
Прогнозирование фондового рынка — это заманчивый «философский камень» для специалистов по анализу данных, которые мотивированы не столько стремлением к материальной выгоде, сколько самой задачей. Ежедневный рост и падение рынка наводят на мысль, что должны быть закономерности, которым мы или наши модели могут научиться, чтобы победить всех этих трейдеров с научными степенями по бизнесу.
Когда я начал использовать аддитивные модели для прогнозирования временных рядов, я протестировал метод на эмуляторе фондового рынка с имитируемыми (ненастоящими) акциями. Неизбежно я присоединился к другим несчастным, которые ежедневно терпят неудачу на рынке. Тем не менее, в процессе я узнал массу нового о Python, включая объектно-ориентированное программирование, манипулирование данными, построение моделей и визуализацию. Также выяснилось, почему не стоит рассчитывать на ежедневную рыночную игру без потери единой копейки (все, что я могу сказать — играть нужно долгосрочно)!
В любой задаче, не только в Data science, если не удалось достичь желаемого, есть три варианта:
- Изменить результаты так, чтобы они выглядели в выгодном свете;
- Скрыть результаты — никто не заметит провала;
- Показать результаты и методы всем, чтобы люди могли чему-то научиться и, возможно, предложить улучшения.
В то время как третий вариант — оптимальный выбор на индивидуальном и общественном уровне, он требует наибольшего мужества. Ведь я могу специально демонстировать особые случаи, когда моя модель приносит прибыль. Или можно притвориться, что я не потратил десятки часов на работу, и просто выбросить её. Как глупо! На самом деле, только неоднократно потерпев неудачу и допустив сотню ошибок, мы двигаемся вперед. Более того, код Python, написанный для такой сложной задачи, не может быть написан напрасно!
Этот пост документирует возможности Stocker, инструмента прогнозирования рынка, разработанного мной на Python. В предыдущей статье я показал, как использовать Stocker для анализа, а для тех, кто хочет опробовать его самостоятельно или внести свой вклад в проект, полный код доступен на GitHub.
Stocker для прогнозирования
Stocker — инструмент Python для прогнозирования рынка. Как только будут установлены необходимые библиотеки (см. документацию), можно запустить Jupyter Notebook в той же папке, что и скрипт, и импортировать класс Stocker:
from stocker import Stocker
Класс теперь доступен для сеанса Jupyter. Создадим объект класса Stocker, передавая ему любой действительный тикер, например, ‘AMZN’ (вывод программы выделен жирным шрифтом):
amazon = Stocker('AMZN')
AMZN Stocker Initialized. Data covers 1997-05-16 to 2018-01-18.
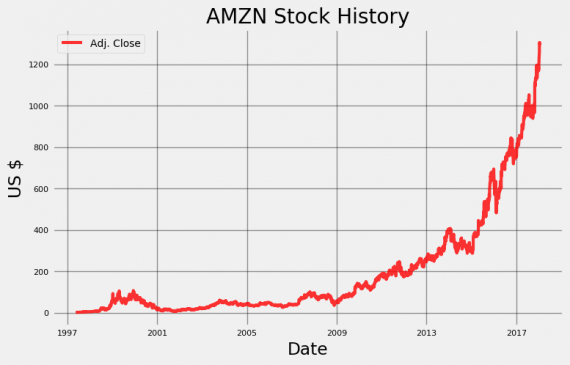
Теперь к нам в распоряжение попали 20 лет ежедневных данных по акциям Amazon для исследований! Stocker построен на финансовой библиотеке Quandl и содержит более 3000 курсов акций для использования. Построим простой график курса, вызывая метод plot_stock:
amazon.plot_stock() Maximum Adj. Close = 1305.20 on 2018-01-12. Minimum Adj. Close = 1.40 on 1997-05-22. Current Adj. Close = 1293.32.
