Результаты тестов популярных GPU для машинного обучения: Amazon AWS, Google Cloud Engine, Hetzner, Leader GPU, IBM, Paperspace.
Читайте также: Глубокое обучение в облаке: полный список GPU провайдеров
Тестируемые GPU платформы
В этот тест включены: Amazon Web Services AWS EC2, Google Cloud Engine GCE, IBM Softlayer, Hetzner, Paperspace and LeaderGPU.
Поскольку многие современные задачи машинного обучения используют графические процессоры, понимание компромиссов по стоимости и производительности различных поставщиков GPU становится решающим.
Я хотел бы поблагодарить провайдеров GPU для машинного обучения за любезное предоставление нам тестовых кредитов и отличную поддержку в течение всего моего тестирования. Каждая платформа имеет свои собственные плюсы и минусы, а рынок GPUaaS — очень интересное и оживленное пространство.
Отмечу что, единственный крупный провайдер, который не отвечал, на самом деле у нас не было ответа даже по официальным каналам поддержки, был Microsoft Azure. Сделайте свои собственные выводы.
Мы рассмотрим два типа графических процессоров на основе цен инстансов на каждой платформе — «low-end» и «high-end» (см. Таблицу 1). Цель состоит в том, чтобы показать, стоят ли дорогие инстансы своих денег.
Настройка Benchmark для машинного обучения
Постановка задачи
В RARE Technologies, мы часто занимаемся проблемами обработки естественного языка (NLP), поэтому я остановился на задаче классификации настроений для бенчмарка. Двунаправленная сеть долгой краткосрочной памяти (LSTM) обучается выполнять двоичную категоризацию твитов. Выбор алгоритма не очень важен; моим единственным истинным требованием для этого бенчмарка является то, что он должен загружать GPU. Чтобы обеспечить максимальное использование графического процессора, я воспользовался быстрой реализацией LSTM Keras (v2.1.3), поддерживаемой CuDNN — слоем CuDNNLSM.
Набор данных
В качестве набора данных мы взяли Twitter Sentiment Analysis Dataset, содержащий 1 578 627 классифицированных твитов, каждая строка помечена 1 для положительной тональности и 0 для отрицательной тональности. Модель обучается в течение 4 эпох на 90% перемешанных данных, а оставшиеся удерживаемые 10% используются для оценки модели.
Docker
В целях воспроизводимости я создал Nvidia Docker image, который содержит все зависимости и данные, необходимые для повторного запуска этого бенчмарка . Dockerfile и весь необходимый код можно найти в этом архиве Github.
Мы публикуем настройки и код в полном объеме, не только для того, чтобы каждый мог воспроизвести эти результаты, но так же чтобы вы могли подключить свою собственную HW платформу или другой алгоритм выбора, чтобы сделать свой собственный бенчмарк.
Результаты
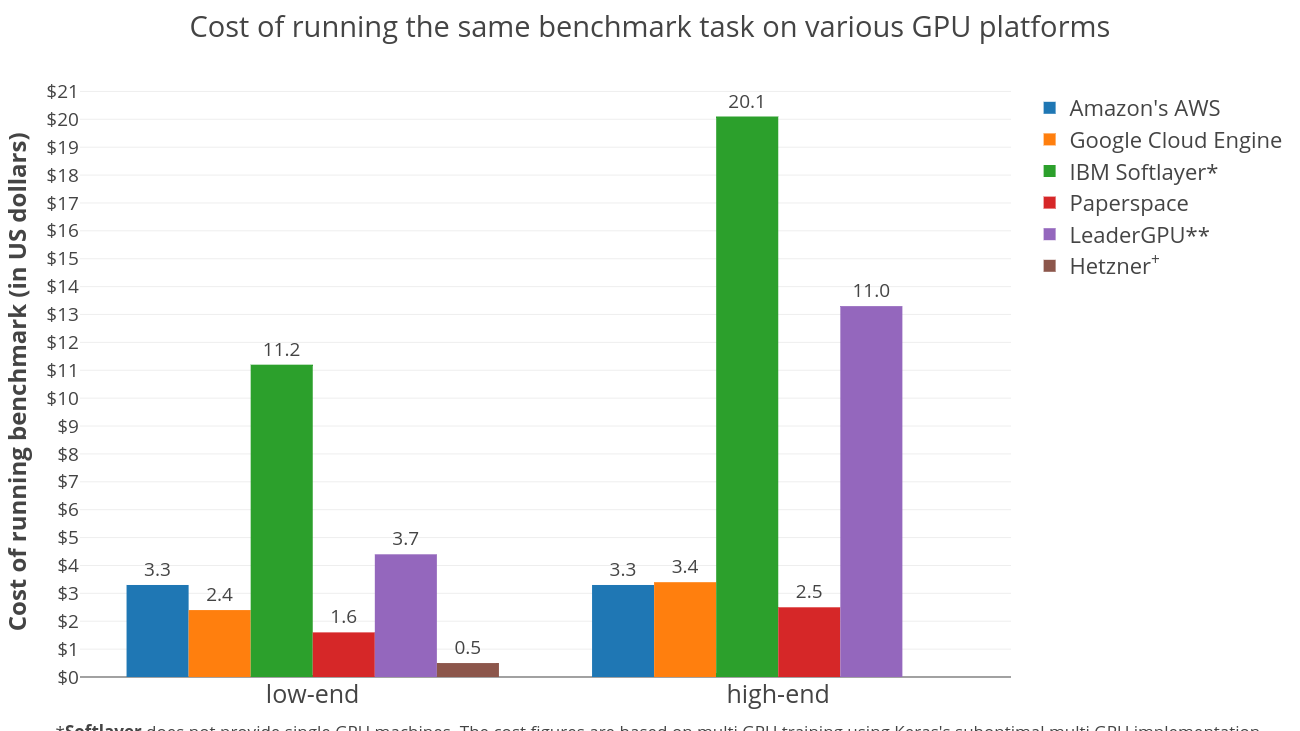
