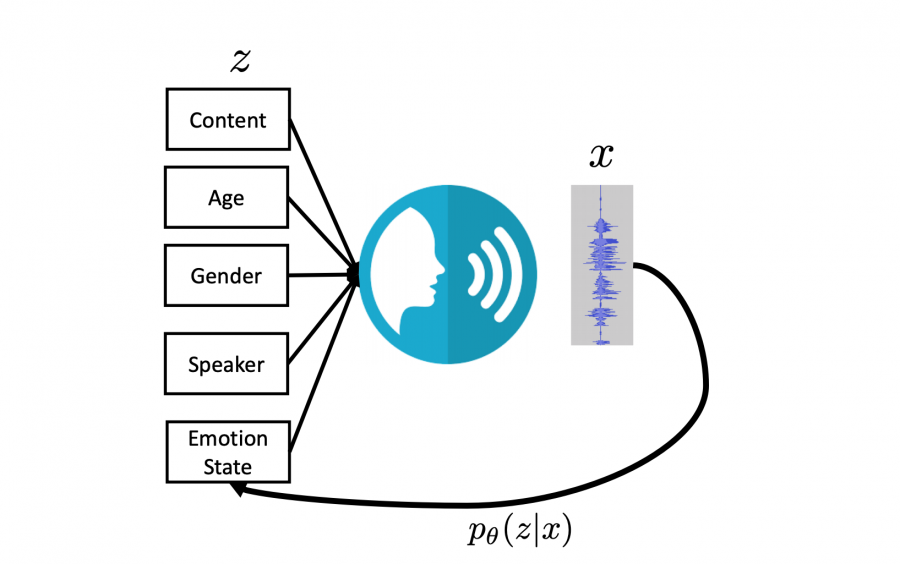
Разработчики из Alexa Research в Amazon опубликовали описание модели, которая распознает эмоции по интонации голоса человека. В качестве модели разработчики использовали автокодировщик, который позволяет обучаться на неразмеченных данных.
Обычно классификация эмоций производится с помощью нейросети, которую обучили с учителем на размеченных данных. Нейросеть учится предсказывать класс на основе тех данных в обучающей выборке, которые приписаны к данному классу. Предложенная модель использует состязазательное обучение и состоит из кодировщика-декодировщика.
Архитектура автокодировщика
Процесс обучения делится на три этапа:
- Сначала кодировщик и декодировщик обучаются на неразмеченных данных;
- Используется состязательное обучение (дискриминатор), чтобы улучшить точность кодировщика;
- Кодировщик затачивается под задачу перевода из представления эмоции в класс эмоции
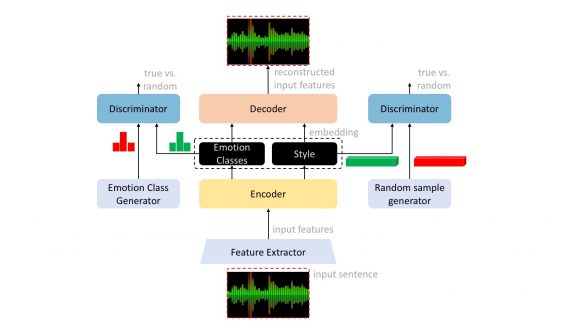
Скрытое представление данных делится на тип эмоции и стиль. Эти данные поступают в два состязательных дискриминатора. Дискриминатор — это нейросеть, которая учится отличать реальные данные из кодировщика от сгенерированных.
Модель обучалась на публичном датасете, который содержит 10,000 высказываний от 10 разных спикеров. Эти высказывания размечены в соответствии с характеристиками интонации: валентность, активация и доминация:
- Валентность, которая отвечает за позитивность/негативность эмоции говорящего;
- Активация, которая отвечает за то, вовлечен ли говорящий в разговор или пассивен;
- Доминация, которая отвечает за то, контролирует свою речь говорящий или нет
Исследователи отметили трюки, которые помогли успешно обучить автокодировщик:
- Нормализация батчей;
- Регуляризация для дискриминатора;
- Установление дропаута 0.5 для слоев дискриминатора;
- Learning rate генератора был выше, чем learning rate дискриминаторов
Оценка работы модели
Разработчики сравнили работу модели с конвенциональными методами обучения с учителем. Предложенный подход был на 3% более точный в определении валентности, чем конвенциональный подход.
Отдельно рассматривался случай, когда на вход нейросети поступала последовательность векторов, описывающих аудио характеристики двадцатисекундных нарезок. Нейросеть давала прирост в точности 4%.