Stocker применяют для обнаружения и анализа общих трендов и закономерностей, но сейчас сосредоточимся на прогнозировании будущей цены. Предсказания в Stocker производятся с использованием аддитивной модели, которая рассматривает временные ряды как комбинацию тренда и сезонных изменений в разных временных масштабах (ежедневный, еженедельный и ежемесячный). Stocker использует «предсказательный» пакет, разработанный FAIR для аддитивного моделирования. Создание модели и прогнозирование можно выполнить в Stocker одной строкой:
# предсказать на дни вперед model, model_data = amazon.create_prophet_model(days=90) Predicted Price on 2018-04-18 = $1336.98
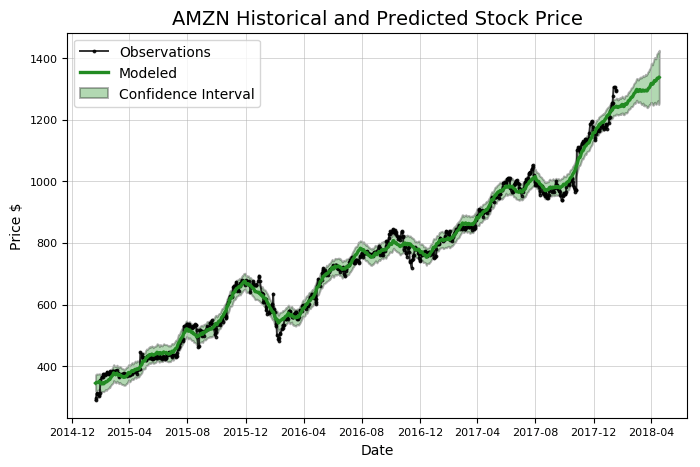
Обратите внимание, что прогноз (зеленая линия) содержит доверительный интервал. Он отражает «неуверенность» модели в предсказании. В данном случае ширина доверительного интервала устанавливается с уровнем доверия 80%. Доверительным называют интервал, который покрывает неизвестный параметр с заданной надёжностью. Он расширяется с течением времени, потому что оценка имеет большую неопределенность по мере того, как она удаляется от имеющихся данных. Каждый раз, делая прогноз, следует включать этот доверительный интервал. Хотя большинство людей, как правило, хотят получить простой численный ответ, прогноз отражает то, что мы живем в неопределенном мире!
Дать предсказание нетрудно: достаточно выбрать некоторое число, и это будет предположением о будущем (возможно, я ошибаюсь, но это всё, что делают люди с Уолл-стрит). Но этого мало. Чтобы доверять модели, нужно оценить ее точность. Для этого в Stocker существует ряд методов.
Оценка прогнозов
Чтобы вычислить точность прогнозов, нам нужен обучающий и тестовый наборы данных. Для тестового набора необходимо знать ответы — фактическую цену акций, поэтому мы будем использовать данные курса за прошлый год (2017, в нашем случае). Во время обучения мы не позволим модели видеть ответы тестового набора, поэтому используем наблюдения за предшествующие три года (2014-2016). Основная идея обучения с учителем (supervised learning) заключается в том, что модель изучает закономерности и отношения в данных из обучающего набора, а затем умеет правильно воспроизводить их на тестовой выборке.
Чтобы количественно оценить точность, на основе предсказанных и фактических значений вычисляются следующие показатели:
- средняя численная ошибка в долларах на тестовом и обучающем наборе;
- процент времени, когда мы правильно предсказали направление изменения цены;
- процент времени, когда фактическая цена попала в пределы прогнозируемого доверительного интервала в 80%.
Все вычисления автоматически выполняются Stocker с приятным визуальным сопровождением:
amazon.evaluate_prediction() Prediction Range: 2017-01-18 to 2018-01-18. Predicted price on 2018-01-17 = $814.77. Actual price on 2018-01-17 = $1295.00. Average Absolute Error on Training Data = $18.21. Average Absolute Error on Testing Data = $183.86. When the model predicted an increase, the price increased 57.66% of the time. When the model predicted a decrease, the price decreased 44.64% of the time. The actual value was within the 80% confidence interval 20.00% of the time.