* Это multiple GPU инстансы, в которых модели прошли обучение на всех графических процессорах с использованием функции multi_gpu_model, которая позже была признана не оптимальной при использовании нескольких графических процессоров.
** Это multiple GPU инстансы, в которых модели прошли обучение с использованием только одного из своих графических процессоров из-за вышеуказанных причин.
+ Hetzner предоставляет выделенные серверы ежемесячно. Цифры здесь отражают почасовые пропорциональные затраты.
Простота заказа, настройки и удобство пользования
Заказать инстанс на LeaderGPU и Paperspace было проще простого без каких-либо сложных настроек. Время предоставления ресурсов для Paperspace и LeaderGPU было порядка пары минут, по сравнению с AWS или GCE, которые предоставили в течение нескольких секунд.
LeaderGPU, Amazon и Paperspace предлагают в свободном доступе Deep Learning Machine Images, которые идут в комплекте с предустановленными драйверами Nvidia вместе со средой разработки Python, и Nvidia-Docker необходим полностью для немедленного начала экспериментов. Для облегчения жизни, особенно для начинающих пользователей, которые просто хотят экспериментировать с моделями машинного обучения, я настроил все с нуля (за исключением LeaderGPU) по старым правилам, чтобы оценить легкость настройки экземпляра по индивидуальным потребностям. В этом процессе я столкнулся с несколькими проблемами, присущими всем платформам, такими как несовместимость драйвера NVIDIA с установленной версией gcc или использование GPU, достигающее 100% после установки драйвера без каких-либо доказательств текущего процесса. Неожиданно, запуск моего Docker на low-end инстансе Paperspace (P6000) привел к ошибке. Эта проблема была вызвана тем, что Tensorflow on Docker строился из источника с оптимизацией ЦП (MSSE, MAVX, MFMA), который Paperspace инстанс не поддерживал. Запуск Docker без этих оптимизаций исправил ошибку.
Что касается стабильности, я не сталкивался с какой-либо проблемой с любой из платформ.
Стоимость
Неудивительно, что выделенные серверы — лучший вариант, чтобы держать расходы под контролем. Это объясняется тем, что Hetzner ежемесячно взимает плату, что приводит к чрезвычайно низким почасовым ценам. На рисунке показаны пропорциональные затраты. Конечно, это справедливо только в том случае, если у вас необходимое количество задач, чтобы сервер был достаточно занят. Среди поставщиков виртуальных инстансов Paperspace является явным победителем. В два раза дешевле обучать модель на Paperspace, чем на AWS в сегменте низкопроизводительных графических процессоров. Кроме того, Paperspace демонстрирует аналогичную экономическую эффективность в классе высокопроизводительных графических процессоров.
