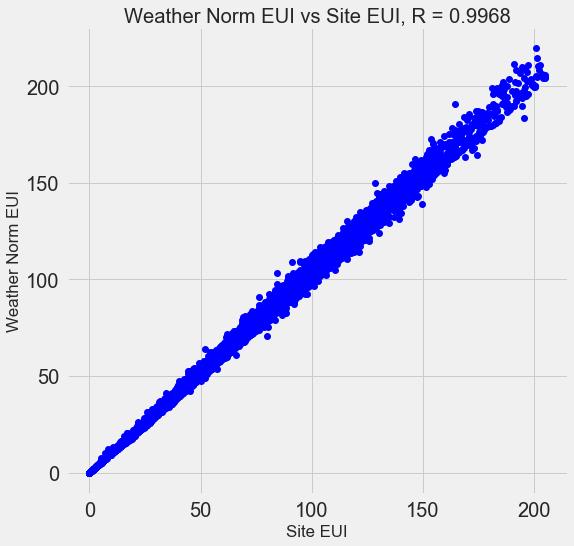
Признаки, которые сильно коррелированны, называют коллинеарными, и достаточно оставить один из таких признаков, чтобы помочь алгоритму лучше обобщать и получать более интерпретируемые результаты на выходе (на всякий случай уточню, что речь идет о признаках коррелированных между собой, а не с целевым признаком, последние очень даже помогают нашему алгоритму.)
Есть много способов поиска коллинеарных признаков, например, один из широко используемых — расчет коэффициента увеличения дисперсии. Сам я решил использовать так называемый thebcorrelation коэффициент. Один из двух признаков будет автоматически удален если коэффициент корреляции для этой пары выше 0.6. Посмотреть как именно это было реализовано можно в той же тетрадке (и на форуме Stack Overflow)
Выбор именно такого порога может показаться необоснованным, но он был установлен опытным путем, при решении этой конкретной задачи. Машинное обучение наука в значительной степени экспериментальная и зачастую сводится к произвольному поиску лучших параметров безо всякого обоснования. В итоге оставим всего 64 признака и один целевой.
# Remove any columns with all na values features = features.dropna(axis=1, how = 'all') print(features.shape) (11319, 65)
Оцениваем результат работы алгоритма
Уже выполнена чистка данных, предварительный анализ, оставлены только полезные признаки. Последний шаг перед началом обучения модели — определение критерия, по которому можно понять, есть ли хоть какой-то толк от нашего алгоритма. Например, можно сравнить результат работы модели с попыткой просто угадать целевой признак, ничем особым не руководствуясь. Если наш алгоритм работает хуже, чем неосмысленный перебор возможных значений целевого признака, тогда стоит попробовать другой подход, возможно, даже не связанный с машинным обучением.
Для задач регрессии таким возможным критерием можем выступать подстановка медианных значений целевого признака в качестве догадки. Хотя это довольно низкий порог для большинства алгоритмов.
В качестве метрики я решил использовать среднее абсолютное отклонение (mean absolute error (MAE)), название дает исчерпывающее представление о том, что это за величина. Метрика довольно легко рассчитывается, и она наглядна. Мне нравится совет Andrew Ng, который рекомендует выбрать какую-то одну и на протяжении выполнения всех оценок пользоваться ей.
До расчета упомянутого критерия, нужно разделить выборку на обучающую и проверочную (тестовую):
- Обучающая выборка это набор который подается на вход модели в процессе обучения вместе с ответами, с целью научить модель видеть связь между этими признаками и правильным ответом
- Тестовая выборка используется для проверки модели. Модель не получает целевой признак на вход и, более того, должна предсказать его величину используя значения остальных признаков. Эти предсказания потом сравниваются с реальными ответами.
Используем 70% записей для обучения и на 30% проверим работу:
# Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42)
Теперь все готово для расчета:
The baseline guess is a score of 66.00 Baseline Performance on the test set: MAE = 24.5164
При такой грубой оценке в наш интервал не попало всего 25 точек возможных значений целевого признака. Значения самого признака изменяются в диапазоне от 1 до 100, так что ошибка составила 25%, что, вообще говоря, не самый выдающийся показатель.
Заключение
В этой статье рассмотрены первые три характерных этапа решения задачи в машинном обучении:
- Очистка и форматирование данных;
- Предварительный анализ данных;
- Выбор наиболее полезных признаков, а так же создание новых и более репрезентативных.
Наконец, мы также определили порог, по которому будем оценивать применимость наших моделей.
Twitter автора: @koehrsen_will.
Само решение можно посмотреть на GitHub, начало здесь.
Интересные статьи:
- Прогнозирование фондового рынка на Python с помощью Stocker
- Генеративно-состязательная нейросеть (GAN). Руководство для новичков
- Как применять теорему Байеса для решения реальных задач









Отличная статья, я только начинающий, но мне было многое понятно и очень интересно. Спасибо!