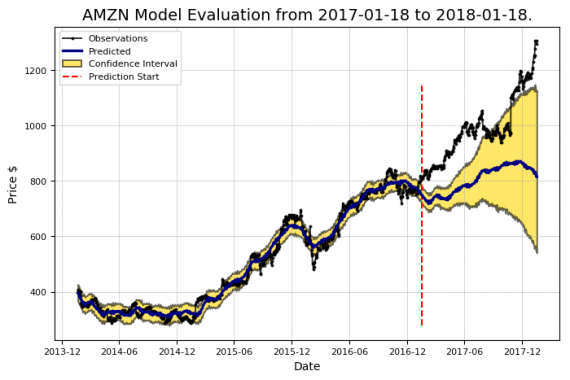
Это ужасная статистика! С таким же успехом можно каждый раз подбрасывать монету. Если бы мы руководствовались полученными результатами для инвестиций, нам разумней было бы вложиться в лотерейные билеты. Однако пока не будем отказываться от модели. Изначально она ожидаемо будет довольно плохой, потому что использует некоторые настройки по умолчанию (называемые гиперпараметрами).
Если наши первоначальные попытки не увенчались успехом, мы можем нажимать эти своеобразные рычаги и кнопки, чтобы заставить модель работать лучше. В Prophet можно настроить множество параметров, причем наиболее важным является коэффициент масштаба распределения весов для контрольных точек (changepoint prior scale). Он отвечает за набор весов, который накладывается на развороты и флуктуации тренда.
Настройка выбора контрольных точек
Контрольные точки (changepoints) — это места, где временные ряды значительно меняют направление или скорость изменения цены (от медленно возрастающего до все более быстрого или наоборот). Коэффициент масштаба распределения весов для контрольных точек (changepoint prior scale) отражает количество «уделенного внимания» точкам изменения курса акций. Это используется для контроля над недообучением и переобучением модели (также известный как bias-variance tradeoff).
Проще говоря, чем выше этот коэффициент, тем сильнее учитываются контрольные точки и достигается более гибкая подгонка. Это может привести к переобучению, поскольку модель будет тесно привязываться к обучающим данным и терять способность к обобщению. Снижение этого значения уменьшает гибкость и вызывает противоположную проблему — недообучение.
Модель в таком случае недостаточно «внимательно» следит за обучающими данными и не выявляет основные закономерности. Как правильно подобрать этот параметр — вопрос скорее практический, нежели теоретический, и здесь будем полагаться на эмпирические результаты. Класс Stocker содержит два разных метода для выбора соответствующего значения: визуальный и количественный. Начнем с визуального метода.
# changepoint priors is the list of changepoints to evaluate amazon.changepoint_prior_analysis(changepoint_priors=[0.001, 0.05, 0.1, 0.2])
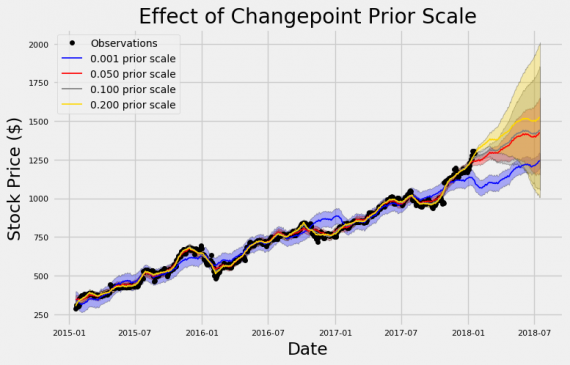
Здесь мы обучаемся на данных за три года, а затем показываем прогноз на шесть следующих месяцев. Сейчас мы не оцениваем прогнозы количественно, а лишь пытаемся понять роль распределения контрольных точек. Этот график отлично демонстрирует проблему недо- и переобучения!
При самом низком значении prior scale (синяя линия) значения недостаточно близко накладывается на обучающие данные (черная линия). Они словно живут своей жизнью, лишь немного приближаясь возрастающему тренду истинных данных. Напротив, самый высокий prior (желтая линия) сильнее приближает модель к учебным наблюдениям. Значение по умолчанию составляет 0.05, которое находится где-то между двумя крайностями.
Обратите внимание также на разницу в неопределенности (закрашенные интервалы) для разных коэффициентов масштаба:
- Самое маленькое из prior дает наибольшую неопределенность в обучающих данных и наименьшую в тестовом наборе.
- Напротив, наивысший prior scale имеет наименьшую неопределенность в тренировочном и наибольшую в тестовом.
