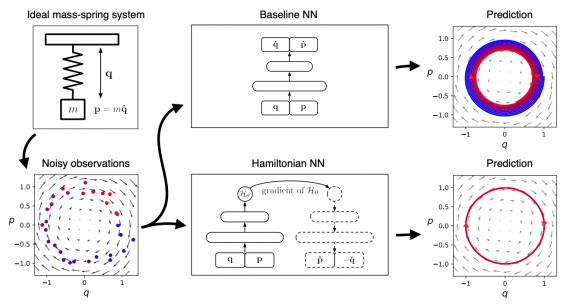
Первая статья в серии, посвященной объяснению того, как Uber использует прогнозирование для улучшения своих продуктов. В дополнение к стандартным статистическим алгоритмам Uber строит прогнозы с использованием трех методов: машинное обучение, глубокое обучение и вероятностное программирование.
Прогнозирование
Прогнозирование используется повсеместно. В дополнение к стратегическим прогнозам, таким как прогнозирование доходов, производства и расходов, организациям в разных отраслях промышленности нужны точные краткосрочные тактические прогнозы, такие как количество заказанных товаров и необходимое количество сотрудников, чтобы идти в ногу с их ростом.
Неудивительно, что Убер применяет прогнозирование для разных целей, в том числе:
- Прогнозирование рынка: критический элемент приложения, который позволяет нам прогнозировать потребительский спрос в виде маленьких гранул в пространственно-временном режиме, чтобы направлять партнеров-водителей в районы повышенного спроса до их возникновения, тем самым увеличивая количество поездок и доходы. Пространственно-временные прогнозы по-прежнему остаются открытой областью для исследования.
- Планирование расходов на ПО: малые расходы могут привести к сбоям в работе ПО, которые могут подорвать доверие пользователей, но чрезмерные расходы могут оказаться очень дорогостоящими. Прогнозирование поможет найти золотую середину: не слишком много и не слишком мало.
- Маркетинг: контролируя тенденции, сезонность и другую динамику (например, конкуренцию или ценообразование), крайне важно знать предельную эффективность различных медиаканалов. Мы используем передовые методологии прогнозирования, чтобы строить более надежные оценки и принимать основанные на данных маркетинговые решения в широких масштабах.
Что делает прогнозирование (в Uber) сложной задачей?
Uber работает в реальном, физическом мире с его изменчивыми факторами, такими как поведение и интересы людей, физические ограничения и непредсказуемость. Физические ограничения, например, географическое расстояние и пропускная способность дороги, переводят прогнозирование из временных в пространственно-временные области.
Несмотря на то что Uber является относительно молодой компанией (восемь лет), ее быстрый рост предполагает, что модели прогнозирования идут в ногу со скоростью и масштабами заказов.
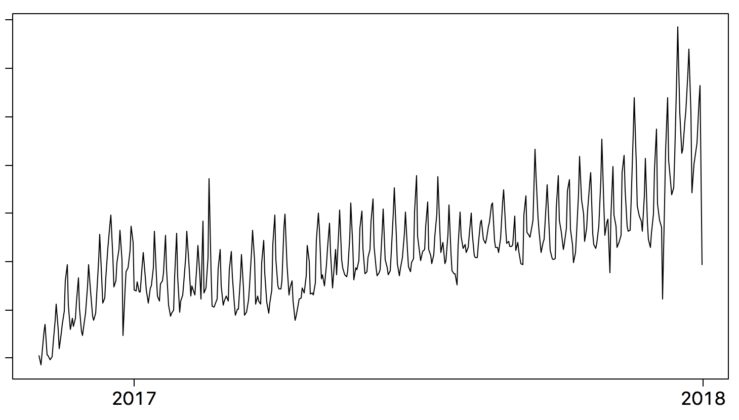
Рис. 2 демонстрирует пример данных о поездках Uber в городе за более чем 14 месяцев. Как видно, график сильно изменчив, но видна положительная тенденция и сезонность (например, декабрь часто имеет больше пиковых дат из-за большого количества праздников, разбросанных в течение месяца).