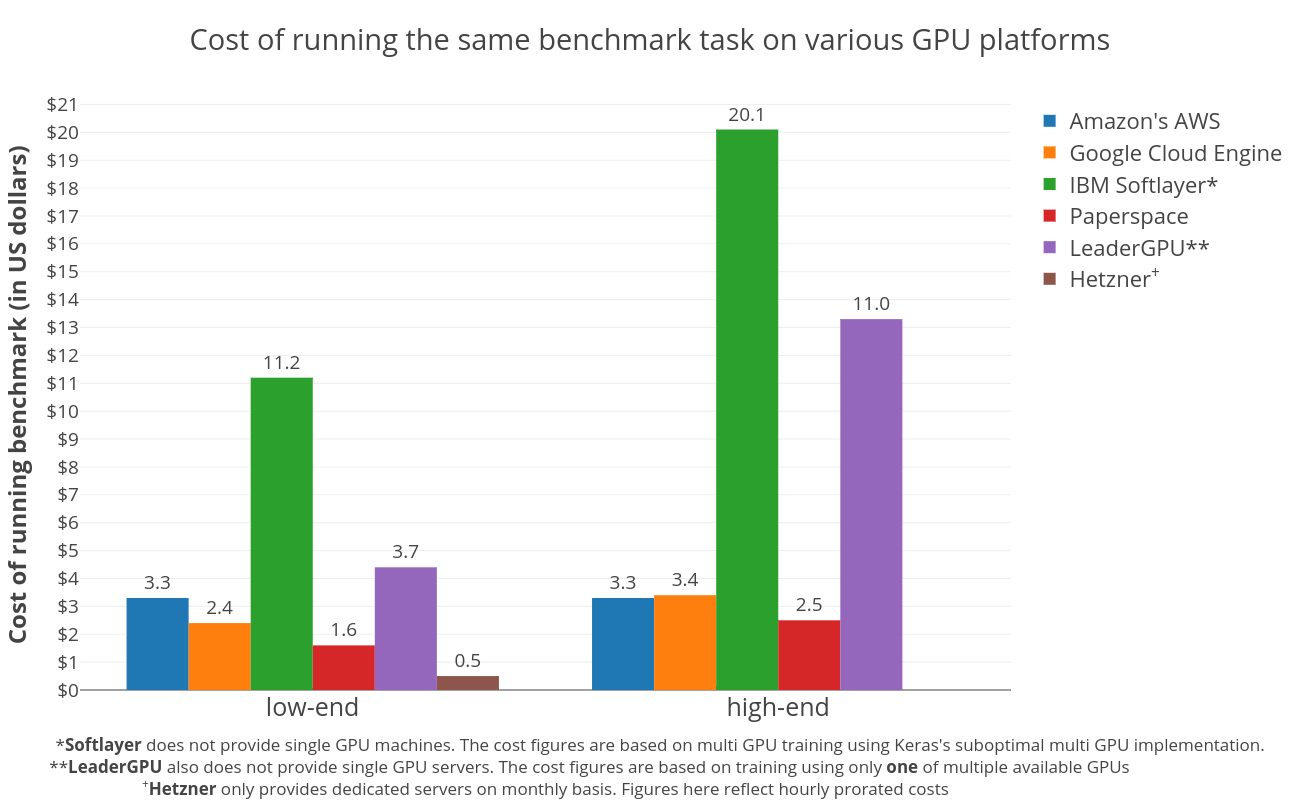
Между AWS и GCE, похоже, происходит изменение тенденции при переходе с графических процессоров с низким уровнем производительности к высокому уровню. GCE значительно дешевле, чем AWS в классе графических процессоров с низким уровнем, и он немного дороже, чем AWS в классе графических процессоров с высокой производительностью. Это говорит о том, что дорогостоящие графические процессоры AWS могут стоить дополнительных затрат.
IBM Softlayer и LeaderGPU кажутся дорогими, в основном из-за недостаточного использования инстансов с несколькими GPU. Benchmark был выполнен с использованием фреймворка Keras, реализация которого на нескольких GPU была неожиданно неэффективной, иногда хуже, чем работа одного графического процессора на том же компьютере. Но ни одна из этих платформ не предлагает single GPU инстанс. Бенчмарк проводимый на Softlayer использовал все доступные графические процессоры, использующие multi_gpu_model, тогда как на LeaderGPU использовался только один из доступных графических процессоров. Это привело к значительным дополнительным расходам для недостаточно используемых ресурсов. Кроме того, LeaderGPU предоставляет более мощные графические процессоры, GTX 1080 Ti & Tesla V100, по тем же ценам за минуту, что и GTX 1080 и Tesla P100 соответственно. Запуск на этих серверах определенно снизил бы общие затраты. Принимая во внимание все это, стоимость low-end LeaderGPU вполне разумна. Имейте это в виду, особенно если вы планируете использовать не Keras фреймворк, который лучше использует несколько графических процессоров.
Также существует другая общая тенденция: более дешевые графические процессоры обеспечивают лучшее соотношение цена / производительность, чем более дорогие графические процессоры, что указывает на то, что сокращение времени обучения не компенсирует увеличение общей стоимости.