Чем выше prior, тем точнее совпадают значения, поскольку он “внимательней” следит за каждым шагом. Однако, когда дело доходит до тестовых данных, модель быстро теряется без привязки к реальным значениям. Поскольку рынок изменчив, нужна более гибкая модель, чем заданная по умолчанию, чтобы она могла обрабатывать как можно больше шаблонов.
Теперь, когда у нас есть представление о влиянии prior, мы можем численно оценить разные значения с помощью набора для обучения и проверки:
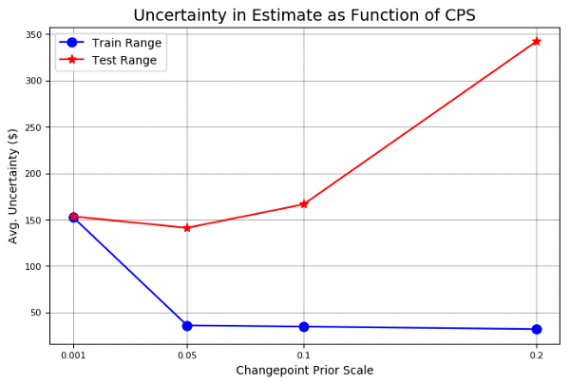
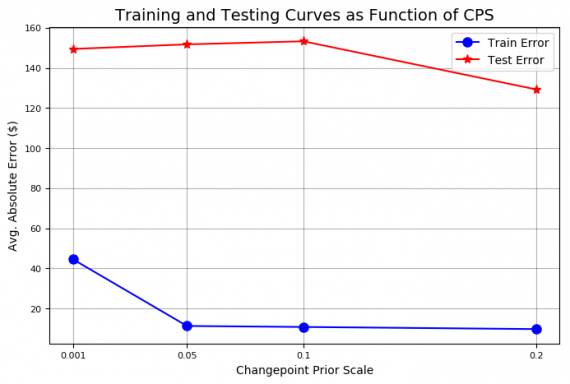
amazon.changepoint_prior_validation(start_date='2016-01-04', end_date='2017-01-03', changepoint_priors=[0.001, 0.05, 0.1, 0.2]) Validation Range 2016-01-04 to 2017-01-03. cps train_err train_range test_err test_range 0.001 44.507495 152.673436 149.443609 153.341861 0.050 11.207666 35.840138 151.735924 141.033870 0.100 10.717128 34.537544 153.260198 166.390896 0.200 9.653979 31.735506 129.227310 342.205583
Мы должны быть осторожны — данные валидации не должны совпадать с тестовой выборкой. Если бы это было так, мы бы создали модель, лучше «подготовленную» для тестовых данных, что ведет к переобучению и невозможности работать в реальных условиях. В общей сложности, как это обычно делается в машинном обучении, используются три набора: для обучения (2013-2015), для валидации (2016) и тестовый набор (2017).
Мы оценили четыре priors с четырьмя показателями:
- ошибка обучения;
- доверительный интервал при обучении;
- ошибка тестирования;
- доверительный интервал при тестировании, все значения в долларах.
На графике видно, что чем выше prior, тем ниже ошибка обучения и тем ниже неопределенность на данных для обучения. Видно, что повышение уровеня prior снижает ошибку тестирования, подкрепляя интуицию, что близко приближаться к данным — хорошая идея для рынка. В обмен на бóльшую точность в тестовом наборе получаем больший диапазон неопределенности в данных теста с увеличением prior.
Валидационная проверка Stocker выдает два графика, иллюстрирующие эти идеи:
Так как наивысшее значение prior дало самую низкую ошибку тестирования, следует увеличить prior scale еще сильнее, чтобы попытаться улучшить результаты. Поиск можно уточнить, передав дополнительные параметры методу валидации:
# test more changepoint priors on same validation range amazon.changepoint_prior_validation(start_date='2016-01-04', end_date='2017-01-03', changepoint_priors=[0.15, 0.2, 0.25,0.4, 0.5, 0.6])
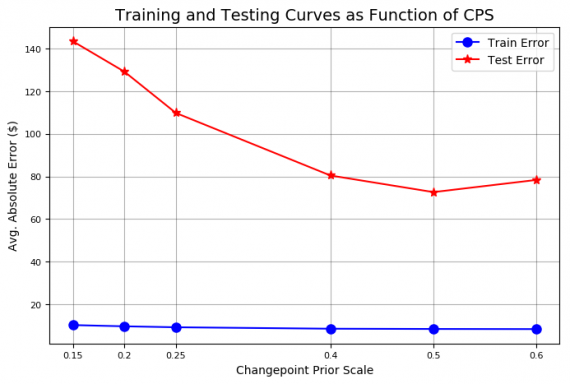
Ошибка тестового набора сводится к минимуму при prior = 0,5. Установим атрибут объекта Stocker соответствующим образом:
amazon.changepoint_prior_scale = 0.5
Есть и другие изменяемые настройки модели. Например, паттерны, которые ожидается увидеть, или количество используемых лет в обучающих данных. Поиск наилучшей комбинации требует повторения описанной выше процедуры с несколькими разными значениями. Не стесняйтесь экспериментировать!
