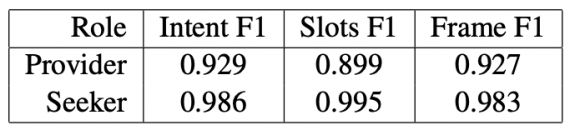
Исследователи из UberAI обучили двух агентов участвовать в диалоге. Роли в диалоге делились на ищущего и информатора. Для каждого агента обучили модель для понимания языка (NLU) и модель для генерации текста. Это первый случай, когда RL-агенты взаимодействуют в диалоге через полностью сгенерированный текст.
Для обучения моделей был использован датасет для диалоговых систем DSTC2. Взаимодействие моделировалось как стохастическая коллаборативная игра, где каждый агент имеет роль (например, ассистент, турист, посетитель) и свои целевые функции. Каждый из агентов мог взаимодействовать с другими агентами только через сгенерированный текст. Это позволило агентам учиться оптимально использовать язык. По результатам экспериментов, агенты в стохастической игры обходят supervised нейросетевые подходы. Эмпирическое сравнение показывает, что мультиагентная система выдает более реалистичные диалоги, чем системы с одним агентом.

Архитектура системы
Система была обучена на данных DSTC2, который содержит в себе информацию о ресторанах Кембриджа. Несмотря на это, мультиагентная система поддерживает любую область, которая предполагает поиск информации (information-seeking). Модели для понимания языка и генерации обучаются офлайн, в то время как агенты обучаются онлайн.
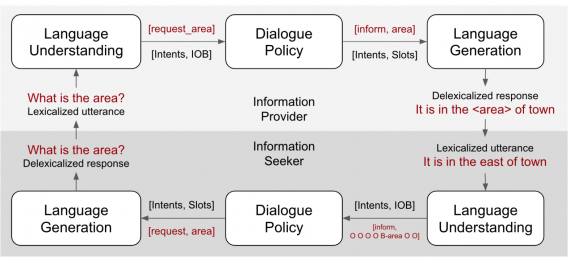
NLU модель
Модель состоит из сверточного кодировщика и двух декодировщиков: один классификатор намерений, а второй присваивает тег к запрашиваемой информации. NLU модель обучается end-to-end, и оба декодировщика оптимизируются одновременно. Исследователи использовали одну и ту же NLU модель для обоих ролей агентов.
Модель для генерации языка
Для генерации языка была использована модель с кодировщиком-декодировщиком и несколько LSTM. В этой модели использовался механизм внимания. Чтобы улучшить модель, исследователи добавили вектор с контекстом истории диалога к закодированному входу для генератора.
Оценка работы моделей
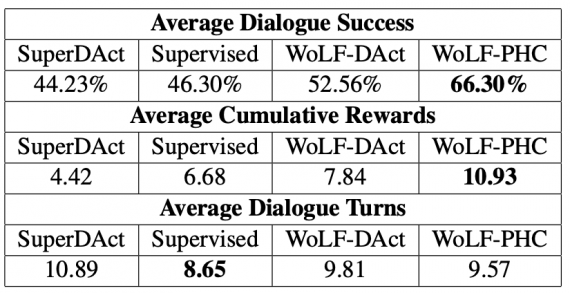
Исследователи измерили средний успех диалогов, награду и количество обращений агентов друг к другу, пока диалог не завершится. Ниже видно, что самый высокий средний успех диалогов составил 66%.