NVIDIA Canary достигла 90% точности предсказания временных меток в синхронном переводе
28 мая 2025

NVIDIA Canary достигла 90% точности предсказания временных меток в синхронном переводе
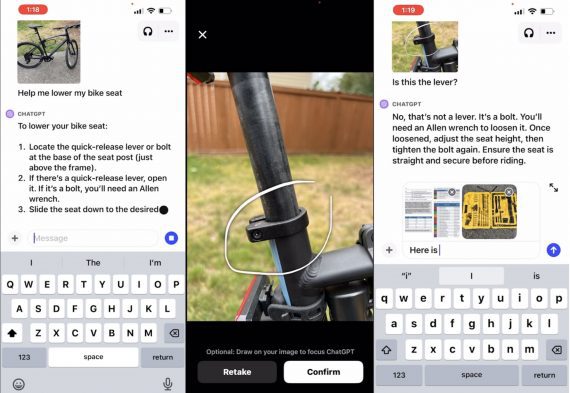
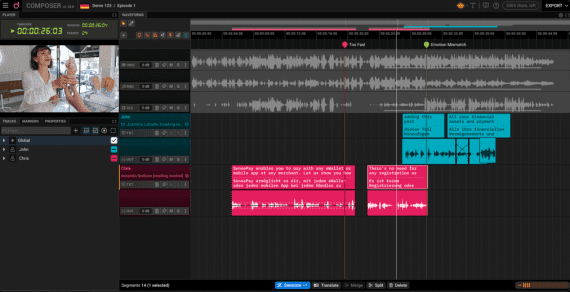
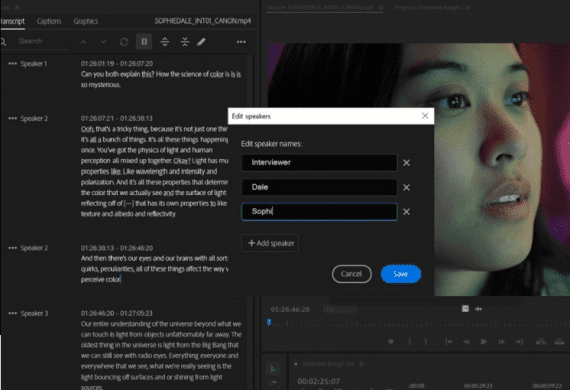
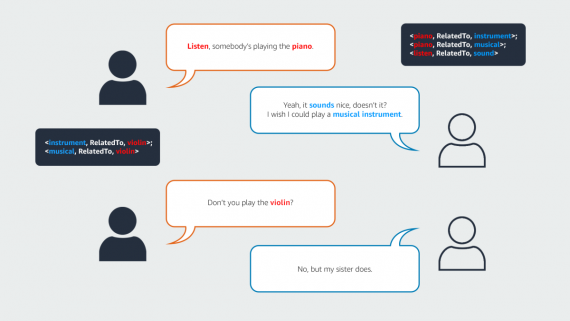
Исследовательская команда NVIDIA представила подход для генерации временных меток на уровне слов в модели синхронного перевода Canary. Точная информация о времени критически важна для создания синхронизированных субтитров. Исследователи опубликовали код…