Оценка усовершенствованной модели
Теперь, когда наша модель оптимизирована, оценим ее еще раз:
amazon.evaluate_prediction() Prediction Range: 2017-01-18 to 2018-01-18. Predicted price on 2018-01-17 = $1164.10. Actual price on 2018-01-17 = $1295.00. Average Absolute Error on Training Data = $10.22. Average Absolute Error on Testing Data = $101.19. When the model predicted an increase, the price increased 57.99% of the time. When the model predicted a decrease, the price decreased 46.25% of the time. The actual value was within the 80% confidence interval 95.20% of the time.
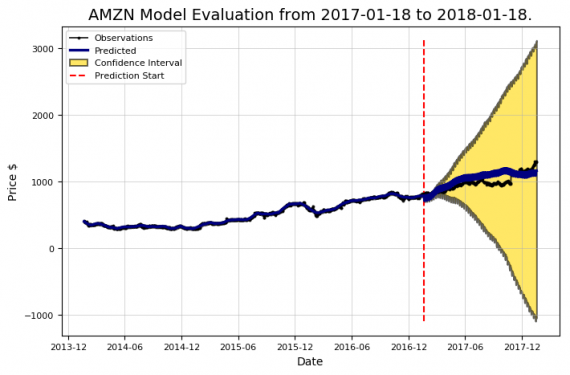
Выглядит гораздо лучше! Это показывает важность оптимизации модели. Использование значений по умолчанию дает разумное первое приближение. Но нужно быть уверенным, что используются правильные настройки, так же как мы пытаемся оптимизировать звук стерео, регулируя Balance и Fade (извините за устаревший пример).
«Входим в рынок»
Прогнозирование, безусловно, увлекательное занятие. Но настоящее удовольствие — наблюдать, как эти прогнозы будут отыгрывать на реальном рынке. Используя метод evaluate_prediction, мы можем «играть» на фондовом рынке, используя нашу модель за период оценки. Будем использовать описанную стратегию и сравним с простой стратегией buy and hold в течение всего периода.
Правила нашей стратегии просты:
- Каждый день, когда модель предсказывает рост акций, покупаем акции в начале дня и продаем в конце дня. Когда прогнозируется снижение цены, мы не покупаем акции.
- Если покупаем акции, и цены увеличиваются в течение дня, мы получаем соответствующую прибыль кратно количеству акций, которые у нас есть.
- Если покупаем акции, а цены уменьшаются, мы теряем кратно количеству акций.
Эту стратегию будем применять каждый день на весь период оценки, который в данном случае составляет весь 2017 год. Чтобы играть, нужно передать количество акций в вызов метода. Stocker покажет процесс разыгрывания стратегии в цифрах и графиках:
# Going big amazon.evaluate_prediction(nshares=1000) You played the stock market in AMZN from 2017-01-18 to 2018-01-18 with 1000 shares. When the model predicted an increase, the price increased 57.99% of the time. When the model predicted a decrease, the price decreased 46.25% of the time. The total profit using the Prophet model = $299580.00. The Buy and Hold strategy profit = $487520.00. Thanks for playing the stock market!