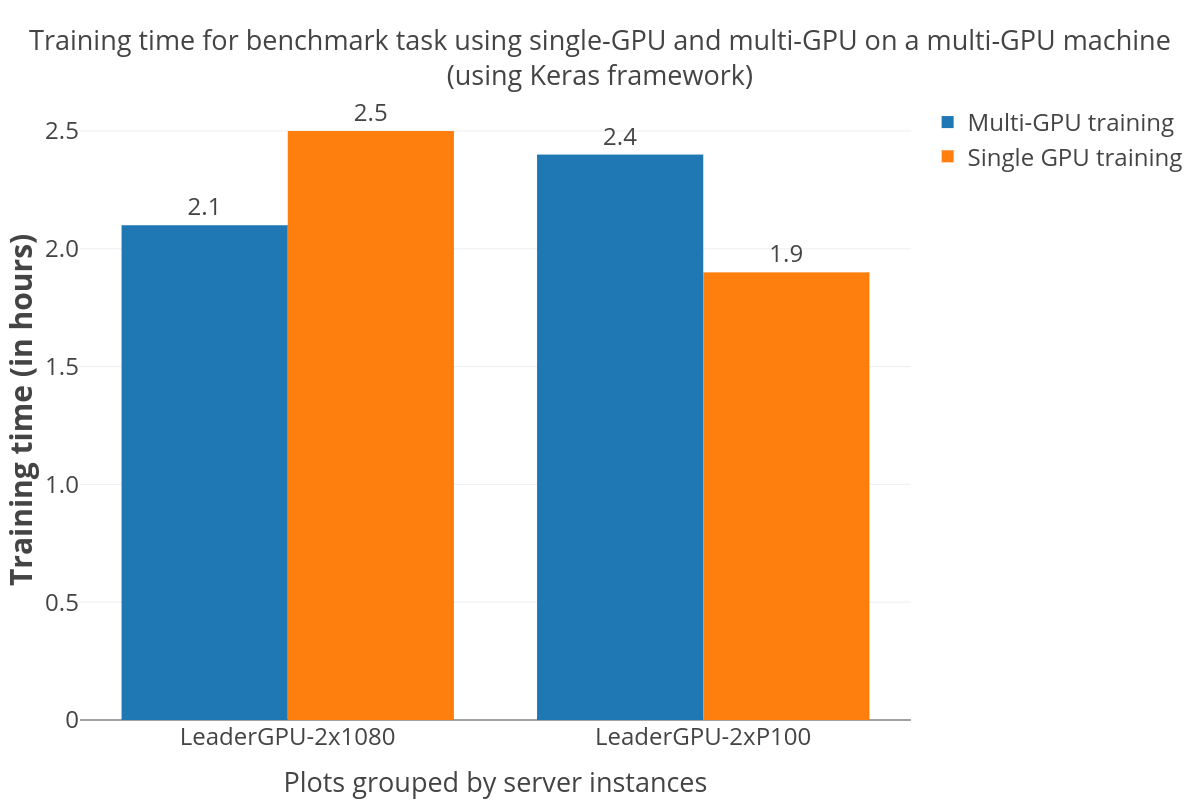
Замечание по подготовке обучающих мульти-графических моделей с использованием Keras
Огромному количеству людей в академических кругах и промышленности очень удобно использовать высокоуровневые API, такие как Keras для моделей глубокого обучения. Благодаря одной из наиболее приемлемых и активно разработанных систем глубокого обучения пользователи ожидают ускорения при переключении на многопроцессорную модель без какой-либо дополнительной обработки. Но это, конечно, не так, как видно из графика ниже. Ускорение довольно непредсказуемо. На графике видно, что на сервере «dual GTX 1080» скорость обучения выше, в то время как обучение с multi-GPU заняло больше времени, по сравнению с обучением на single-GPU на сервере «Dual P100». Такое же мнение отражено в других статьях и вопросах на Github , с которыми я столкнулся, исследуя стоимостью.
Точность модели
Для проверки работоспособности мы проверили окончательную точность модели в конце обучения. Как видно из таблицы 1, существенных различий не было, что подтверждает, что базовое оборудование / платформа не влияет на качество обучения и что бенчмарк был правильно настроен.
Стоимость
Цены на графические процессоры часто меняются, но на данный момент AWS предоставляет графические процессоры K80, начиная с $0,9 в час, которые выставляются с шагом в одну секунду, тогда как более мощные и эффективные графические процессоры Tesla V100 стоят от $3,06 в час. Дополнительные услуги, такие как передача данных, Elastic IP адреса и оптимизированные инстансы EBS, предоставляются за дополнительную плату. GCE — экономичная альтернатива, которая предоставляет Tesla K80 и P100 по запросу, начиная с $0,45 в час и $1,46 в час. Они тарифицируются с шагом в одну секунду и предлагают значительные льготы через скидки на их использование.