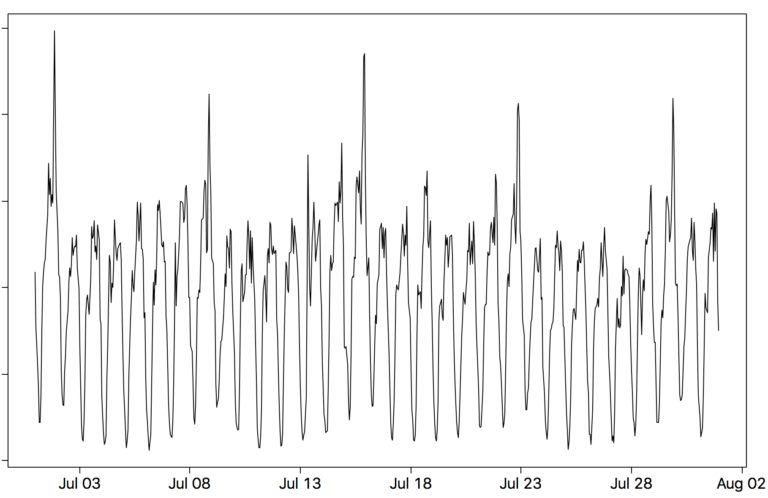
Если мы увеличим масштаб (рис. 3) и перейдем к почасовым данным за июль 2017 года, вы заметите как дневную, так и недельную (7 * 24) сезонности. В выходные водители обычно более загружены заказами.
Методологии прогнозирования должны иметь возможность моделировать такие сложные структуры.
Известные подходы к прогнозированию
Количественные методы прогнозирования можно сгруппировать следующим образом:
- базирующиеся на модели или причинные;
- статистические методы и подходы, основанные на компьютерном обучении.
Прогнозирование на основе моделей — лучший выбор, когда известен механизм проблемы, поэтому он используется во многих ситуациях в Uber. Это стандартный подход в эконометрике с ее набором моделей, следующих за различными теориями.
Когда лежащие в основе механизмы неизвестны или слишком сложны для понимания, как на фондовом рынке, или известны не полностью (розничные продажи), обычно лучше применять простую статистическую модель. Популярными классическими методам, относящимися к этой категории, являются ARIMA (авторегрессионное интегрированное скользящее среднее), методы экспоненциального сглаживания, такие как Holt-Winters, и метод Theta, который используется менее широко, но работает очень хорошо. На самом деле, метод Theta выиграл M3 Forecasting Competition, и мы также выяснили, что он хорошо работает для динамики Uber (более того, он дешевле для вычислений).
В последние годы подходы к компьютерному обучению, в том числе леса с квантильной регрессией (QRF), кузена известного случайного леса (Random forest), стали частью инструментария прогнозиста. Было показано, что рекуррентные нейронные сети (RNN) очень полезны, если в наличии достаточно данных, особенно экзогенных регрессоров. Как правило, эти модели машинного обучения имеют тип черного ящика и используются, когда не требуется интерпретируемость. Ниже мы предлагаем общий обзор популярных методов прогнозирования классического и машинного обучения.
Классические статистичекие методы:
- Авторегрессионное интегрированное скользящее среднее — ARIMA
- Методы экспоненциального сглаживания — Holt-Winters
- Theta
Методы машинного обучения:
- Рекуррентные нейронные сети (RNN)
- Леса с квантильной регрессией (QRF)
- Gradient boosting trees (GBM)
- Метод опорных веркторов (SVR)
- Распределение гауссовского процесса (GP)
Интересно отметить, что победивший на конкурсе проект прогнозирования M4 был гибридной моделью, которая включала как закодированные вручную формулы сглаживания, основанные на хорошо известном методе Холта-Уинтерса, так и стек расширенной долгой краткосрочной памяти (LSTM).
На практике классические и ML-методы не отличаются друг от друга, но одни из них более простые и интерпретируемые, а другие более сложные и гибкие. Классические статистические алгоритмы, как правило, считают быстрее, и они проще в использовании.
В Uber выбор правильного метода прогнозирования для данного варианта — это функция из многих факторов, включая количество исторических данных, если важную роль играют экзогенные переменные (например, погода, концерты и т. д.) и бизнес-потребности (например, нужно ли интерпретировать модель?). Мы не можем заранее знать, какой подход приведет к оптимальной производительности.
