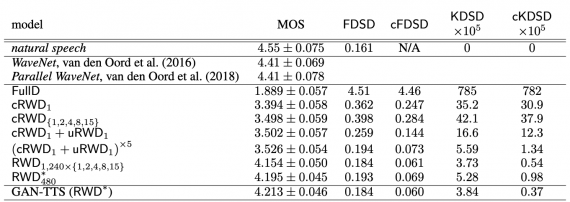
GAN-TTS — это генеративная модель для задачи преобразования текста в речь. Архитектура модели состоит из условного feed-forward генератора и ансамбля дискриминаторов. Дискриминаторы оценивают сгенерированную аудиозапись на случайных окнах разного размера. Дискриминаторы анализируют речь с точки зрения реалистичности и того, насколько верно произносится входной текст. Исследователи вводят две количественные метрики для оценки качества сгенерированной речи: Frechet DeepSpeech Distance и Kernel DeepSpeech Distance. Прослушать, как нейросеть озвучивает текст абстракта исследования можно по ссылке.
Прошлое применение генеративных состязательных моделей для задачи генерации аудио было ограничено. Авторегрессионные модели, как WaveNet, оставались state-of-the-art для моделирования человеческой речи. GAN-TTS демонстирует, как GAN справляется с задачей text-to-speech. Чтобы измерить работу модели, исследователи используют субъективную оценку добровольцев и собственные количественные метрики. Введенные количестве метрики кореллируют с человеческой оценкой.
Ключевые преимущества модели — генерация более правдоподобной речи по сравнению с state-of-the-art и способность к параллелизации благодаря структуре генератора. Авторегрессионные модели, которые часто используются для задач генерации речи, менее параллелизуемы.
Некоторые дискриминаторы принимают во внимание лингвистические характеристики сгенерированной речи, чтобы оценить, насколько речь соответствует входному тексту. Остальные дискриминаторы фокусируются на реалистичности генерируемой речи.
Архитектура модели
Модели обучаются на датасете, который состоит из аудиозаписей человеческой речи с соответствующими лингвистическими признаками и текстом речи.
Генератор
Генератор получает на вход лингвистические и звуковые характеристики. На выходе генератор отдает аудиосигнал на 24 килогерц. Генератор состоит из 7 блоков, каждый из которых — это два остаточных блока. Исследователи используют расширенные сверточные слои, чтобы модель могла выучивать долгосрочные зависимости.
Финальный сверточный слой с тангенсом в качестве функции активации производит одноканальный аудиосигнал.
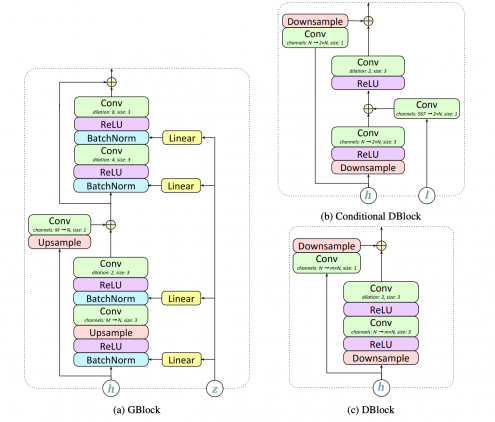
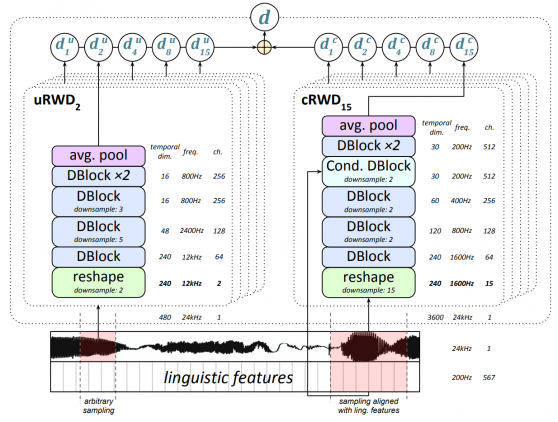
Дискриминатор
Дискриминатор состоит из блоков, которые схожи с блоками в генераторе, но без батч-нормализации. Архитектура условного блока и стандартного блока показана выше на изображении (b и c). Единственное отличие условного блока от стандартного — дополнительный эмбеддинг лингвистических характеристик добавляется к первому сверточному слою. Дискриминатор применяется к случайным маленьким окнам сгенерированного аудио.
Оценка результатов модели
Исследователи проверили, какие части модели вносят больший вклад в качество предсказаний. Помимо этого, они сравнили полную версию модели с стандартной WaveNet и ее параллелизованной версией. Ниже видно, что GAN-TTS выдает сравнимые с state-of-the-art результаты.