Paperspace конкурирует с GCE в низкой ценовой категории со ставками для выделенных графических процессоров, начиная с Quadro M4000 по цене $0,4 в час до Tesla V100 по цене $2,3 в час. Помимо обычных почасовых сборов, они также взимают ежемесячную абонентскую плату в размере $5, включающая в себя хранение и обслуживание. Paperspace предоставляет дополнительные услуги за дополнительную плату. Hetzner предлагает только один выделенный сервер с GTX 1080 ежемесячно с дополнительной одноразовой настройкой.
IBM Softlayer — одна из немногих платформ на рынке, которая предоставляет bare metal GPU сервера на ежемесячной и ежечасной основе. IBM Softlayer предлагает 3 GPU сервера с Tesla M60s & K80s, начиная с $2,8 в час. Эти серверы имеют статическую конфигурацию, что означает, что их возможности настройки ограничены по сравнению с другими облачными провайдерами. Стоимость Softlayer с почасовыми надбавками будет финансово невыгодно и может оказаться более дорогостоящим для краткосрочных задач.
LeaderGPU, относительно новый участник на рынке, предоставляет выделенные серверы с широким спектром графических процессоров (P100, V100, GTX 1080, GTX 1080Ti). Пользователи могут воспользоваться ежемесячной, ежечасной или ежеминутной оплатой, которая рассчитывается по секундам. Серверы имеют от 2 до 8 графических процессоров, со стоимостью от 0,02 € до 0,08 € в минуту.
Спотовые/вытесняемые инстансы
Некоторые из платформ предоставляют значительные скидки (50% -90%) на их запасную вычислительную мощность (AWS spot instances and GCE’s preemptive instances), хотя скидки могут неожиданно закончиться или вновь появиться. Это приводит к крайне непредсказуемому времени обучения, так как нет никакой гарантии, когда инстанс снова появится. Это нормально для приложений, которые могут обрабатывать такие завершения, но многие задачи, например, time-bound projects будут плохо выполняться в таком случае, особенно если вы считаете потраченное рабочее время. Выполнение задач на Spot/Preemptive Instances требует дополнительного кода для корректного завершения и повторного запуска инстансов. (проверка / сохранение данных на постоянный диск и т.д.).
Кроме того, колебания спотовых цен (в случае AWS) могут привести к тому, что затраты будут в значительной степени зависеть от спроса на предложение мощности во время контрольного прогона. Нам потребуется несколько прогонов, чтобы усреднить затраты.
Поэтому, вы можете сэкономить деньги с помощью spot/preemptive инстансов, если вы будете осторожны. Что касается меня, то я не стал включать их в этот бенчмарк из-за этих осложнений.
Результаты тестов
- Paperspace на один шаг вперед в отношении производительности и стоимости. Это особенно верно для разовых или нечастых пользователей, которые просто хотят экспериментировать с методами глубокого обучения (аналогичный вывод в другом бенчмарке).
- Выделенные серверы (например, предоставляемые LeaderGPU) и bare metal servers, например, Hetzner подходят для пользователей, которые рассматривают долговременную работу этих ресурсов. Обратите внимание, что ваша задача прилично загружает CPU / GPU, чтобы действительно выиграть в цен
- Новые игроки, такие как Paperspace и LeaderGPU, не должны быть списаны со счетов, поскольку они могут помочь сократить основную часть затрат. Предприятия могут быть против смены провайдеров из-за связанных инерционных и коммутационных расходов, но эти небольшие платформы, безусловно, стоит рассмотреть.
- AWS и GCE могут быть потрясающими вариантами для тех, кто ищет объединение со своими другими сервисами (Amazon Rekognition, Google Cloud AI).
- Если Вы не планируете выполнять задачу, выполнение которой займет несколько дней, лучше всего выбрать lower-end single-GPU инстанс с одним графическим процессором (см. также здесь).
- Higher-End GPUs значительно быстрее, но на самом деле имеют плохую окупаемость. Вы должны выбрать их только тогда, когда короткое время обучения является приоритетней, чем затраты на оборудование.
Перевод статьи Шива Манне Machine learning mega-benchmark: GPU providers.








в Paperspace — быстрый запуск не получится… 1) требует наличия email в зарубежной зоне (mail.ru не котируется) 2) требует упакованного в Docker контейнер проекта, доступные бесплатные (тестовые) ресурсы очень скромные