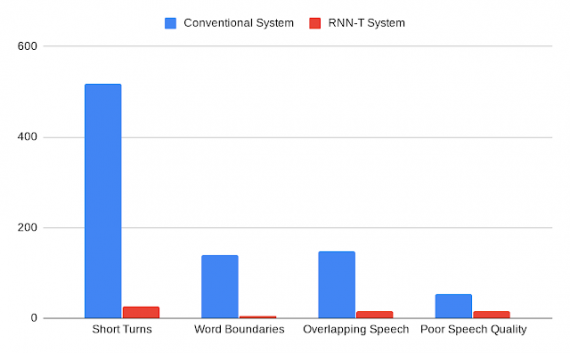
Разработчики в Google AI опубликовали нейросетевую модель, которая распознает спикеров на аудиозаписи. Нейросеть была протестирована на задаче распознавания аудиозаписей медицинских обследований. В сравнении с state-of-the-art моделью предложенный подход сокращает процент ошибок с 15.8% до 2.2%.
Задача распознавания разных голосов на аудиозаписи называется speaker diarization (SD). Решение этой задачи значительно может значительно повлиять на качество и последовательность виртуальных ассистентов и на приложения задачи преобразования из аудио в текст.
Стандартно модели, которые решают SD задачу, делятся на два этапа. Первый этап — распознавание момента смены спикера в аудиозаписи. Второй — идентификация уникальных спикеров в аудиозаписи. Базовый многошаговый подход был разработан более двух десятков лет назад. За это время улучшилось качество предсказания только у модели на первом шаге.
С разработкой рекуррентного нейросетевого датчика (RNN-T) появилась устойчивая архитектура, которую можно применить для задачи распознавания спикеров. RNN-T решает проблему с ограничениями базового подхода. В работе исследователи адаптировали стандартную RNN-T под задачу распознавания спикеров.
Как это работает
Нейросеть комбинирует в себе распознавание звуковых и языковых сигналов. Это позволяет распознавать текст речи и принадлежность речи в одной системе. Модель основана на RNN-T.
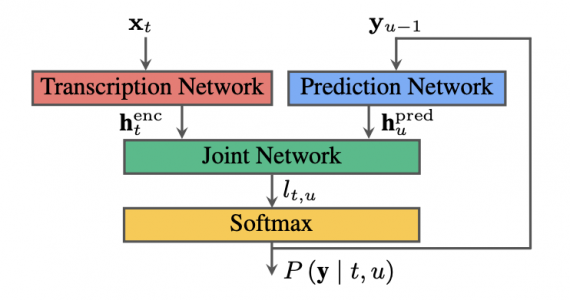
RNN-T архитектура делится на три разные нейросети:
- кодировщик, который соотносит части аудиозаписи с скрытыми представлениями;
- предсказатель, который предсказывает следующее слово, имея информацию о предыдущих предсказаниях;
- совместная нейросеть, которая комбинирует выходы из предыдущих двух нейросетей и для каждой части аудио генерирует вероятностное распределение из существующих классов
Сравнение с базовой моделью
Ниже можно заметить, что нейросеть, которая базируется на RNN-T, реже совершает ошибки в предсказаниях, чем стандартная модель.