Сравнение методов прогнозирования
Важно проводить хронологическое тестирование, т.к порядок временных рядов имеет значение. Экспериментаторы не могут вырезать кусочек посередине и тренировать данные до и после этой части. Вместо этого им необходимо обучить набор данных, который старше данных теста.
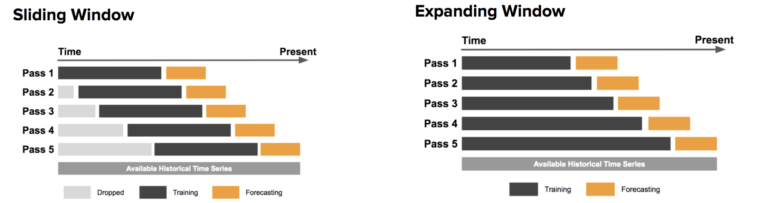
Есть два основных подхода, описанных на рисунке 4: скользящиее окном и подход расширяющегося окна. В подходе с раздвижным окном для обучения используется окно с фиксированным размером, показанное здесь черным цветом. Впоследствии этот метод тестируется в сравнении с данными, обозначенными оранжевым цветом.
С другой стороны, метод расширяющегося окна использует все больше и больше данных обучения, сохраняя при этом размер окна тестирования неизменным. Последний подход особенно полезен, если имеется ограниченный объем данных для работы.
Также возможно и даже часто полезно объединять эти два метода: начните с расширяющегося окна и когда окно станет достаточно большим, переключитесь на метод скользящего окна.
Оценка прогноза
Оценочные показатели, включая абсолютные ошибки и процентные ошибки, имеют несколько недостатков. Один особенно полезный подход — сравнить производительность модели с простым прогнозом (naive forecast). Для несезонной серии простой прогноз — это когда последнее значение считается равным следующему значению. Для периодического временного ряда прогнозная оценка равна предыдущей сезонной переменной (например, для ежечасного временного ряда с недельной периодичностью простой прогноз предполагает, что следующее значение равно значению данного часа недельной давности).
Чтобы упростить выбор подходящего метода прогнозирования для других команд в Uber, команда прогнозирования построила параллельную расширяемую бэктестинговую платформу под названием Omphalos, чтобы обеспечить быструю итерацию и сравнение методологий прогнозирования.
Важность оценки неопределенности
Определение наилучшего метода прогнозирования для заданного варианта составляет только половину уравнения. Нам также необходимо оценить интервалы предсказания. Интервалы прогнозирования представляют собой верхние и нижние значения прогноза, между которыми, как ожидается, будет с высокой вероятностью (например 0.9) располагаться действительное значение. На рисунке 5 показано, как ведут себя разные интервалы прогнозирования:
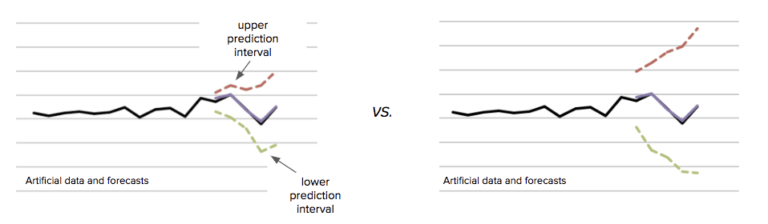
На рисунке 5 прогнозы, показанные фиолетовым цветом, совпадают. Однако интервал предсказания на левом графике значительно уже, чем на правом. Разница в интервалах прогнозирования приводит к двум очень разным прогнозам, особенно в контексте планирования производительности: второй прогноз требует значительно более высоких резервов мощности, чтобы обеспечить возможность значительного увеличения спроса.
Интервалы прогнозирования столь же важны, как и сам прогноз, и всегда должны учитываться в ваших прогнозах. Интервалы прогнозирования, как правило, зависят от того, сколько данных у нас есть, сколько вариаций в этих данных, насколько далеко мы прогнозируем и какой подход используется.
Движение вперед
Прогнозирование играет огромную роль в создании технологичных продуктов, улучшении пользовательского опыта и обеспечении будущего успеха глобального бизнеса. В будущих статьях мы рассмотрим технические детали этих проблем и решения, которые придумали разработчики Uber. Следующая статья в этой серии будет посвящена предварительной обработке данных, часто недооцененной, но крайне важной задачи.