Google опубликовали end-to-end модель, которая распознает речь на разных языках end-to-end. Разработчики использовали модель для малопредставленных языков, которым не хватает данных для обучения. Нейросеть обучалась на аудиозаписях 9 индийских языков. Для 8 из 9 языков модель обходит предыдущие решения. В основе нейросети использовалась архитектура RNN-T.
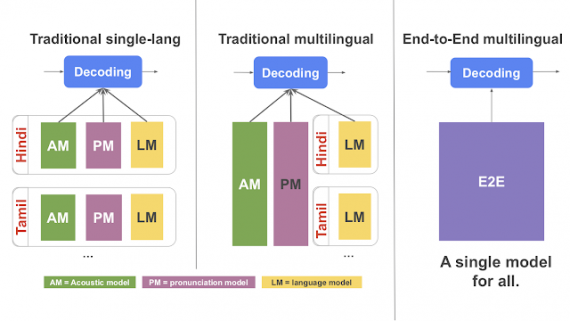
Цель исследования заключалась в том, чтобы качество распознавания речи было сопоставимым для популярных языков и для малопредставленных. Поэтому разработчики использовали мультилингвальную модель. Такая модель позволяет использовать знания, полученные при обучении на данных популярного языка, при распознавании малопредставленного. Используя данные индийских языков, модель значительно улучшила предсказания для некоторых малопредставленных языков и для популярных языков.
Мультилингвальная модель
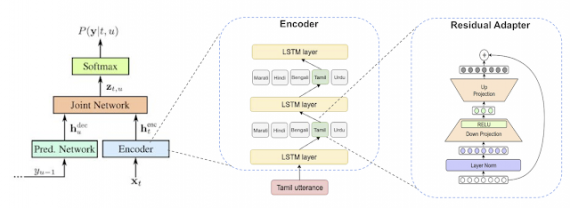
Традиционно системы по распознаванию речи содержат отдельные компоненты для моделей, которые выучивают звуки, язык и произношение. Ранее были попытки сделать традиционные системы мультилингвальными. Однако такие подходы сложно масштабировать. End-to-end модель (E2E) объединяет три компонента из стандартных систем в одну нейросеть. Прошлые решения для E2E моделей распознавания речи не адаптированы для распознавания речи в реальном времени. Чтобы решить проблему с распознаванием в реальном времени, исследователи использовали архитектуру Recurrent Neural Network Transducer (RNN-T). RNN-T модель выдает предсказание посимвольно. Однако модель в ее стандартной формулировке не мультилингвальна. Поэтому исследователи модифицировали стандартную RNN-T.
Смещения модели
Аудиозаписи разных языков в выборки не были равно представлены. Мультилингвальная модель может быть смещена в сторону языков, которые лучше представлены в обучающей выборке, когда выдает предсказания. Это смещение особенно характерно для E2E модели, потому что у модели нет доступа к дополнительным текстовым данным, который был у стандартных моделей. Из-за того что модель сама выучивает лексические характеристики языков из обучающей выборки, чем больше модель получает данных об одном языке, тем больше знаний об этом языке она имеет.
Чтобы минимизировать такие смещения, исследователи внедрили в архитектуру модели следующие изменения:
- Дополнительный вход модели (например, предпочитаемый язык из настроек пользователя), которые добавляется к входной аудиозаписи как one-hot вектор;
- Добавили residual adapter modules, чтобы подгонять глобальную модель под отдельные языки