AutoKeras: библиотека для автоматизированного подбора архитектуры
30 сентября 2019

AutoKeras: библиотека для автоматизированного подбора архитектуры
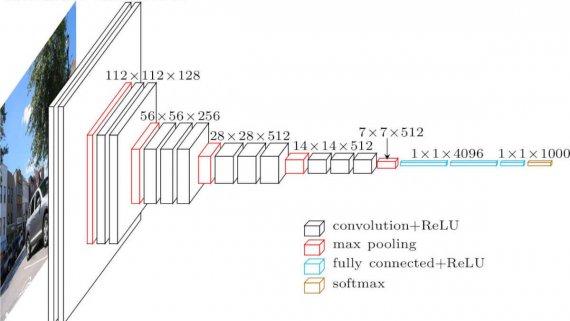
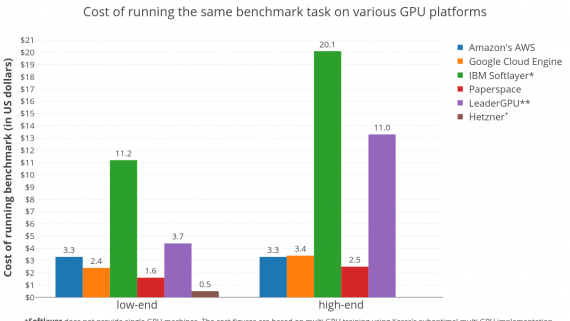
Auto-Keras — это открытая библиотека для автоматизированного поиска архитектуры модели (AutoML). Библиотека позволяет вычисления параллельно на CPU и GPU и адаптируется под лимиты памяти. Разработчики предлагают новый метод для подбора…