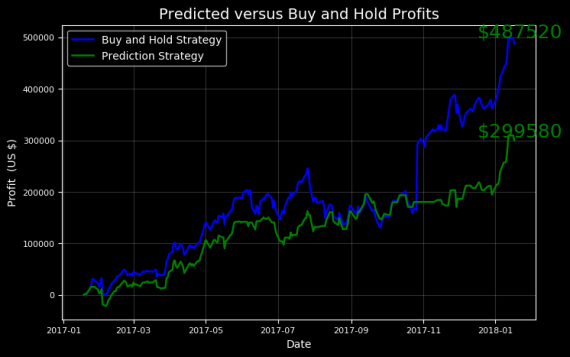
Мы получили ценный урок: покупайте и удерживайте! Несмотря на то, что удалось выручить значительную сумму, играя по нашей стратегии, лучше просто инвестировать и держать акции.
Попробуем другие тестовые периоды, чтобы увидеть, есть ли случаи, когда наша модельная стратегия превосходит метод buy and hold. Описанный подход довольно консервативен, потому что мы не играем, когда прогнозируется снижение рынка. Следовательно, когда акции начнут падать, он может работать лучше, чем стратегия buy and hold.
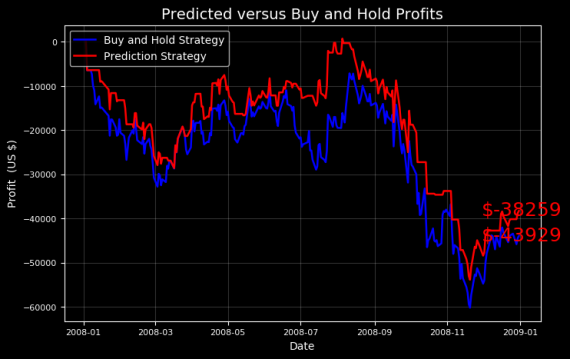
Играйте только на ненастоящих деньгах!
Я знал, что наша модель может это сделать! Тем не менее, она побила рынок только когда у нас была возможность выбрать период тестирования.
Прогнозы на будущее
Теперь, когда у нас есть достойная модель, можно делать предсказания на будущее, используя метод predict_future():
amazon.predict_future(days=10) amazon.predict_future(days=100)
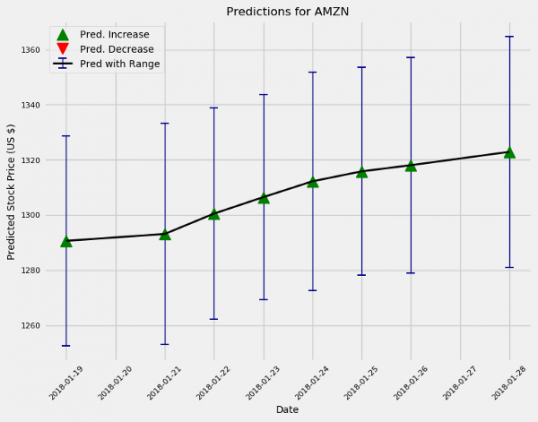
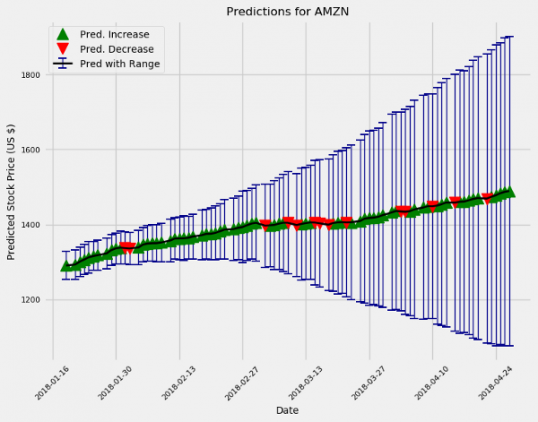
Модель в целом смотрит на Amazon с оптимизмом, как и большинство «профессионалов».
Неопределенность увеличивается с течением времени, как и ожидается. В действительности, если бы мы использовали описанный подход для настоящей торговли, мы бы каждый день обучали новую модель и делали прогнозы на срок не более одного дня.
Всем, кто хочет опробовать код, или поэкспериментировать со Stocker, добро пожаловать на GitHub.
Автор статьи в Twitter @koehrsen_will.




Привет! Слушай, а что делать, если максимальная дата — 2019 г. ???